概念介绍
数据状态
数据在计算机中有两种状态:
- 瞬时状态:保存在内存的程序数据,程序退出后,数据就消失了,称为瞬时状态
- 持久状态:保存在磁盘上的程序数据,程序退出后依然存在,称为程序数据的持久状态
持久化: 将程序数据在瞬时状态和持久状态之间相互转换的机制
Transient ------------------> Persistent
(瞬时状态) 持久化 (持久状态)
现在的项目大多使用三层构架:
- 表示层
- 业务逻辑层(服务层)
- 持久化层 (这里的持久化层就是持久化的意思)
DAO
Data Access Object 数据访问对象
DAO与持久化的关系是:DAO一种程序数据访问层(持久化层)的设计思想,供逻辑层使用。
DAO不仅仅是其中的DAO类, DAO完整组件如下:
- DAO 工厂类 (暂时不使用,使用工厂设计模式), 根据不同的数据源与访问特性生产对应的DAO产品,供业务逻辑类使用
- DAO接口(一个)
- 实现了DAO接口的具体类 ,根据数据源或者数据访问方式的不同有一个或多个
- 实体类
- DTO:Data Transfer Object数据传输对象 (实现Serializable接口)
- VO:Value Object 值对象
- POJO:实体类
ORM
Object-Relational Mapping 对象关系映射
对象-关系映射:完成应用程序对象数据到关系型数据映射的机制 (利用程序我们把一个实体类的数据转化为关系型数据库表中的一行数据,或者把关系型数据库表中的一行数据转化为应用程序中的一个实体类)
- ORM与DAO的关系:ORM是DAO接口针对关系型数据库的一种实现,本质上就是一个DAO实现类。
- ORM思想:将关系型数据库中的表记录映射成对象,程序员可以把对DB的操作转化为对Object的操作
- ORM框架:ORM思想的一个优雅实现,例如:Hibernate(JBoss),iBatis,Apache OJB,TopLink(Oracle),Castor JDO,...
应用对象数据 <--------------------> 关系型数据库
(实体类) 映射 (表)
一大堆类库,用面向对象的方式调用,它帮忙翻译成面向关系的方式 建立对象与表间关联,以简化编程,跨数据库平台
JPA & Hibernate
JPA
Java Persistent API 一个ORM规范(即一个持久层规范,类(较少)与接口(较多)的集合),通过注解Annotation或XML描述的方式完成对象关系映射
意愿统一天下:像JDBC那样定义一个ORM规范,各ORM框架实现此规范(即各ORM框架实现JPA中的接口),这样只要学习了这个ORM规范就可以使用所有ORM框架了
Hibernate
hibernate是ORM思想的一个实现框架,先有Hibernate后有JPA,用Annotation来支持JPA官方标准
Client –Object save() ->Hibernate-> Persist()—DB
通过Hibernate实现Persist持久化到DB
Hibernate应用场景:
- 不适合OLAP(On-Line Analytical Processing 联机分析处理):以查询分析统计数据为主的系统,一般是条记录,不是对象
- 适合OLTP(On-Line Transaction Processing 联机事务处理)
最佳实现: 1.设计细粒度的持久类,使用组件Component映射 。。。
Starter
- 添加Hibernate依赖包
<dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>xxx</version> </dependency> 建立hibernate 主配置文件hibernate.cfg.xml (可参考Hibernate jar包/project/etc/下的配置文件)
<hibernate-configuration> <session-factory> <property name="dialect">org.hibernate.dialect.SQLServerDialect</property> <!-- 方言,用来区别不同数据库--> <property name="connection.url">jdbc:sqlserver://localhost:1433;databaseName=Bike</property> <property name="connection.username">sa</property> <property name="connection.password">Aa123456</property> <property name="connection.driver_class">com.microsoft.sqlserver.jdbc.SQLServerDriver</property> <!-- <property name="myeclipse.connection.profile">Sql2008</property>--> <!-- JDBC connection pool (use the built-in) --> <property name="connection.pool_size">2</property> <!--使用connection 数据库连接管理事务,使用connection连接管理事务(当前线程中找Session,只针对一个数据库) --> <property name="current_session_context_class">thread</property> <!-- hbm:hibernate mapping; ddl:data defination language ; hbm2ddl:Hibernate自动生成建表语句 --> <property name="hbm2ddl.auto">Validate</property> <property name="show_sql">true</property> <!-- 格式化显示输出sql --> <property name="format_sql">true</property> <!-- 指明映射配置,两种方式: 使用xml映射文件:<mapping resource="com/java/entity/Guestbook.hbm.xml" />, 使用Annotation:<mapping class="bike.entity.Product"/>--> <mapping class="bike.entity.Product"/> </session-factory> </hibernate-configuration>- 编写pojo实体类(可通过Hibernate反向工程自动生成)
@Entity @Table(name = "product") public class Product implements java.io.Serializable{ //... @Id @GeneratedValue(strategy=IDENTITY) @Column(name = "id", unique = true, nullable = false) public int getId(){ return this.id; } }
SessionFactory & Session
| SessionFactory | Session |
|---|---|
| 类似ConnectionPool数据库连接池, 用来产生和管理Session | 从DB连接池中获取一个Connection挂到Session上,管理一个数据库的任务单元(简单说就是增 删 改 查) |
| 线程安全,生命期长,一个数据库对应一个SessionFactory | 非线程安全,生命期短,内部维护一级缓存和DB连接 |
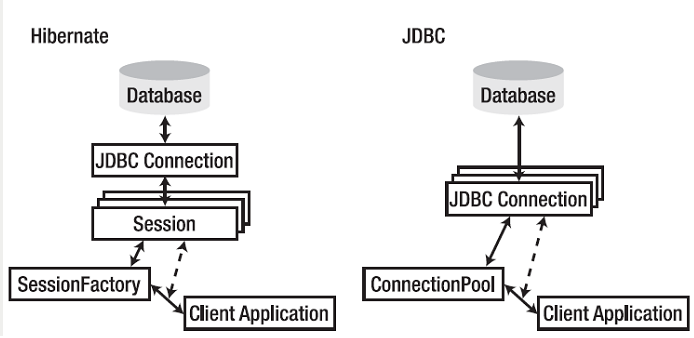
创建SessionFactory ,通常情况下每个应用只需要一个SessionFactory(除非要访间多个数据库的情况)
//主要维护DB连接池,很消费资源,一般创建一个,可使用单例,放在static语句块中 private static SessionFactory sf=null; static{ try{ //Hibernate3 //Configuration config=new Configuration().configure(); //sf=config.buildSessionFactory(); //Hibernate4 //Configuration cfg=new AnnotationConfiguration().configure(); Configuration cfg = new Configuration().configure(); ServiceRegistry serviceRegistry = new ServiceRegistryBuilder() .applySettings(cfg.getProperties()).buildServiceRegistry(); sf = cfg.buildSessionFactory(serviceRegistry); } catch (HibernateException e){ e.printStackTrace(); } }获取session
- 使用
openSession,每次都是新的,需要手动closeSession session=sf.openSession(); //使用session执行CRUD ... session.close(); - 使用
getCurrentSession从上下文找,如果有,用旧的,如果没有,建新的, 界定事务边界,无需手动close,事务提交会自动close/* 使用getCurrentSession需在hibernate的xml主配置文件中配置: <property name="current_session_context_classs">thread</property> */ Session session=sf.getCurrentSession(); session.beginTransaction(); //使用session执行CRUD ... session.getTransaction().commit(); - hibernate的xml主配置文件中
current_session_context_class说明:thread使用connection连接管理事务- 当前线程中找Session,只针对一个数据库
jta全称java transaction api,-java分布式事务管理distributed transaction- 多数据库访问,分布在多台不同数据库上
- eg:两个数据库操作放在一个事务里
- ApplicationServer提供Transaction Manager(JTA事务)
- Tomcat本身不可以,结合Spring可以,Jbass可以
- jta由中间件提供(jboss WebLogic等,tomcat不支持)
managedcustom.Class
- 使用
使用Session执行CRUD
- save
- get,load(Xxx.class,id): 都会首先査找缓存(一级缓存),如果没有,才会去数据库査找
方法 不同 说明 load 返回的实际上是一个代理对象 等到真正用到对象的内容时才发出sql语句,即会产生延迟加载,故在真正使用前若不存在此对象不会报错 get 返回的是实际对象 马上会发出sql语句,直接从DB中加载,不会产生延迟 - update
- 用来更新detached对象,更新完成后转为persistent状态
- 更新transient对象会报错,更新自己设定id的transient对象可以(数据库有对应记录)
- persistent状态的对象只要设定(如:t.setName…)不同字段提交时就会发生更新,若跟原来字段值相同则不更新
- delete
- saveOrUpdate,merge
- clear 强制清空Session缓存
- flush 强制将内存(session缓存)与数据库同步,即将Session缓存中内容提交到DB
- 默认情况下是当session的事务提交后,强制将内存(session缓存)与数据库同步
- 设定何时同步缓存与数据库session.FlushMode(FlushMode.XXX) ,很少用
- 例如:
session.setFlushMode(FlushMode.AUTO)(需在session.beginTransaction()前调用,默认为AUTO;在调节性能时可能会用到此方法)
- ...
