Starter
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题
特性:
- 是一个开源共享资源库
- 具有fast fail特性
- Master/Slave模式,运行于一组机器上
- 不超过半数Server 挂掉不影响服务
- 无中心,Leader故障,自动重新选举Leader,不存在单点故障
基于观察者模式设计的分布式服务管理:
- 负责存储和管理大家都关心的数据
- 接受观察者的注册
- 数据的状态发生变化,Zookeeper会通知注册的观察者
- 实现集群中类似 Master/Slave 管理模式
安装
直接下载解压即可用
安装配置Zookeeper节点:
> cd /user/local/zookeeper-3.4.6 > cp conf/zoo-sample.conf conf/zoo.conf > vi zoo.conf tickTime=2000 dataDir=/home/zkdata clientPort=2181 initLimit=5 syncLimit=2 server.1=192.168.211.1:2888:3888 server.2=192.168.211.2:2888:3888 server.3=193.168.211.3:2888:3888配置说明:
dataDir指定Zookeeper的数据文件目录;server.id=host:port1:port2- id:各个Zookeeper节点的编号,保存在dataDir目录下的myid文件中
- host:各个Zookeeper节点的host
- port1:用于连接leader的端口
- port2:用于leader选举的端口
复制此Zookeeper到其他Server
> cd /usr/local > scp -rp zookeeper-3.4.6 root@192.168.211.2:/usr/local > scp -rp zookeeper-3.4.6 root@192.168.211.3:/usr/local配置各个Zookeeper节点的编号
192.168.211.1:
> mkdir /home/zkdata > echo 1 > /home/zkdata/myid192.168.211.2:
> mkdir /home/zkdata > echo 2 > /home/zkdata/myid193.168.211.3
> mkdir /home/zkdata > echo 3 > /home/zkdata/myid
启动Zookeeper服务:
> /usr/local/zookeeper-3.4.6/bin/zkServer.sh start通过Zookeeper客户端测试服务是否可用:
> /usr/local/zookeeper-3.4.6/bin/zkCli.sh -server 127.0.0.1:2181> /usr/local/zookeeper-3.4.6/bin/zkServer.sh status > jps > /usr/local/zookeeper-3.4.6/bin/zkServer.sh stop
注意事项:
- 最好能通过监控程序将Zookeeper管理起来,保证Zookeeper退出后能被自动重启
- Zookeeper是快速失败(fail-fast)
- 遇到任何错误情况,进程均会退出
- 定期清除没用的日志和快照文件
- Zookeeper运行过程中会在dataDir目录下生成很多日志和快照文件
- 导致占用大量磁盘空间
- 可通过cron等方式定期清除没用的日志和快照文件
java -cp zookeeper.jar:log4j.jar:conf org.apache.zookeeper.server.PurgeTxnLog <dataDir> <snapDir> -n <count>
数据模型
Zookeeper 会维护一个具有层次关系的目录树的数据结构,类似于一个标准的文件系统 通过对树中的节点(ZNode)进行有效管理,可以设计出多种多样的分布式的数据管理模型
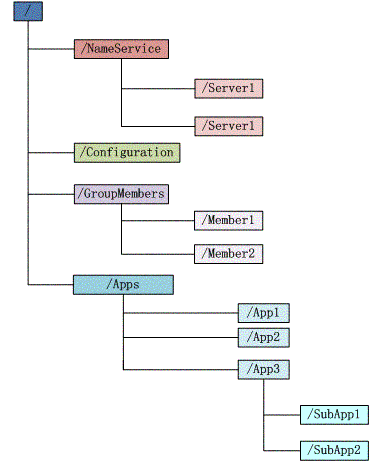
znode
- 路径唯一标识
- 每个子目录项都被称作为 znode,被它所在的路径唯一标识
- 如: Server1 这个 znode 的标识为
/NameService/Server1
- 可以存储数据,ACL访问控制
- 注意:Zookeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控存储的数据的状态变化
- 有版本
- 每个 znode 中存储的数据可以有多个版本(也就是一个访问路径中可以存储多份数据)
- 节点数据内容改变 => 多一个版本号
- 类型:
EPHEMERAL:临时目录节点,与服务器session失效则删除,不能有子节点目录PERSISTENT:持久化目录节点EPHEMERAL_SEQUENTIAL:临时目录节点,可以自动编号PERSISTENT_SEQUENTIAL: 持久化目录节点,可以自动编号
- znode 可以被监控
- 一旦变化(这个目录节点中存储的数据修改,子节点目录变化等)通知设置监控的客户端
