Starter
Kafka is a distributed, partitioned, replicated commit log service.
基于zookeeper协调的分布式日志系统(分布式发布-订阅消息系统,也可以当做MQ系统)
- 提供了类似于JMS的特性(与JMS不同:即使消息被消费,消息仍然不会被立即删除)
- 分布式,把写入压力均摊到各个节点。可以通过增加节点降低压力
- 依赖于zookeeper
- 每个Topic被创建后,在zookeeper上存放有其metadata(包含其分区信息、replica信息、LogAndOffset等)
- Producer可以通过zookeeper获得topic的broker信息,从而得知需要往哪写数据。
- Consumer也从zookeeper上获得该信息,从而得知要监听哪个partition
- Broker
- 集群中的KafkaServer
- 用来提供Partition服务,一个Broker上可以跑一个或多个Partition
- 集群中尽量保证partition的均匀分布
- Producer
- 将消息发布到指定的Topic中
- 每条消息都被append到Partition中,属于顺序写磁盘,因此效率非常高
- Consumer
- 负责从Partition读取消息
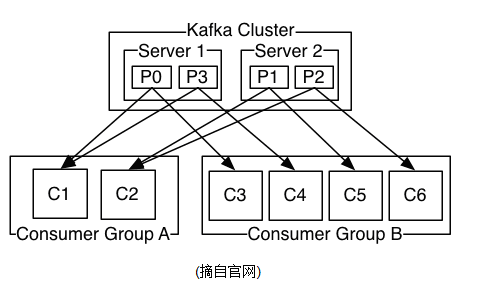
- ConsumerGroup
- 一个或多个Consumer构成
- 一个partition中的消息只会被group中的一个consumer消费
- Topic
- 消息管道
- 类似传统MQ的channel,例如同一业务用同一根管道
- Partition
- 车道 ,分区
- 每个Topic包含N多个Partition(Topic是拥有N个车道的高速公路)
- 每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件
- Offset
- Partition中消息顺序号
- Replica
- 在创建时,可以指定一个topic有几个partition,以及每个partition有几个复制
安装
直接下载解压,配置$KAFKA_HOME/config/server.properties
broker.id=1 # 全局唯一
port=9091 # 端口号
zookeeper.connect=192.168.0.1:2181,192.168.0.2:2182,192.168.0.3:2183 # 配置zookeeper
num.partitions=2 # 默认Partition数量
num.replica.fetchers=2 # 复制数量
log.dir=./logs # 日志/消息存放路径
...
PS:注意要安装Zookeeper
Cmd
启动Kafka (注意:先打开Zookeeper)
> bin/kafka-server-start.sh config/server.properties &创建Topic
> bin/kafka-topics.sh -create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test查看Topic
> bin/kafka-topics.sh --list --zookeeper localhost:2181 > bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic testPublish
> bin/kafka-console-producer.sh --broker-list localhost:9091 --topic testComsume
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginningZookeeper中查看
> bin/zkCli.sh -server localhost:port > ls /brokers > ls /brokers/topics
Java API
依赖包:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>${kafka.version}</version>
</dependency>
Producer:
Properties props = new Properties();
props.put("metadata.broker.list", "cj.storm:9092,cj.storm:9093,cj.storm:9094");
props.put("serializer.class", "kafka.serializer.StringEncoder");
ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String>(config);
KeyedMessage<String, String> msg = new KeyedMessage<String, String>("order", "test-kafka");
producer.send(msg);
producer.close();
Consumer:
Properties props = new Properties();
props.put("zookeeper.connect", "cj.storm:2181,cj.storm:2182,cj.storm:2183");
props.put("group.id", "test-consumer-group");
props.put("zookeeper.session.timeout.ms", "30000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
ConsumerConfig config = new ConsumerConfig(props);
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(config);
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put("order", new Integer(1));
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
//直接byte[]接收
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext())
System.out.println(new String(it.next().message()));
//使用String接收
Map<String, List<KafkaStream<String, String>>> consumerMap = consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
KafkaStream<String, String> stream = consumerMap.get("order").get(0);
ConsumerIterator<String, String> it = stream.iterator();
while (it.hasNext())
System.out.println(it.next().message());