可使用泛型DAO封装SessionFactory,Transaction事务,方便在项目中调用
主键
生成策略
AUTO相当于NATIVE,取决于底层数据库类型,eg:- 对 MySQL使用auto_increment
- 对 Oracle使用hibernate_sequence(sequence名称固定为hibernate_sequence)
IDENTITY自动增长SEQUENCE序列- 对于Oracle,默认使用
hibernate_sequence(插入数据时先执行Select hibernate_sequence.nextval from dual然后执行insert) - 可自定义在数据库生成指定的sequence名,结合
@SequenceGenerator使用
- 对于Oracle,默认使用
TABLE借助数据库表,表中保存当前标识属性的最大值- 一张表可提供无限多个ID值
- 跨数据平台时有用, eg: 类库可应用在任何数据库平台上
- 结合
@TableGenerator使用
uuid结合@GenericGenerator使用
使用举例:
使用Annotation方式(加在get主键方法上)
//auto @Id @GeneratedValue(strategy=GenerationType.AUTO) //identity @Id @GeneratedValue(strategy=GenerationType.IDENTITY) //sequence(默认使用hibernate_sequence) @Id @GeneratedValue(strategy=GenerationType.SEQUENCE) //指定sequence名 //"teacherSEQ"为@SequenceGenerator的标识名 //"teacherSEQ_DB"为指定到数据库生成的Sequence名 @Id @GeneratedValue(strategy=GenerationType.SEQUENCE,generator="teacherSEQ") @SequenceGenerator(name="teacherSEQ", sequenceName="teacherSEQ_DB") //table @Id @GeneratedValue(strategy=GenerationType.TABLE,generator="teacherID") @TableGenerator(name="teacherID", table="teacherID_DB", pkColumnName="key_value", pkColumnValue="pk_value", valueColumnName="teacher", allocationSize=1) public int getId() { return id; }- 使用xml方式:
<!-- 常用四个:native identity sequence uuid(native uuid跨平台)--> <id name="id" > <generator class="native"></generator> </id>
联合主键
将联合主键的属性提取出来,重新编写一个pojo类
/* 实现 java.io.Serializable 序列化接口(此为标记性接口,不用实现任何方法) 重写equals和hashCode方法 (用于确保内存PK的唯一性) */ public class StudentPK implements Serializable { private String id; private String name; … … //get/set 方法 ... ... //重写equals方法 @Override public boolean equals(Object o) { if(o instanceof StudentPk) { StudentPk pk = (StudentPk)o; if(this.id == pk.getId() && this.name.equals(pk.getName())) { return true; } } return false; } //重写hashcode方法 @Override public int hashCode() { return this.name.hashCode(); } }XML配置方式(composite-id)
<!-- 原pojo类Student中删除id,name属性,并加入新属性“StudentPK”--> <hibernate-mapping> <class name="com.bjsxt.pojo.Student" > <composite-id name="studentPK" class="com.bjsxt.pojo.StudentPK"> <key-property name="id"></key-property> <key-property name="name"></key-property> </composite-id> <property name="age" /> <property name="sex" /> <property name="good" type="yes_no"></property> </class> </hibernate-mapping>Annotation 配置方式
方法1: 使用
@Embeddable//提取主键的主键类StudentPK上加 @Embeddable(可导入的,可注入的) @Embeddable public class StudentPK implements Serializable { private String id; private String name; … … } //pojo类Student的新属性“StudentPK“的get方法前加@Id @Entity public class Student { private StudentPK studentPK ; @Id public StudentPK getStudentPK() { return studentPK; } … … }方法2:联合主键上使用
@EmbeddedlD//主键类StudentPK不加注解 public class StudentPK implements Serializable{ private String id; private String name; … … } //pojo类Student新属性“studentPK”的get方法前写@EmbeddedlD @Entity public class Student{ private StudentPK studentPK ; @EmbeddedlD public StudentPK getStudentPK() { return studentPK; } … … }方法3(推荐):pojo类上使用
@IdClass//主键类StudentPK不加注解 public class StudentPK implements Serializable{ private String id; private String name; … … } //pojo类Student前加“@IdClass(StudentPK).class)”,保留 id,name属性并加@Id @Entity @IdClass(StudentPK.class) public class Student { private String id; private String name; @Id public String getId() { return id; } @Id public String getName() { return name; } ... ... }
说明:
- 序列化应用环境
- 系统集群
- 虚拟内存(内存空间满了,需要通过序列化将对象暂存到虚拟空间(硬盘上))
- DB记录读入内存,从内存读取对象:
- 从表Student中读取记录装入内存的哈希表中,需计算对象Student主键PK的HashCode然后插入哈希表中;
- 在哈希表中查找内容是否相同时:首先遍历HashCode,然后使用equals判断HashCode相同的各个对象
- 可使用Commonclipse:Commons lang builder插件帮助生成
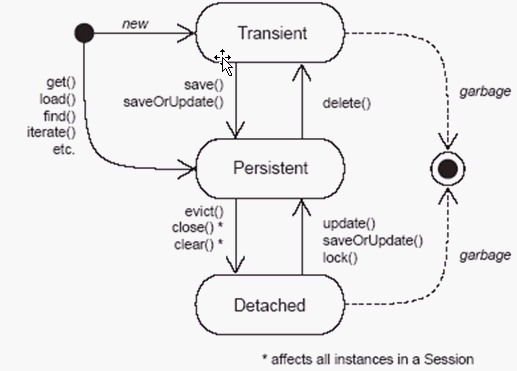
对象状态
三种状态:
| 状态 | Session缓存中 | DB中 |
|---|---|---|
| Transient 瞬时透明 | 无 | 无 |
| Persistent 持久化的 | 有 | 有 |
| Detached 托管的(脱离Session管理) | 无 | 有 |
三种状态的区分关键在于:
- 有没有ID
- ID在数据库中有没有
- 在内存中有没有(session缓存)
映射
关系映射
对象之间的关系(不是指数据库的关系)
映射关系:
@OneToOne,@OneToMany,@ManyToOne,@ManyToManymappedBy: 设置双向关联cascade:设置对象间的级联操作- 只对增删改
CUD起作用 (Create,Update,Delete) cascade={CascadeType.xxx},CascadeType取值:ALL:Cascade all operations所有情况MERGE:Cascade merge operation合并(merge=save+update)PERSIST:Cascade persist operation存储 persist()REFRESH:Cascade refresh operation刷新REMOVE:Cascade remove operation删除
- 只对增删改
fetch:设置抓起策略- 只对读取
R起作用(Select) fetch=FetchType.xxx,FetchType取值:EAGER:取出关联 (注意:双向不要两边设置Eager,否则会有多余的査询语句发出)LAZY:不取关联,即延迟加载 (注意:需要在commit()之前, session还存在时取关联对象)
- 只对读取
例如:
@OneToMany(mappedBy="parent", cascade={CascadeType.ALL}, fetch=FetchType.EAGER) public List<Tree> getChildren() {...}
关联外键字段设置:
@JoinColumn指定关联的DB字段@JoinColumn(name=”对应DB表中的列名”)
@JoinColumns关联联合主键@JoinColumns({ @JoinColumn(name=”...”, referencedColumnName=”...”) , ... })- 例如:
@OneToOne @JoinColumns( { @JoinColumn(name = "wifeid", referencedColumnName = "id"), @JoinColumn(name = "wifename", referencedColumnName = "name") }) public Wife getWife() {……}
@JoinTable多对多关联,指定中间表@JoinTable(name=”中间表名”,joinColumns={@JoinColumn(...)},inverseJoinColumns={@JoinColumn(...)})name指明中间表表名;joinColumns包含@JoinColumn数组,指明本类主键在中间表中对应的字段名;inverseJoinColumns包含@JoinColumn数组,指明对方类主键在中间表中的字段名例如:
@ManyToMany @JoinTable(name="t_s", //指定中间表表名 joinColumns={@JoinColumn(name="teacherid")},//本类主键在中间表生成的对应字段名 inverseJoinColumns={@JoinColumn(name="studentid")}//对方类主键在中间表生成的对应字段名 ) public Set<Student> getStudents(){...}