- CRUD znode => trigger watch event (watch 通知订阅的 clients)
- watch event
- 异步发送至观察者watcher
- 一次性触发器,触发后需重新设置
Cmd
Server:
- 启动ZK服务:
bin/zkServer.sh start - 查看ZK服务状态:
bin/zkServer.sh status - 停止ZK服务:
bin/zkServer.sh stop - 重启ZK服务:
bin/zkServer.sh restart
Client:
- 连接到zookeeper server
bin/zkCli.sh -server 127.0.0.1:2181 - 查看 zookeeper目录结构
ls / - 创建 znode
create /zk testData - 查看znode data
get /zk - 更新znode data
set /zk testData2 - 删除znode
delete /zk
常用四字命令: (用来获取 ZooKeeper 服务的当前状态及相关信息,在客户端可以通过 telnet 或 nc 向 ZooKeeper 提交相应的命令)
cons- 列出连接到服务器的所有客户端详细信息(连接,会话)。
- 包括“接收/发送”的包数量,会话id,操作延迟等
conf- 输出服务的配置详细信息
envi- 输出服务环境的详细信息,和java环境
dump- 输出未经处理的会话和临时节点
reqs- 列出未经处理的请求
stat- 输出服务的状态,和简要的客户端信息
ruok- 测试服务端是否处于正常状态
- 正常返回"imok"
wchs- 列出服务器watch的详细信息
wchc- 通过 session 列出服务器 watch 的详细信息
- 它的输出是一个与 watch 相关的会话的列表
wchp- 通过路径列出服务器watch的详细信息
- 输出一个与session相关的路径
eg:
> echo stat|nc localhost 2181
> echo ruok|nc localhost 2181
Java API
依赖包
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>${zookeeper.version}</version>
</dependency>
| 方法名 | 功能描述 |
|---|---|
String create(String path, byte[] data, List<ACL> acl, CreateMode createMode) |
创建一个给定的目录节点 path CreateMode: PERSISTENT PERSISTENT_SEQUENTIAL EPHEMERAL EPHEMERAL_SEQUENTIAL |
Stat exists(String path, boolean watch) |
判断某个 path 是否存在,可设置是否监控这个目录节点 (这里的 watcher 是在创建 ZooKeeper 实例时指定的 watcher) |
Stat exists(String path, Watcher watcher) |
判断某个 path 是否存在,并设置监控 (当这个znode节点被改变时,将会触发当前Watcher) |
void delete(String path, int version) |
删除 path 对应的目录节点 (version 为 -1 可以匹配任何版本) |
Stat setData(String path, byte[] data, int version) |
给 path 设置数据 (version 为 -1 可以匹配任何版本) |
byte[] getData(String path, boolean watch, Stat stat) |
获取这个 path 对应的目录节点存储的数据 (版本等信息可以通过 stat 来指定) |
void addAuthInfo(String scheme, byte[] auth) |
客户端将自己的授权信息提交给服务器 服务器将根据这个授权信息验证客户端的访问权限 |
Stat setACL(String path, List<ACL> acl, int version) |
给某个目录节点重新设置访问权限 (注意:Zookeeper ACL不具有传递性) |
List<ACL> getACL(String path, Stat stat) |
获取某个目录节点的访问权限列表 |
还有其他方法可以参考 org.apache.zookeeper.ZooKeeper
// 创建一个与服务器的连接
ZooKeeper zk=new ZooKeeper(ZkServerConfig.ConnectString, ZkServerConfig.SessionTimeout, new Watcher(){
@Override
public void process(WatchedEvent event) {
System.out.println(event.getPath()+" 触发了 " + event.getType() + " event , status:"+event.getState());