使用举例:
OneToOne (使用外键 mappedBy)
名称 表 对象 Husband id,name,wifeid (FK:wifeid) id,name,wife Wife id,name id,name,(husband) xml方式:
<!-- 单向 many-to-one, unique="true",保证生成的字段唯一,这样many-to-one 也达到了一对一的效果 --> <class name="com.bjsxt.pojo.Husband"> <id name="id"> <generator class="native"></generator> </id> <property name="num"/> <many-to-one name="wife" column="wifeId" unique="true"> </many-to-one> </class> <!-- 双向many-to-one unique ,one-to-one property-ref(相当于mappedBy),Wife.hbm.xml文件中加 :--> <one-to-one name="husband" property-ref="wife"></one-to-one>Annotation方式:
@Entity public class Husband { private int id; private String name; private Wife wife; ... @OneToOne @JoinColumn(name="wifeid") //指定对应的DB字段名 public Wife getWife() { return wife; } } //设置双向关联:增加husband属性,getHusband方法(若不加mappedby会生成2个映射关系FK) @Entity public class Wife { private int id; private String name; private Husband husband; ... @OneToOne(mappedBy="wife") //指定这个一对一关联是被Husband类的 wife属性(准确说是getWife方法)映射 public Husband getHusband() { return husband; } }OneToOne (使用主键 @PrimaryKeyJoinColumn)
名称 表 对象 Husband id,name id,name,wife Wife id,name id,name,husband Husband(id) reference wife(id) / / xml方式:
<!-- 单项:one-to-one id (有bug,不会为两张表生成外键的参考关系,容易产生id不一致的现象)--> <one-to-one name="wife" constrained="true"/> <id> <!--Husband的主键应参考Wife的主键生成--> <generator class="foreign"> <!-- 指定靠哪个属性上的外键关系生成主键 --> <param name="property">wife</param> </generator> </id> </one-to-one> <!-- 双向:one-to-one id 使用foreign class和one-to-one property-ref --> <one-to-one name=”husband”,property-ref=”wife”/>Annotation方式:
@Entity public class Husband { private int id; private String name; private Wife wife; ... @oneToOne @PrimaryKeyJoinColumn public Wife getWife() { return wife; } } @Entity public class Wife { private int id; private String name; private Husband husband; ... @oneToOne @PrimaryKeyJoinColumn(mappedBy=”wife”) public Husband getHusband() { return husband; } }OneToOne (使用联合主键 @JoinColumns)
名称 表 对象 Husband id,name,wifeId,wifeName id,name,wife Wife id,name (联合主键) id,name @Entity public class Husband { private int id; private String name; private Wife wife; ... @OneToOne @JoinColumns( { @JoinColumn(name = "wifeid", referencedColumnName = "id"), @JoinColumn(name = "wifename", referencedColumnName = "name") }) public Wife getWife() {……} } //Wife类中建立联合主键,建立方式参考 ID生成策略中的联合主键部分 ...@ManyToOne (多对一,单项)
名称 表 对象 User id,name,groupId (FK:groupId) id,name,group (多) Group id,name id,name (一) xml方式:
<many-to-one name="group" column="groupid" cascade="all"/>Annotation方式:
@Entity public class User { private int id; private String name; private Group group; ... @ManyToOne @JoinColumn(name=”groupId”) //指定对应的DB字段名 public Group getGroup() {...} }@OneToMany (一对多,单项)
名称 表 对象 User id,name,groupId (FK:groupId) id,name (多) Group id,name id,name,Set users (一)xml方式:
<class name="com.hibernate.Group" table="t_group"> <id name="id"> <generator class="native"/> </id> <property name="name"/> <set name="users"> <key column="groupId"/> <!-- 指定生成外键字段的名字--> <one-to-many class="com.pojo.User"/> </set> </class>Annotation方式:
public class Group { private int id; private String name; private Set<User> users = new HashSet<User>(); ... @OneToMany @JoinColumn(name=”groupId”) //指定User表中生成与Group对应的字段名 public Set<User> getUsers() {...} }@ManyToOne & @OneToMany (一对多和多对一,双向)
名称 表 对象 User id,name,groupId (FK:groupId) id,name,group (多) Group id,name id,name,Set users (一)xml方式: 务必确保在多的一端生成的生成的外键和一的一方生成的外键的名字相同,都为groupId.如果名字不同则会在多的一端生成多余的外键
Annotation方式:
//在多的一端User配置group @ManyToOne @JoinColumn(name="groupid") //在一的一端Group配置users @OneToMany(mappedBy="group")@ManyToMany (多对多)
名称 表 对象 Teacher id,name id,name,Set students Student id,name id,name,Set teacher 中间表t_s teacherId,studentId / xml方式:
<!-- 单项:--> <class name="com.xxx.Teacher"> <id name="id"> <generator class="native"/> </id> <property name="name"/> <set name="students" table="t_s">table定义中间表的表名 <key column="teacher_id"></key> <many-to-many class="com.xxx.Student" column="student_id"/> </set> </class> <!-- 双向:两端配置一样,注意表名和生成的中间表的字段属性名要一致(table=”t_s”,column错开对应)--> <!-- Teacher那一端配置:--> <set name="students" table="t_s"> <key column="teacher_id"/> <many-to-many class="com.xxx.Student" column="student_id"/> </set> <!-- 在Student那一端配置:--> <set name="teachers" table="t_s"> <key column="student_id"></key> <many-to-many class="com.xxx.Teacher" column="teacher_id"/> </set>Annotation方式:
//Teacher是主的一方 Student是附属的一方 @Entity public class Teacher { private int id; private String name; private Set<Student> students=new HashSet<Student>(); ... @ManyToMany @JoinTable(name="t_s", //指定中间表表名 joinColumns={@JoinColumn(name="teacherid")},//本类主键在中间表生成的对应字段名 inverseJoinColumns={@JoinColumn(name="studentid")}//对方类主键在中间表生成的对应字段名 ) public Set<Student> getStudents(){...} } //双向关联,注意:mappedBy 与 @JoinTable等一类的配置要分开,不然表字段可能乱 @Entity public class Student { private int id; private String name; private Set<Teacher> teacher=new HashSet<Teacher>(); ... @ManyToMany(mappedBy=”students”) public Set<Teacher> getTeachers(){...} }
组件映射
对象关系:一个对象是另外一个对象的一部分 数据库表:一张表
| 表 | 对象 |
|---|---|
| Husband:id,name,wifename,wifeage | 对象Husband :id,name,Wife wife |
| / | 对象Wife:name,age |
public class Husband
{
//id,name,wife
...