}
});
// 创建znode
String rootPath=zk.create(RootPath, "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("创建了路径:"+rootPath);
String childOneAPath=zk.create(RootPath+"/testChildOne","testChildOneData".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println("创建了路径:"+childOnePath);
// 读取znode 数据
byte[] data=zk.getData(RootPath, false, null);
System.out.println("目录节点数据:"+new String(data));
// 更改znode 数据
zk.setData(RootPath,"modifyRootData".getBytes(),-1);
// 查看znode状态
System.out.println("目录节点状态:["+zk.exists(RootPath,false)+"]");
// 获取所有子节点
List<String> children=zk.getChildren(RootPath,false);
System.out.println("目录节点子节点:"+children);
// 删除znode
zk.delete(childOneAPath,-1);
// 关闭连接
zk.close();
Curator
Curator:Zookeeper开源客户端框架
- 封装ZooKeeper client与ZooKeeper server之间的连接处理
- 提供了一套Fluent风格的操作API
- 提供ZooKeeper各种应用场景(recipe, 比如共享锁服务, 集群领导选举机制)的抽象封装
依赖包:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${curator.version}</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-test</artifactId>
<version>${curator.version}</version>
</dependency>
Curator几个组成部分 :
ClientFramework:对zookeeper的一些基本命令的封装,比如增删改查Recipes:高级特性,主要有Elections(选举),Locks(锁),Barriers(关卡),Queues等UtilitiesErrorsExtensions( recipe扩展 )
framework 基础示例:
ExponentialBackoffRetry retryPolicy = new ExponentialBackoffRetry(1000, 3);
//client=CuratorFrameworkFactory.newClient(ZkServerConfig.ConnectString, retryPolicy);
client=CuratorFrameworkFactory.builder()
.connectString(ZkServerConfig.ConnectString)
.retryPolicy(retryPolicy)
.connectionTimeoutMs(1000)
.sessionTimeoutMs(1000)
.build();
client.start();
...
CloseableUtils.closeQuietly(client);
client.create().forPath("/head", new byte[0]);
client.delete().inBackground().forPath("/head");
client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath("/head/child", new byte[0]);
client.getData().watched().inBackground().forPath("/test");
CuratorTransaction transaction = client.inTransaction();
Collection<CuratorTransactionResult> results=transaction
.create().forPath(root+"/Three","Three test data".getBytes())
.and()
.create().forPath(root+"/Three/E","E test data".getBytes())
.and()
.create().forPath(root+"/Three/F","F test data".getBytes())
.and()
.setData().forPath(root+"/Three/E","Modify E data".getBytes())
.and()