@Embedded //表明该对象是从别的位置嵌入过来的,是不需要单独映射的表
Public Wife getWife()
{ return wife;}
}
@Embeddable //写在分类(Wife类)的类名前的,不过好像不写也行
public class Wife {… …}
PS: 若Husband与Wife两个类中都有name字段,这样在生成表的时候会有冲突
解决方案:
- 方法一:重新指定生成的Wife类组件生成的字段名
- 使用 @AttributeOverride注解,写在getWife方法上 (不常用)
- 指定Wife类中的name属性对应新的字段名—“wifename”
- 方法二(更好的解决方法):
- 不要在组件的两个映射类中写同名属性;
- 如果真的有重复,在分类中(此处为Wife类)的重复名称的属性上使用@Column指定新的字段名
- Annotation方式:
@Column(name="wifename") public String getName() {return name;} - xml方式: component
<class name="Husband" > <id name="id"> <generator class="native"/> </id> <property name="name"></property> <component name="wife"> <property name="wifeName"/> <property name="wifeAge"/> </component> </class>
集合映射
Set,List,Map (注意:JPA1.0 目前不支持基础数据映射)
//List (与Set差不多 多个@OrderBy)
@OrderBy(" name asc")
getXXX(){...}
//Map
@Mapkey(name="id")
getXXX(){...}
for(Map.Entry<Integer,User> entity:g.getUsers().entrySet())
{ System.out.println(entry.getValue().getName());}
继承映射
继承映射:@Inheritance子类的Id都由父类中指定的方式生成,三种方式(InheritanceType):SINGLE_TABLE,TABLE_PER_CLASS,JOINED
SINGLE_TABLE一张总表, 字段多的话会造成大冗余表 对象 Person (id,name,score,title,discriminator) Student:id,name,score / Teacher:id,name,title @Entity @Inheritance(strategy=InheritanceType.SINGLE_TABLE) @DiscriminatorColumn(name="discriminator",discriminatorType=DiscriminatorType.STRING) @DiscriminatorValue("person") public class Person { ... //属性id,name @Id @GenerateValue public void getId(){return id;} } @Entity @DiscriminatorValue("student") public class Student extends Person //注意不要标注@Id了 {... } //属性score @Entity @DiscriminatorValue("teacher") public class Teacher extends Person //注意不要标注@Id了 {...} //属性titleTABLE_PER_CLASS每个类分别一张表- 在load或get数据时建议直接用子类
- 若用多态去获取,会Union所有对象再根据id查询
例如:使用(Person.class,1),会 select from ( person union student union teacher ) => 包含所有字段的表,相当于Single Table
表 对象 Person(id,name) Person(id,name) Student(id,name,score) Student (score) extends Person Teacher(id,name,title) Teacher (title) extends Person t_gen_table(t_pk,t_value) / 注意: Person,Student,Teacher表的id各不相同
@Entity @Inheritance(strategy=InheritanceType.TABLE_PER_CLASS) @TableGenerator{ name="t_gen",table="t_gen_table", pkColumnName="t_pk",valueColumnName="t_value", pkColumnValue="person_pk",initialValue=1,allocationSize=1} //Oracle 可用一个Sequence public class Person //属性 id,name { ... @Id @GeneratedValue(generator="t_gen",strategy=GenerationType.TABLE) public int getId(){ return id; } } @Entity public class Student extends Person //其他注解什么都不需要加 {..} // 属性score @Entity public class Teacher extends Person /其他注解什么都不需要加 {...} //属性title
JOINED每个子类一张表(这种用的相对多些)- 用子对象插入和读取是都会关联两张表(父和子)
用多态父类获取时会关联所有表
表 对象 Person(id,name) Person(id,name) Student(id,score) Student (score) extends Person Teacher(id,title) Teacher (title) extends Person 注意: Student id 参考Person(id) ,Teacher id 参考 Person(id)
@Entity @Inheritance(strategy=InheritanceType.JOINED) public class Person //属性 id,name {... @Id @GenerateValue public void getId(){return id;} } @Entity public class Student extends Person //其他注解什么都不需要加 {..} // 属性score @Entity public class Teacher extends Person /其他注解什么都不需要加 {...} //属性title
综合实例
Student,Score(中间表),Course
名称 表 对象 Student id,name (多) id,name,Set courses Course id,name (多) id,name,Set students Score id,student_id,course_id,score (中间) id,student,course,score @Entity public class Student { private int id; private string name; private Set<Course> courses=new HashSet<Course>(); ... @ManyToMany @JoinColumns(name="score", joinColumns={@JoinColumn(name="student_id")}, inverseJoinColumns={@JoinColumn(name="course_id")} ) public Set<Course> getCourses(){ return courses;} } @Entity public class Course { private int id; private string name; ... } @Entity public class Score { private int id; private int score; private Student student; private Course course; .... @ManyToOne @JoinColumn(name="student_id") public Student getStudent(){return student;} @ManyToOne @JoinColumn(name="course_id") public Course getCourse(){return course;} ... }Tree树状结构(在同—个类中使用OneToMany和ManyTo0ne)
名称 表 对象 Tree id,name,parentId id,name,Tree parent,List children public class Tree{ private int id; private String name; private Tree parent; private List<Tree> children = new ArrayList<Tree>(); // 可用Set ... @ManyToOne @JoinColumn(name="parent_id") public Tree getParent(){ return parent; } //@OneToMany的fetch默认为LAZY //若树形较小 可使用EAGER 一次全部载入内存 //若为LAZY则查询树形时不会一次全部载入内存(适用于较大的树形),会每取一个叶子节点就select一次(可结合Ajax,异步调用) @OneToMany(mappedBy="parent", cascade={CascadeType.ALL}, fetch=FetchType.EAGER ) public List<Tree> getChildren() { return children; } } //调用打印树: public void print(Tree root){ //递归打印 System.out.println(root.getName()); for(Tree t : root.getChildren()) { print(t); } } public void print(Tree root,int level ){ //递归打印成树状结构 String preStr=""; for(int i=0;i<level;i++) preStr+="----"; System.out.println(preStr+root.getName()); for(Tree t : root.getChildren()){ print(t,level+1); } }
查询
查询效率: NativeSQL >HQL.> EJBQL(JPQL 1.0) > QBC(Query By Criteria) > QBE(Query By Example)
NativeSQL
原生SQL查询(使用数据库本身的查询语言),使用session.createSQLQuery
举例:
SQLQuery q=session.createSQLQuery("select * from category limit 2,4").addEntity(Category.class);
List<Category> categoryList=(List<Category>)q.list();
//使用别名,将c这个别名映射为Category类
SQLQuery q=session.createSQLQuery("select {c.*} from category c,topic t where c.topicid=topic.id and c.id=:categoryId");
q.addEntity("c",Category.class);
q.setInteger("categoryId",2);
List<Category> categoryList=(List<Category>)q.list();
//投影查询
SQLQuery q=session.createSQLQuery("select c.id,c.name from category c,topic t where c.topicid=t.id");
q.addScalar("id",Hibernate.INTEGER).addScalar("name",Hibernate.STRING);
q.setResultTransformer(Transformers.aliasToBean(Category.class));
List<Category> categoryList=(List<Category>)q.list();
HQL
Hibernate Query Language (Hibernate查询语言),使用session.createQuery
方法举例:
- sql中设置参数,使用
:XXX相当于prepareStatement 预留变量,可以是基本变量,也可以是对象 q.setParameter(XXX,value);自动转换q.setXXX(...);指定转换类型,eg:setInteger(XXX,value);q.list();q.uniqueResult();q.executeUpdate();
使用举例:
连接查询 (对象需建立关联)
-- 不需要再写on连接条件,这里是inner join -- 注意:这里必须写t.category select t.title,c.name from Topic t join t.category c //迫切连接查询 Select c from Category c join fetch c.topics"from ..." 返回实体对象:
q=session.createQuery("from Category c where c.id>:min and c.id<:max"); q.setParameter("min",2); q.setInteger("max",6); q=session.createQuery("from Topic t where t.createData<:date"); q.setParameter("date",new Date()); q=session.createQuery("from Msg m where m=:MsgToSearch"); Msg m=new Msg(); m.setId(1); q.setParameter("MsgToSearch",m); Msg mResult=(Msg)q.uniqueResult(); //只有一条记录时使用"select ..." 返回Object[]:
q=session.creatQuery("select t.id,t.name from Topic t") List<Object[]> topicList=(List<Object[]>)q.list();VO(Value Object)~DTO(Data Transfer Object), Hibernate 让开发者摆脱了繁琐的DTO
q=session.creatQuery("select new com.pojo.MsgInfo(m.id,m.content,m.topic.title,m.topic.category.name) from Msg m"); List<MsgInfo> list=q.list();- update
Query q=session.createQuery("update Topic t set t.title=upper(t.title)"); q.executeUpdate(); - in: 用in可以实现exists的功能,但是exists的执行效率高
// Topic 中设置了msgs的@OneToMany导航 from Topic t where t.msgs is empty from Topic t where not exists (select m.id from msg m where m.topic.id=t.id) from Topic t where t.id not in ( select m.topic.id from msg m )
QBC & QBE
标准化对象查询(Criteria Query):以对象的方式进行查询,将查询语句封装为对象操作
- 优点:可读性好,符合Java 程序员的编码习惯。
- 缺点:不够成熟,不支持投影(projection)或统计函数(aggregation)
QBC,QBE 以对象的方式进行查询 应用场景: 按条件搜索对象时,使用QBC,QBE 则不用手动拼写SQL了 使用session. createCriteria (Criterion 标准/准则/约束 , Criteria为复数形式)
QBC:
Criteria c=session.createCriteria(Topic.class) // from Topic .add(Restrictions.gt("id",2)) // greater than:id>2 .add(Restrictions.like("title","t_") // like 't_' .createCriteria("category") .add(Restrictions.between("id",3,5)) ; //category.id between 3 and 5 c.list(); session.createCriteria(Topic.class).setFetchMode(“msgs”,FetchMode.JOIN); //若先创建,不绑定session,需要时再绑定session —— 使用 DetachedCriteria ...- QBE
Topic tExample=new Topic(); tExample.setTitle="T_"; Example e=Example.create(tExample) .ignoreCase().enableLike(); Criteria c=session.createCriteria(Topic.class) .add(Restrictions.gt("id",2)) .add(e);
命名的数据库查询
使用Annotation方式,写在类前面:
@NamedQueries,@NamedNativeQueries(命名的本地化数据库查询 ,3.5前不支持)@NamedQueries( { @NamedQuery(name="topic.selectCertainTopic",query="from Topic t where t.id=:id") } )xml方式,写在配置文档中:
<hibernate-mapping> ... <query name=” topic.selectCertainTopic”> <![CDATA[from Topic t where t.id=:id]]> </query> <sql-query name=””> <![CDATA[select {t.*} from Topic t where t.id=:id]]> <return alias=”c” class=”com.pojo.Topic” /> </sql-query> </hibernate-mapping>- 调用:
Query q=session.getNamedQuery("topic.selectCertainTopic"); q.setParameter("id",5); Topic t=(Topic)q.uniqueResult();
直接使用JDBC
通过Session对象的connection()方法获取java.sql.Connection对象,执行SQL语句,提交后会自动关闭 在Hibernate中不支持非读取数据的存储过程(查询需有数据返回)
Transaction tx=session.beginTransaction();
Connection conn=session.connection();
String procedure=”{call updateGuestbookById(?,?)}”;
try
{
CallableStatement stmt=conn.prepareCall(procedure);
stmt.setInt(1,1);
stmt.setString(2,”修改了留言主题”);
stmt.executeUpdate();
tx.commit();
}
catch(SQLException e)
{
e.printStackTrace();
}
缓存
缓存算法:缓存满时,新来的对象该替换掉哪个旧的(指定哪个先完蛋)
- LRU:Least Recently Used –最近很少被使用
- LFU:Least Frequently Used (命中率高低)
- FIFO:First In First Out 按顺序替换
持久层缓存,级别:
- 事务级(eg:Hibernate一级缓存),
- 应用(进程)级(eg: Hibernate二级缓存)
- 分布式级
下面介绍Hibernate缓存
一级缓存(Session)
Hibernate一级缓存:session级别的缓存 (内置的缓存,不能通过程序或配置修改,通过Session实现的缓存)
一级缓存的管理:
- evict() 移除Session缓存中某个对象; eg:session.evict(gb1);
- clear() 清空Session缓存中所有对象;eg:session.clear();
- contains();
- flush();
- setReadOnly();
public void getGuestbook(){
Session session=HibernateSessionFactoryUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Guestbook gb1=(Guestbook)session.get(Guestbook.class,100);
Guestbook gb2=(Guestbook)session.get(Guestbook.class,100);
System.out.printIn(gb1==gb2);
gb1.setEmail("test@123.com");
gb2.setTitle("Test2");
session.getTransaction().commit();
}
=> gb1与gb2相同,总共一条select,一条update
public void getGuestbook(){
Session session=HibernateSessionFactoryUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Guestbook gb1=(Guestbook)session.get(Guestbook.class,100);
session.getTransaction().commit();
Session session=HibernateSessionFactoryUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Guestbook gb2=(Guestbook)session.get(Guestbook.class,100);
System.out.printIn(gb1==gb2);
session.getTransaction().commit();
}
=> gb1与gb2不同,两条select
二级缓存(SessionFactory)
用于应用中降低数据库的负载,缓存数据库查询结果以减少数据库访问次数,提高应用的访问速度
Hibernate二级缓存:SessionFactory级别的缓存 (可以跨越session存在,所有session都能用)
- 由SessionFactory对象负责管理,可以缓存整个应用的持久化对象,即应用级别,又称SessionFactory缓存(插件式)
- 应用场景:经常被访间;改动不大不会经常改动;数重有限
- 二级缓存的策略:read-only -> nonstrict-read-write -> read-write -> transactional
- 缓存组件对缓存策略的支持:
缓存名称 缓存类型 对应的适配器类 read-only nonstrict-read-write read-write transactional Hashtable 内存 org.hibernate.cache.HashtableCacheProvider Y Y Y N EHCache 内存,硬盘 org.hibernate.cache.EhCacheProvider Y Y Y N OSCache 内存,硬盘 org.hibernate.cache.OSCacheProvider Y Y Y N SwarmCache 分布式(不支持分布式事务) org.hibernate.cache.swarmCacheProvider Y Y N N JBoss Cache 1.x 分布式(支持分布式事务) org.hibernate.cache.TreeCacheProvider Y N N Y JBoss Cache2 分布式(支持分布式事务) org.hibernate.cache.jbc2.JBossCacheRegionFactory Y N N Y