.delete().forPath(root+"/Three/G")
.and().commit();
for (CuratorTransactionResult result : results) {
System.out.println(result.getForPath() + " - " + result.getType());
}
说明:
CuratorFrameworkFactory创建CuratorFramework(即client)- 工厂方法newClient(创建一个默认的实例)
- 构建方法build(可对实例进行定制)
RetryPolicy连接重试策略ExponentialBackoffRetry:重试指定的次数, 且每一次重试之间停顿的时间逐渐增加.RetryNTimes:指定最大重试次数的重试策略RetryOneTime:仅重试一次RetryUntilElapsed:一直重试直到达到规定的时间
CuratorFramework- 常用接口:(线程安全,返回构建器)以
forpath()结尾,辅以watch(监听),withMode(指定模式),inBackground(后台运行)等方法来使用- create()
- delete()
- checkExists()
- getData()
- setData()
- getChildren()
- 还支持事务,一组crud操作同生同灭:
- inTransaction: 发起一个ZooKeeper事务,通过commit() 提交
- 常用接口:(线程安全,返回构建器)以
Receipt之互斥锁使用示例:
String path = "/lock";
InterProcessLock lock1 = new InterProcessMutex(client, path);
InterProcessLock lock2 = new InterProcessMutex(client, path);
lock1.acquire();
boolean result = lock2.acquire(10, TimeUnit.SECONDS);
assertFalse(result);
lock1.release();
result = lock2.acquire(10, TimeUnit.SECONDS);
assertTrue(result);
说明:
- acquire() 获得锁
- release() 释放锁
curator还提供了很多其他的实现,具体参考Netflix/curator
应用场景
统一命名服务
特点:
- 唯一的名称
- 可关联到一定资源上
PS: Name Service 已经是 Zookeeper 内置的功能,只要调用 Zookeeper 的 API 就能实现(znode name => 全局唯一的path,调用zk的create node api很容易创建)
配置管理
Configuration Management
发布与订阅 => 集中式管理,动态更新(各Node动态获取更新)
- 将Config Data保存在 Zookeeper 的某个znode中
- 所有需要修改的应用机器Clients监控此znode的状态
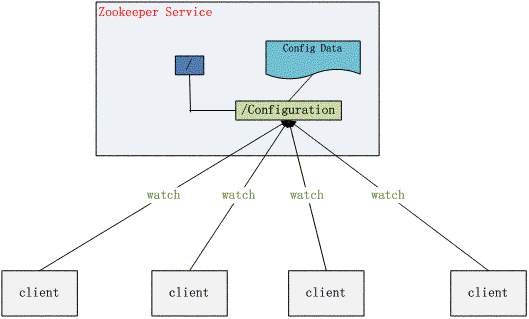
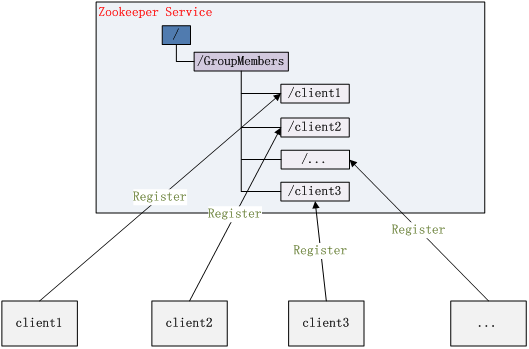
集群管理
Group Membership
Leader选举 (eg: HBase,Storm中)
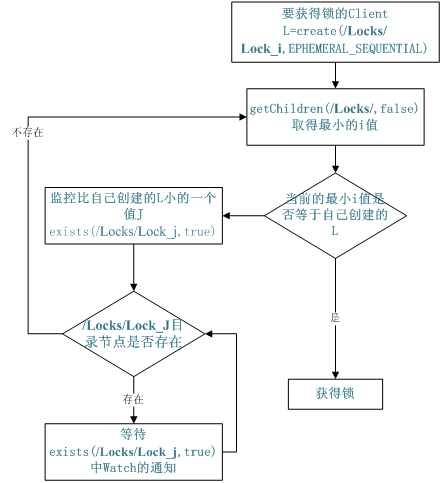
共享锁
Locks
在跨进程或者在不同 Server 之间实现同步
保证数据的强一致性(保证zk集群中任意node上的同一znode的数据是相同的) 锁:保持独占,时序控制
利用临时顺序节点来实现分布式锁机制(其实就是一种按照创建顺序排队的实现)
- 假设锁存放在znode:
/locks下 - Client连入,创建
EPHEMERAL_SEQUENTIAL类型znode,返回创建的znode路径 - 通过
getChildren("/locks",false)获取/locks下所有节点,取得最小的znode路径- 若正是自己创建,则获得锁
- 若不是,则通过
exists("/locks/xxx",true)监控比自己创建的路径小一个的值,进入等待
队列管理
先进先出(分布式锁)、队列成员聚齐后统一执行
Zookeeper 可以处理两种类型的队列:
同步队列(队列成员聚齐后统一执行)
- 创建一个父目录
/synchronizing,每个成员都监控标志(Set Watch)位目录/synchronizing/start是否存在 - 通过创建
/synchronizing/member_i的临时目录节点加入队列 - 判断
member_i的i 的值是否已经是成员的个数,相等就创建/synchronizing/start,小于则等待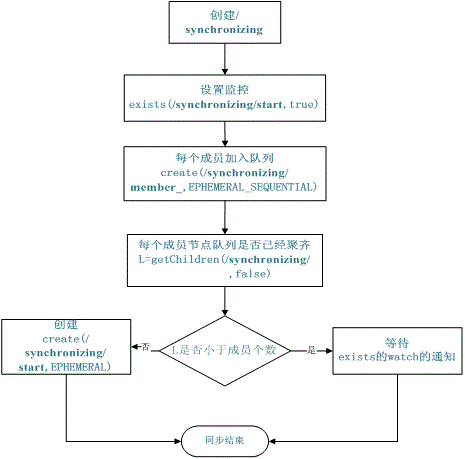
- 创建一个父目录
先进先出(分布式锁)
- 在特定的目录下创建
SEQUENTIAL类型的子目录/queue_i - 出队时通过
getChildren方法返回当前所有的队列中的元素,消费其中最小的一个
- 在特定的目录下创建