使用举例:
使用EhCache 作为二级缓存:
- 导入包:
- ehcache-1.2.3.jar(hibernate包中有提供)
- commons-logging-1.0.4.jar (apache 日志)包
- 在hibernate.cfg.xml 中设定:
<property name= "cache.use_second_level_cache">true</property> <property name="cache.provider_class">org.hibernate.cache.EhCacheProvider</property> - 加入EhCache配置文件
echache.xml(可从hibernate包的etc中copy一份)- 配置
memoryStoreEvictionPolicy = "LRU" - EHCache配置文件ehcache.xml 中参数说明:
名称 解释 maxElementsInMemory 设置保存在内存中缓存对象的最大数量 etemal 设置缓存中对象是否永远不过去(true 活了超时设置,缓存对象永不过期) timeToIdleSeconds 最大空闲时间,单位秒 timeToLiveSeconds 最大生存时间,单位秒 overflowToDisk 内存中缓存对象达到maxElementInMemory限制是,是否将缓存对象保存到硬盘中
- 配置
- 使用
@Cache注解指定需要使用二级缓存的对象(此注解在JPA1.0中还未提供,固在此由hibernate扩展提供) 例如:
@Entity @Cache(usage=CacheConcurrencyStrategy.READ_WRITE) public class Category {...}验证效果:
public void list(){ SessionFactory sessionFactory=HibernateSessionFactoryUtil.getSessionFactory(); Session session1=sessionFactory.getCurrentSession(); session1.beginTransaction(); Product p1=(Product)session1.get(Product.class,1); System.out.printIn(p1.getName()); session1.getTransaction().commit(); Session session2=sessionFactory.getCurrentSession(); session2.beginTransaction(); Product p2=(Product)session1.get(Product.class,1); System.out.printIn(p2.getName()); session2.getTransaction().commit(); }=>session1与session2不同,p1与p2相同,一条select
- 导入包:
应用memcached作为二级缓存(分布式的内存对象缓存系统,通用,不一定在Hibernate中使用)
- 导入包:
- hibernate-memched.jar
- memcached.jar
- spy.jar
- commons-codec.jar
- 下载安装memcached服务器程序,执行
memcached –vv - 在hibernate.cfg.xml 中设定:
<property name= "cache.use_second_level_cache">true</property> <property name="cache.provider_class">com.googlecode.hibernate.memcached.MemcachedCacheProvider</property>
- 导入包:
三级缓存(Query)
Hibernate三级缓存:查询缓存 Query cache (相同的查询可使用,需在二级缓存的基础上)
- 对查询的要求严格,必须条件参数也一致
- 在二级缓存的基础上再打开查询缓存
<property name="cache.use_query_cache">true</property> - 调用Query的
setCachable (true)方法指明使用缓存,例如:session.createQuery("from Category").setCacheable(true).list();
事务
ACID:
- Atomic原子性(执行或不执行);
- Consistency一致性(完整性约束);
- Itegrity 独立性(多事务不会交错);
- Durability持久性(提交后更改是永久的)
事务并发问题
| 并发问题 | 名称 | 解释 |
|---|---|---|
| Lost Update | 第一类丢失更新 | 撤销一个事务会影响另一个事务,只要数据库支持事务,就不可能出现第一类丢失更新 |
| Dirty Read | 脏读 | 读了别的事务还未提交的数据(比如另一事物回滚则刚才读取的数据就会不对) |
| Non-repeatable Read | 不可重复读 | 同一事务中前后读取的数据不一样,即被另一个事务所影响了(一个事务在另一个事务提交前和后读取同一对象的结果不一致) |
| Second Lost Update | 第二类丢失更新 | 不可重复读的特殊情况 |
| Phantom Read | 幻读 | 插入删除时,会多读或少读数据 |
事务隔离机制
不同隔离级别可以发生的并发问题:
| 隔离级别 | 解释 | 更新丢失 Lost Update | 脏读 Dirty Read | 不可重复读Non-repeatable Read | 幻读Phantom Read |
|---|---|---|---|---|---|
| Read Uncommitted | 允许读取未提交的数据,效率最高 | 不可能 | 可能 | 可能 | 可能 |
| Read Committed | 读取已提交的数据,oracle默认使用的级别 | 不可能 | 不可能 | 可能 | 可能 |
| Repeatable Read | 可重复读,给读出的数据加把锁,类似于select ... for update,MySQL 引擎默认使用的级别 (当前事务未结束,其他事务无法执行修改或插入操作,较安全) | 不可能 | 不可能 | 不可能 | 可能 |
| Serializable | 顺序执行事务, 不并发,实际中很少用,最消耗资源 | 不可能 | 不可能 | 不可能 | 不可能 |
设定hibernate的事务隔离级别(查看 java.sql.Connection 文件):
- 配置
hibernate.connection.isolation属性, 取值值1 2 4 8 (1=0000,2=0010,4=0100,8=1000 位移计算效率高)read-uncommitted=1read-committed=2repeatable read =4serializable =8
- 如果不设 默认依赖数据库本身的级别
- eg:
hibernate.connection.isolation = 2表示使用read-committed隔离级别
锁
一般项目中使用read-commited事务隔离机制,在程序中设置悲观锁或乐观锁解决non-repeatable read 和 phantom-read问题
悲观锁 Pessimistic Locking,依赖于数据库的锁
- 悲观锁认为每次读取或修改数据库数据时,其他事务也在并发访问相同的数据,有很强的排他性,即对于这个数据其他事务是不准碰的
- load 时加锁:
session.load(xx.class , i , LockMode.Upgrade)相当于 select ... for update,事务提交后会解除 - 其他LockMode说明:
LockMode.None:无锁的机制,Transaction结束时,切换到此模式LockMode.read:在査询的时候hibernate会自动获取锁LockMode.write:insert update hibernate 会自动获取锁LockMode.UPGRADE_NOWAIT: ORACLE 支持的锁的方式
- 注意:
None,read,write3种锁的模式,是hibernate内部执行时自己使用的(自己加自己解,不需要设)
乐观锁 Optimistic Locking,依赖Hibernate(JPA)的锁
- 乐观锁认为数据库中的数据很少发生同时被操作问题,通过数据的版本号
Version比较机制或时间戳timestamp实现 - 使用
version实现乐观锁原理:- 默认在表中增加一version字段,初始为0
- 当某一事物获取该对象并要update时,先判断version的值是否改变
- 若未改变则version+1,update成功
- 若version值于当初获取时不同,则update失败
流程举例:
时间 转账事务A 取款事务B T1 / 开始事务 T2 开始事务 / T3 查询学生为10人 查询账户余额为1000 version=0 T4 查询账户余额为1000 version=0 / T5 / 取出100 把余额改为900 version=1 T6 / 提交事务 T7 汇入100元 / T8 提交事务 ? version>0 throw Exception / T9 把余额改为1100元(丢失更新) / 示例:
//在pojo实体类中增加version属性(),在get方法前加@Version注解 @Entity public class Account{ //属性:id,balance,version ... @Version public int getVersion() { return version; } }
- 乐观锁认为数据库中的数据很少发生同时被操作问题,通过数据的版本号
性能优化
动态局部插入&更新
方式1:
- 动态局部插入:在pojo类上加
@DynamicInsert - 动态局部更新:在pojo类上加
@DynamicUpdate- 原理:会先根据Id获取对象(若缓存中没有,则从DB中查询加载该对象),逐个字段比对,不一致则update该字段
- 对Persistence对象有用
- 现象:同一个session可以,跨session不行,不过可以用session.merge(XXX对象)(不重要), 实际merge方法会先从DB中select对象到内存,然后update
- 动态局部插入:在pojo类上加
方式2:使用 HQL(EjBQL)
//Query 为org.hibernate.Query; Student 为对象,不是DB表 Query q=session.createQuery(“update Student s set s.name=’zhangsan’ where s.id=1”); q.executeUpdate();
cascade参数对CUD影响
Update时@ManyToOne()中的cascade参数关系
session.beginTransaction(); User user = (User)session.load(User.class,1); //user对象属性改变 事务commit时自动判断与数据库原有数据不同 可自动update //此时的update与@ManyToOne()中的cascade或fetch参数取值无关 user.setName("user1"); user.getGroup().setName("group1"); session.getTransaction().commit();如果user改变在commit()之后且想要执行Update方法时user与group表同时更新,则设置User类
cascade={CascadeType.ALL},并在程序中写如下代码:session.beginTransaction(); User user = (User)session.get(User.class,1); session.getTransaction().commit(); user.setName("user1"); user.getGroup().setName("group1"); Session session2 = sessionFactory.getCurrentSession(); session2.beginTransaction(); session2.update(user); session2.getTransaction().commit();Delete时@ManyToOne()中的cascade关系 如果User及Group类中均设为@ManyToOne(cascade={CascadeType.All}),那么在执行如下:
session.beginTransaction(); User user = (User)session.load(User.class,1); session.delete(user); session.getTransaction().commit();注意: 此处删除的是 多对一(即User对Group) 中的“多”的一方(User类) 会删除user及user对应的group,再反向对应group的user都会删除,原因就是设置了
@ManyToOne(cascade={CascadeType.All})
三种方法可避免全部删除的情况:
- 去掉@ManyToOne(cascade={CascadeType.All})设置;
- 直接写Hql语句执行删除;
- 将user对象的group属性设为null,相当于打断User与Group间的关联,代码如下
session.beginTransaction(); User user = (User)session.load(User.class,1); user.setGroup(null); session.delete(user); session.getTransaction().commit();
注意: 如果删除的是 多对一中的“一”的一方(Group类)时,使用第3种方式(user属性设为null)来打断两个对象间的关联的话,代码与之前不同,如下:
session.beginTransaction();
Group group = (Group)session.load(Group.class,1);
//循环将group中的set集合下的各个user对象设为null
//相当于先将数据库中user表中与group表关联的字段(即groupid)设为null
for(User user :group.getUsers()){
System.out.println(user.getName());
user.setGroup(null);
}
//再将group的set集合设为null,相当于将group表中与user表关联的字段(即userid)设为null
//此句的前提是user表中的关联字段(groupid)已经为null,如没有则相当于破坏了一对多关联,会报错
group.setUsers(null);
session.delete(group);
session.getTransaction().commit();
1+N问题
现象描述: 一个对象关联另一个对象(ManyToOne),而FetchType为EAGER,那么在去这个对象时它所关联的对象也会取出, 本来一句SQL就可取出N条记录,但还要取关联对象,又会再发N条语句取关联的对象
查询某个对象,本来应该只发一条SQL语句查询, 若被关联对象有N条,结果就会再发N条查找关联对象的SQL数据 eg:
select * from topic
select * from category where id=?
select * from category where id=?
...
解决方案:
- 方案一,fetch=FetchType.LAZY 解决N+1问题:
当多对一(@ManyToOne)已经设定属性" fetch=FetchType.LAZY "时
只有当需要时(如:t.getCategory().getName()时)才会去获取关联表中数据 可以解决N+1问题
@ManyToOne(fetch=FetchType.LAZY) - 方案二,@BatchSize 解决N+1问题:
在与查询表(此例中为Topic类)关联的表类(此例中为Category类)头处加@BatchSize(size=5)
表示每次可查出5条记录 从而减少了select语句的个数
@Entity @BatchSize(size=5) public class Category {...} - 方案三,join fetch 解决N+1问题:
//修改hql语句为--" from Topic t left join fetch t.category c " List<Topic> topicList=(List<Topic>)session.createQuery("from Topic t left join fetch t.category c").list(); - 方案四,QBC(Query By Criteria) 解决N+1问题:
QBC 默认使用表连接来取(left join),使用QBC的 createCriteria(*.class)执行查询
List<Topic> topicList=(List<Topic>)session.createCriteria(Topic.class).list();
防止内存泄漏
在同一个Session中,大集合进行遍历,小心出现内存泄漏,用完的数据要及时clear下,让垃圾回收机及时回收掉
发生情境:
在不断分页循环的时候
- 同一Session中执行分页操作,Session 缓存 1~50,51~100,... 越占越多,由于有引用,java虚拟机是不会自动清除的。
- 建议适时的调用
session.clear(); - 一般不同页面会启用新的Session,但是导数据时可能会发生此问题
在一个大集合中进行遍历
- eg:遍历msg,取出其中的含有敏感字样的对象
Java有内存泄漏吗?:
- 在语法级别上没有 ,有Java虚拟机自动垃圾回收;
- 但是可由编程引起,例如:连接池中打开了一个连接不关闭,或打开文件,io读取后不关闭
- 实际上java调用c,c调用windows API,c不会自动回收
延迟加载
Lazy Loading:真正要读取数据时才从DB中获取,在关联对象上的应用较多
可能导致的异常:org.hibernate.LazyInitializationException:could not initialize proxy – no Session
eg: 持久层gb=session.load(...); tx.commit(); 控制层/表示层:gb.getTitle();
解决:
- 方案一:取消延迟加载(不推荐)
- 方案二:使用Hibernate.initialize();
- 方案三:使用Open Session In View(OSIV) 设计模式,延迟session关闭,等都输出处理完后再tx.commit();
- 可使用Servlet过滤器实现自己的OSIV模式:发出请求时开启Session对象,Servlet执行后再关闭Session对象
list & iterate
list
- list 取所有;session中list第二次发出,仍会到数据库査询;
- 使用list会取出对象的所有内容,并加入到二级缓存中,
- 但第二次取同样内容会重新去DB中获取而不从二级缓存中获取
iterate
- iterate先取ID,等用到的时候再根据ID来取对象;
- iterate默认使用二级缓存
- 使用iterate 只会取出对象的Id,当要取该对象的其他内容时,先从二级缓存中查找,没有再重新去DB根据id查询
PS: 若要查询的数据已在缓存中,那用iterate是比较快的,不在就会出现上述N+1问题,这样list的效率会更高
List<Category> categories =(List<Category>)session.createQuery("from Category").list();
for( Category c : categories)
{
System.out.println(c.getName);}
Iterator<Category> categories =(Iterator<Category>)session.createQuery("from Category").iterate();
while(categories.hasNext())
{
Category c=categories.next();
System.out.println(c.getName());
}
}
Hibernate 扩展组件
Hibernate Filter
对查找的记录集再进行过滤
- 使用
<filter-def>定义过滤器,使用<filter>声明使用过滤器<hibernate-mapping> <class name=”” table=”” > ... <set ...> ... <filter name=”...” condition=”...” /> //过滤集合 </set> <filter name=”nameFilter” condition=”NAME=:inputName” /> //NAME 为表中字段 </class> ... <filter-def name=”nameFilter”> <filter-param name=”inputName” type=”java.lang.String” /> </filter-def> </hibernate-mapping> - 在Query调用方法前使用Filter
String hql=”from Guestbook where id between 10 and 200” Query query=session.createQuery(hql); Filter filter=session.enableFilter(“nameFilter”); filter.setParameter(“inputName”,”ZhangSan”); List<Guestbook> list=query.list();
Hibernate Interceptor
创建Session对象时,所有Session对象或此Session对象的所有持久化操作动作都会被指定的拦截器拦截 (org.hibernate.Interceptor 接口)
- 应用:使用拦截器实现审计日志
- 审计日志:在应用系统中,对所以数据库的操作都做记录,包括操作内容,用户,操作时间
public class LogEntityInterceptor extends EmptyInterceptor{
private static final long serialVersionUID=...;
private Logger logger=Logger.getLogger(LogEntityInterceptor.class); //使用Log4J记录日志
public void onDelete(Object entity,Serializable id,Object[] state,String[] propertyNames,Type[] types){
logger.info(“Delete Data”);
}
public boolean onFlushDirty(Object entity,Serializable id,Object[] state,String[] propertyNames,
Type[] types){
logger.info(“Update Data”);
return false;
}
public boolean onSave(Object entity,Serializable id,Object[] state,String[] propertyNames,
Type[] types){
logger.info(“Save Data”);
return false;
}
}
LogEntityInterceptor interceport=new LogEntityInterceptor();
//通过Configuration对象加载拦截器, 此时通过此config生成的sessionFactory,session都会使用此拦截器
Configuration config=new Configuration();
config.setInterceptor(interceptor);
config.configure();
SessionFactory sf=config.buildSessionFactory();
Session seesion=sf.getCurrentSession();
...
//也可通过Session对象加载拦截器
Session session=sf.openSession(interceptor);
Hibernate Listener
事件监听机制:能精确追踪到持久化对象的字段的修改,关联关系的变更,更新前后数值 与拦截器比较:更细粒度上的拦截,可获取修改前后值,可直接通过Event对象获取Session对象
- 实现具体的Listener类或继承具体的Listener接口
- 在
hibernate.cfg.xml中配置事件监听器对象,或使用Configuration对象注册事件监听器对象
Hibernate Search
Hibernate Search特点:
- 支持索引数据的自动更新(通过Hibernate更新变动的数据,会同步更新索引数据)
- 支持众多搜索方式(关键词,通配符,近似,同义词)
- 支持搜索集群
- 支持直接调用Lucene API
底层使用的是Lucene:
- java领域的全文搜索工具包,可对文本,HTML,Excel,PDF等格式的文件建立索引并进行搜索
Hibernate Search类库:
- hibernate-search.jar
- lucene-core.jar
- hibernate-commons-annotations.jar
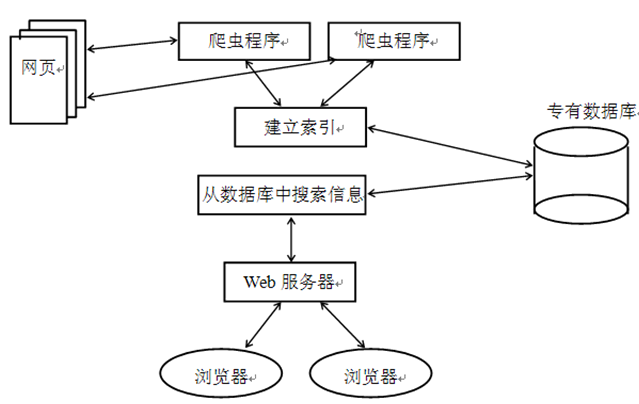
搜索引擎:
- 全文搜索引擎
- 目录索引引擎(一般用在网页黄页中)
- 元搜索引擎(向多个搜索引擎查询汇总)
全文搜索引擎原理:
使用示例:
hibernate配置文件中:
<property name="hibernate.search.default.directory_provider"> org.hibernate.search.store.FSDirectoryProvider </property> <property name="hibernate.search.default.indexBase"> D:/temp/index </property>pojo类:
@Index public class GuesBook { ... @DucumentId public int getId() { return id;} //保存到索引文件中(hibernate-search下的store),默认不存 @Field(store=Store.YES) public String getName() { return name;} //不进行分词处理,默认使用分词处理 @Field(store=Store.YES,index=Index.UN_TOKENIZED) public String getPhone() { return phone;} @Field public String getTitle() { return title;} ... }建立索引
public void index(){ Session session=HibernateSessionFactoryUtil.getSessionFactory().getCurrentSession(); FullTextSession ftSession=Search.getFullTextSession(session); ftSession.getTransaction().begin(); List<Guestbook> list=session.createQuery("from Guestbook").list(); for(Guestbook gb:list) ftSession.index(gb); ftSession.getTransaction().commit(); }搜索
public void query(){ //使用庖丁分词器搜索时,使用: //QueryParser parser=new QueryParaser(“title”,new paoding.analysis.analyzer.PaodingAnalyzer()); QueryParser parser=new QueryParser("title",new StandardAnalyzer()); org.apache.lucene.search.Query luceneQuery=null; try{ luceneQuery=parser.parse("title:中国"); }catch(ParseException e){ e.printStackTrace(); } Session session=HibernateSessionFactoryUtil.getSessionFactory().getCurrentSession(); FullTextSession ftSession=Search.getFullTextSession(session); ftSession.beginTransaction().begin(); org.hibernate.Query query=ftSession.createFullTextQuery(lucenQuery,Guestbook.class); query.setFirstResult(0); query.setMaxResults(20); List<Guestbook> list=query.list(); ftSession.getTransaction().commit(); for(Guestbook gb:list) System.out.printIn("id:"+gb.getId()+",title:"+gb.getTitle()); }=>不使用中文分词时,是分成一个字一个字的
使用第三方的中文分词组件,eg:“庖丁解牛” 分词组件(使用词库)
- 建立配置文件
paoding.dic.home.properties: paoding.dic.home=.../paoding/dic( 配置词库位置) - 将类库
paoding-analisis.jar加入项目中 - pojo类上加入注解:
@Analyzer(impl=net.paoding.analysis.analyzer.PaodingAnalyzer.class)
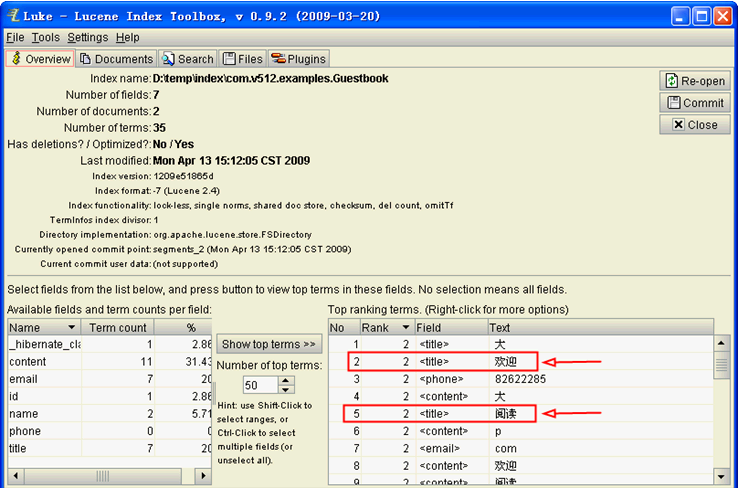
Luck 工具:可显示修改Lucene索引数据和模拟搜索的开源工具
- 在Dos命令下运行: java –jar lukeall.jar
- 中文分词:将中文句子切分成有医院的单词
- 基本机制:使用词库匹配;使用自动切分算法
- 词库切分与自动切分比较:
自动切分 词库表切分 实现 实现简单 实现复杂 查询 增加了查询分析的复杂程度 适于实现比较复杂的查询语法规则 存储效率 索引冗余大,索引几乎和原文一样大 索引效率高,为原文大小的30%左右 维护成本 无词库维护成本 词库维护成本高,还需要包括词频统计等内容 - Luke查看效果如下: