Starter
Storm 流数据实时分析,主要用于实时分析,对分析时效要求较高的场景 (Spark 将来有可能替代Storm)
应用场景:
- 事件流处理(EventStream Processing)
- 持续计算 (Continuous Computation)
- 分布式RPC (Distributed RPC)
- eg: 金融市场(算法交易),交通车流,监控,临界分析(瞬间临界instant thershold,时间序列临界time series threshold)
| Storm | Hadoop |
|---|---|
| 流式处理 | 批处理 |
| 内存中先处理(先处理,数据可存可不存) | 先存后计算 |
| 适合在线实时场景,数据量比较小,处理速度快 | 比较适合离线数据分析场景,数据处理量可以达到PB,不适合实时或准实时场景 |
| 注重实时 | 注重数据的海量 |
| 数据多次处理一次写入 | 数据一次写入,多次处理使用(查询) |
| Storm系统运行起来后是持续不断的 | hadoop往往只是在业务需要时调用数据 |
| 上面你运行的是Topology(永远运行,除非显式杀掉) | 上面运行的是MapReduce的Job(最终会结束) |
Storm集群的基本组件
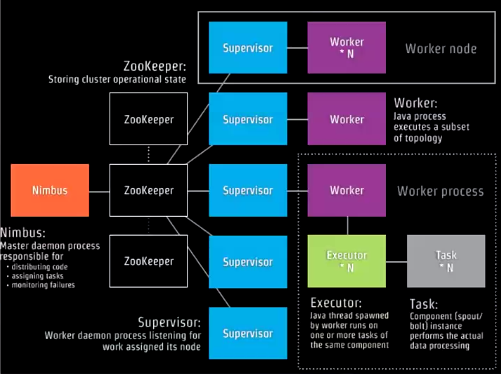
Nimbus:主控制节点,在集群里面分布代码,分配集群任务,监控集群状态等Zookeeper:协调Nimbus和Supervisor,存放公有数据(心跳信息,分配的任务,集群状态,配置信息等)Supervisor:监听Nimbus分配的任务,管理属于自己的Worker进程Worker:运行具体处理组件逻辑(Spout、Bolt)的进程
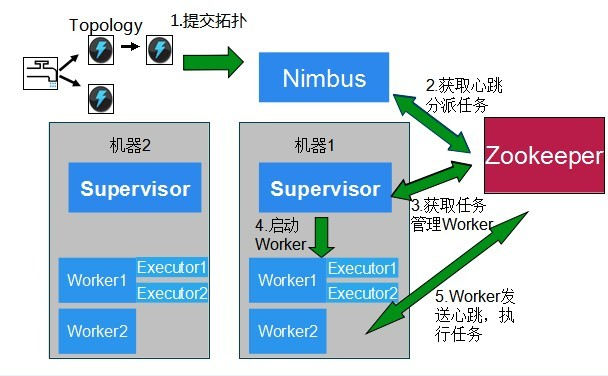
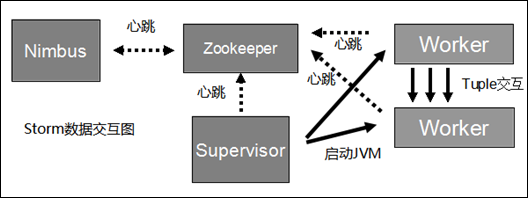
各节点上的目录结构:
Nimbus
- 用户上传topology定义(例如上传jar包,最终会变成stormjar-{uuid}.jar)
- nimbus建立topology本地目录
/{storm.local.dir} | | - /nimbus | | - /inbox | | - /stormjar-{uuid}.jar | - /stormdist | - /{topology-id} | - /stormjar.jar -- 包含此topology所有代码的jar包(从nimbus/inbox挪过来) | -/stormcode.ser -- 这个topology对象的序列化 | -/stormconf.ser -- 运行这个topology的配置
Zookeeper
- nimbus计算topology工作量(分成一个个task),在zookeeper中保存toplogy信息,建立心跳目录等
{storm.zookeeper.root} | | - /workerbeats -- 所有的Worker的心跳 | | - {topology-id} | - /supervisors -- 所有的Supervisors的心跳信息 | | - /{supervisor-id} | - /assignments -- 任务分配信息 | | - /{topology-id} | - /storms -- 正在运行的topology | | - /{topology-id} | - /errors -- 产生的出错信息 | | - /{topology-id}
- nimbus计算topology工作量(分成一个个task),在zookeeper中保存toplogy信息,建立心跳目录等
Supervisor
- 监听zookeeper
- 同步topology信息到supervisor本地
- 删除不再运行的topology本地信息
启动worker处理任务
- 去zookeeper上找其对应的task;
- 根据task的outbound信息建立对外的socket连接(将来发送tuple就是从这些socket连接发出去的);
/{storm.local.dir} | | - /supervisor | - stormdist | - {topology-id} | - stormjar.jar | - stormcode.ser | - stormconf.ser
- 监听zookeeper
环境搭建
- 搭建Zookeeper集群;
- 安装JDK
- 下载解压Storm;
- 修改
conf/storm.yaml配置文件;# 使用的Zookeeper集群地址 storm.zookeeper.servers: - "192.168.0.110" - "192.168.0.111" - "192.168.0.112" # nimbus机器地址(各supervisor节点需知道哪个机器是nimbus) nimbus.host: cj.storm # nimbus 或 supervisor 本地存储目录(注意对改目录需要有足够的访问权限) storm.local.dir: "/usr/local/storm/data" # supervisor 可以允许的worker(每个worker占用一个端口用于接收消息) # 默认情况下,每个节点上可运行4个workers,如下: supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 - 复制Storm到其他节点
> scp -rp storm/ cj@cj.storm1:/usr/local > scp -rp storm/ cj@cj.storm2:/usr/local - 开启Storm各个后台进程(注意需先启动Zookeeper:
zkServer.sh start)# 主节点上运行 > bin/storm nimbus & > bin/storm ui & > bin/storm logviewer &# 工作节点上运行 > bin/storm supervisor &# 查看 > jps
Cmd
启动nimbus
> bin/storm nimbus &启动supervisor
> bin/storm supervisor &启动storm ui ( 开启后可通过
http://{nimbus host}:8080观察集群的worker资源使用情况、Topologies的运行状态等信息)# Storm UI必须和Storm Nimbus部署在同一台机器上,否则UI无法正常工作,因为UI进程会检查本机是否存在Nimbus链接 > bin/storm ui &启动一个DRPC进程
> bin/storm drpc提交topology
# storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称] > bin/storm jar com.cj.storm.WordCountTopology wordCount杀死topology
#storm kill topology-name [-w wait-time-secs] > bin/storm kill wordCount暂停topology
> bin/storm deactivate topology-name激活topology
> bin/storm activate topology-name重新分配任务
# storm rebalance topology-name [-w wait-time-secs] > bin/storm rebalance wordCount查看所有topology运行情况
> bin/storm list
原语
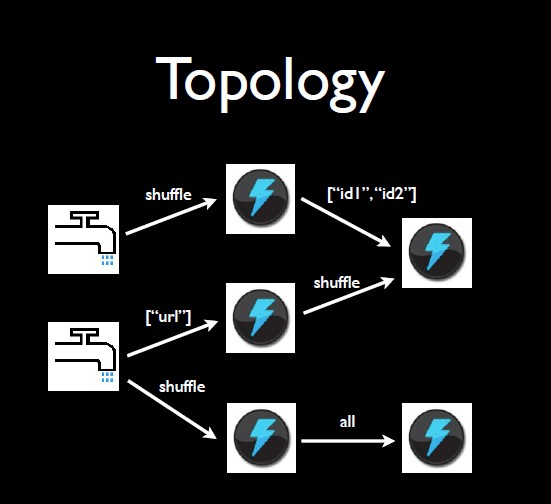
Topology
Topology 拓扑图(有向无环图):定义了Spout和Bolt的结合关系、并发数量、配置等等
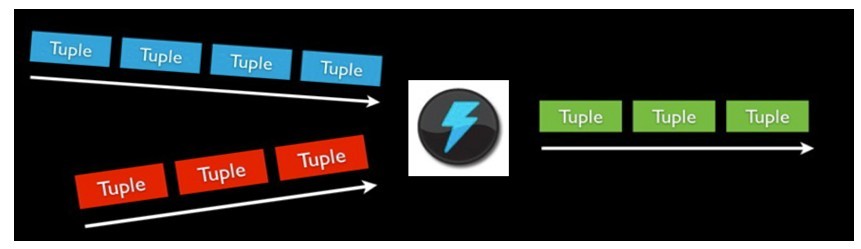
Spout- 数据源,源源不断的发送元组数据
Tuple
- 数据源,源源不断的发送元组数据
Bolt- 消费处理Tuple的节点,可并发
Tuple- 元组数据的抽象接口,可以是任何类型的数据(必须要可序列化)
- 可以包含多个Field,每个Field表示一个属性
- Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的Field已事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List
Stream- 没有边界的tuple序列(Tuple集合,一个Stream内的Tuple来自同一个Spout源)
- 流分组策略(Stream Grouping):告诉topology如何在两个组件之间发送tuple
Shuffle Grouping随机分组:随机派发stream里的tuple,保证每个bolt接收到的tuple数目大致相同Fields Grouping字段分组 :保证相同field值的tuple会被分配到同一个taskAll Grouping广播发送:将每一个Tuple发送到所有的TaskGlobal Grouping全局分组:整个stream分配到某个指定的taskNone Grouping不分组:效果同Shuffle GroupingDirect Grouping直接分组:直接将Tuple发送到指定的Task来处理(这种tuple必须使用emitDirect方法发送)Local or Shuffle Grouping本地或随机分组:优先使用同JVM可处理的taskCustom Grouping自定义分组
- 注意:
Fields Grouping字段分组- 相同的字段数据一定会跑到相同的对象(task)中
- 但这个对象(task)中不一定只有一种字段数据
- 可能多种字段数据分到了同一个对象(task)中
- eg: 相同的单词会跑到相同的Bolt instance (task)中,但不表示一个Bolt instance(task)中只有一种单词
Storm的现实模型就是水流的处理,例如小区供水:
- 数据来源定义为
Spout,源源不断的供给水流 - 水流在管道中流行,定义为
Stream - 每个住户都会消费水,是Stream中的一个节点,定义为
Bolt(可能会将消费的水排放,也或许不排) - 一个小区的
Spout、Stream、Bolt组合在一起,即一个拓扑结构,定义为Topology
- 数据来源定义为
并行度
并行度(Parallelism)
- Topology里面的每一个节点(spout/bolt)都是并行运行的
- 可以指定每个节点(spout/bolt)的并行度
- storm会在集群里面根据配置的并行度分配线程来同时计算
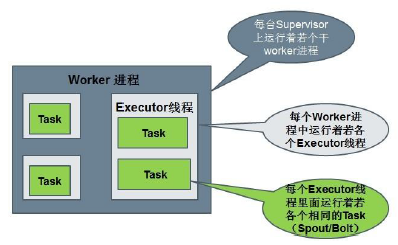
- Topology中的逻辑节点与物理节点:可以多对多
- 逻辑节点:Component(eg:spout/bolt)
- 物理节点(Supervisor Node)
- Worker(JVM) 进程
- Executors(Threads)线程池
- Executor(Thread) 线程
- Task (spout/bolt instance)
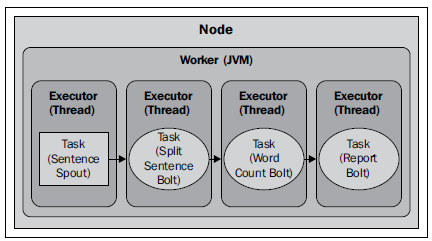
- 示例:单词统计
- Topology 逻辑图:

- Node(缺省)效果图:一个task代表一个component instance(spout/bolt),对应一个Executor(thread)
- Node(配置并行度后)效果图: 通过Storm Confugration 或 API进行修改并行度(Worker,Executor,Component instance个数)
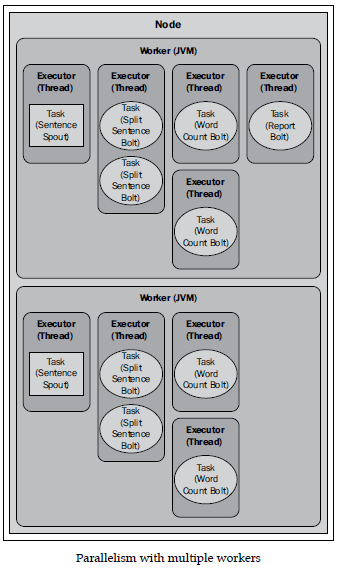
- Topology 逻辑图:
消息的可靠性处理
可靠性(Guarantee no data loss):
- Storm会告知用户每一个Tuple是否在一个指定的时间内被完全处理
- Storm通过
acker机制保证Spout发出的每一个Tuple都被完全处理 - 完全处理的意思是:某MessageId绑定的源Tuple以及由该源Tuple衍生的所有Tuple都经过了Topology中每一个应该到达的Bolt的处理,即
- tuple tree 不再生长
- tuple tree 中任何消息被表示为”已处理“
acker机制:
- Spout创建一个新的Tuple时,会发一个消息通知acker去跟踪;
- Bolt在处理Tuple成功或失败后,也会发一个消息通知acker;
- acker通过异或后ack_val是否为0,判定从Spout发出的Tuple是否已经被完全处理完毕
- acker找到发射该Tuple的Spout,回调其ack或fail方法;
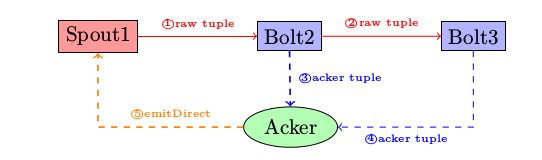
说明:
- acker是个Component(一般一个topology有一个acker,也可以通过配置参数指定多个)
- acker存储一个Map
- spout的taskId
- 用于acker在整个tuple树被完全处理后找到原始的Spout进行回调ack或fail
- ack_val 为消息传递过程中的 tupleid的xor值(一个64bit的随机数字)
- 用于标志该tuple是否被完全处理
- 如果为0,则会指定哪个spout或者bolt已经处理完了
- 原理:参考下文【tuple tree跟踪技术】
- spout的taskId
- tuple tree (源Tuple+新衍生的Tuple构成了一个Tuple树)跟踪技术:
- 原理:
- 异或处理: 与本身异或肯定为0 (
a xor a = 0) a xor b xor c xor a = b xor c, 相当于登记a,又把a删除掉
- 异或处理: 与本身异或肯定为0 (
- spout 发出tuple,设置一个初始id,开辟64bits空间,用来跟踪衍生tuples( 节省空间且速度快)
- 每个衍生tuple有一个id,登记(xor一次),删除(再xor一次),最终64bits为0表示都所有衍生tuple都处理完毕了
- 注意:tuple的id可能会重复,造成误判错误的几率为 1/2(64),即2的64次方分之一,很小
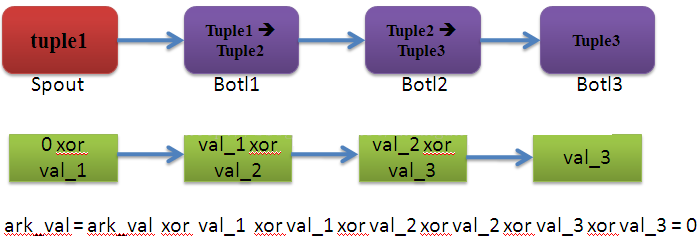
- 原理:
实现:
- Spout 发送Tuple时指定一个id(也就是回调回ack和fail方法的参数msgId)
nextTuple():_collector.emit(new Values(xxx),msgId);ack(msgId)fail(msgId)
- Bolt 发送衍生Tuple时需锚定输入Tuple
execute(...):_collector.emit(tuple,new Values(xxx)); _collector.ack(tuple);
- 注意:
- 一个消息只会由发送它的那个spout任务来调用ack或fail。
- 如果系统中某个spout由多个任务运行,消息也只会由创建它的spout任务来应答(ack或fail),决不会由其他的spout任务来应答。
关闭(允许丢失一些信息):可减少消息数量(每个消息不需要应答了)和大小(每个tuple不用记录跟id了)
- 设置topology的acker为0个:参数
Config.TOPOLOGY_ACKERS设置为0(此时当Spout发送一个消息的时候,它的ack方法将立刻被调用) - 在Spout的
nextTuple方法中不指定此消息的id (当需要关闭特定消息可靠性的时候,可以使用此方法) - 在Bolt的
emit方法中不锚定输入消息(关闭某个消息派生出来的子孙消息的可靠性)
记录级容错
集群的各级容错
- 任务级失败
bolt task crash=> acker中与此bolt关联的消息因超时而失败,spout的fail调用acker task fail=> 所持有的所有消息因超时而失败 -> spout的fail调用spout task fail=> spout对接的外部设备负责消息的完整性
- 任务槽(slot)故障
worker broken=> supervisor 监控,尝试重启supervisor broken=> supervisor是无状态的,不影响当前运行任务,不自举 ,需外部监控重启nimbus broken=> nimbus是无状态的,不影响当前运行任务,但无法提交新任务,不自举 -> 需外部监控重启
- 集群节点(机器 node)故障
storm node broken=> nimbus 将运行任务转移到其他nodezookeeper node broken=> 保证少于半数node仍可正常运行,人员及时修复broken node
storm集群中除nimbus外,没有单点存在,任何节点都可以出故障而保证数据不会丢失。 nimbus/supervisor 被设计为无状态的,只要可以及时重启,就不会影响正在运行的任务
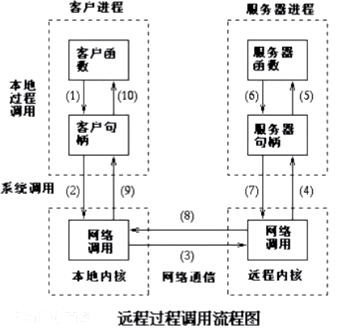
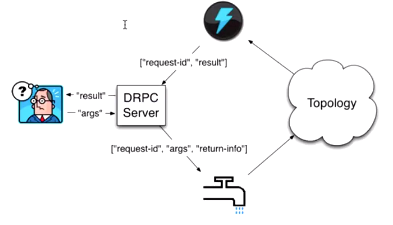
DRPC
DRPC其实不能算是storm本身的一个特性, 它是通过组合storm的原语spout,bolt, topology而成的一种模式(pattern)
DRPC 使得我们可以从一个Client调用storm集群的资源,并不一定要连接到storm集群的某一个节点来提交topology
Trident
构建在Storm框架上的一个更高Level的抽象(基于原生Storm API的高级封装,类似与MapReduce的Pig框架),屏蔽了事务处理,批量处理的细节 就是在Storm的Stream处理模式上,对底层原语(Spout,Bolt等)进行进一步抽象,实现了一些常见的业务逻辑的支持,让开发者更方便的使用Storm(如Join/Filter/Aggregation/Grouping等)
- Trident 核心操作对象:
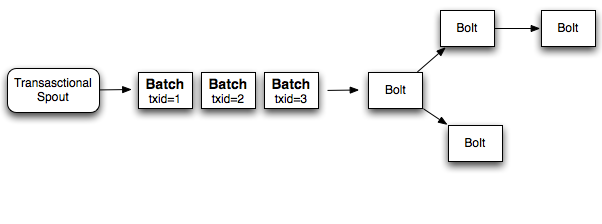
stream- 一个stream包含一系列batch
- 一个batch包含一系列tuple
- Trident在处理输入stream的时候会把输入转换成若干个tuple的
batch来处理(Trident spouts must emit tuples in batches.) - Trident提供了一系列非常成熟的批量处理的API来处理这些batch(且保证tuple只被处理一次)
- 处理batches中间结果存储在
TridentState对象中
- 在Storm集群节点间,一个stream被划分成很多分区(
partition)- 对流(stream)的操作(operation)是在每个partition上并行执行的
- 在Storm中并发的最小执行单元是task;在trident中partition相当于task的角色
- 一个partition里面可能有多个batch
- 一个batch也可能位于不同的partition上
事务处理
- 把一个batch的计算分成两个阶段:
processing阶段: 可以同时处理多个batch,不用保证顺序性(这个阶段很多batch可以并行计算)commit阶段: 保证batch的强顺序性,并且一次只能处理一个batch,第1个batch成功提交之前,第2个batch不能被提交(这个阶段各个batch之间需要有强顺序性的保证)- 许多batch可以在processing阶段的任何时刻并行计算,但是只有一个batch可以处在commit阶段
- 如果一个batch在processing或者commit阶段有任何错误, 那么此batch需要被replay
- Storm通过acker机制判断一个batch是否被成功处理了,失败会replay对应的batch (无需手动设置ack)
- 所以需要一个可以完全重发(replay)一个特定batch的消息的队列系统(Message Queue),例如kafka
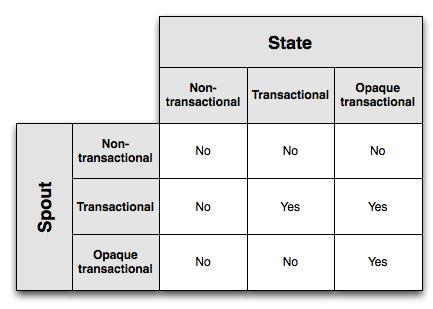
- 事务类型:事务型、非事务型和透明事务型
- spout的事务类型:指定了由于下游出现问题导致元组需要重放时,应该怎么发送元组
- 事务型:重放时能保证同一个批次发送同一批元组。可以保证每一个元组都被发送且只发送一个,且同一个批次所发送的元组是一样的
- 非事务型:没有任何保障,发完就算
- 透明事务型:保证每一个元组都被发送且只发送一次,但不能保证重放时同一个批次的数据是一样的
- state的事务类型:指定了如果将storm的中间输出或者最终输出持久化到某个地方(如内存),当某个批次的数据重放时应该如果更新状态
- 事务型状态:同一批次tuple提供的结果是相同的。
- 非事务型状态:没有回滚能力,更新操作是永久的。
- 透明事务型状态:更新操作基于先前的值,这样由于这批数据发生变化,对应的结果也会发生变化
- spout的事务类型:指定了由于下游出现问题导致元组需要重放时,应该怎么发送元组
Trident有五大类操作(operation):
Partition-local-- 对每个partition的局部操作(本地的操作),不产生网络传输(例如:function、filter、partitionAggregate、stateQuery、partitionPersist、project等)- function
Input Output Fields a b c a b c d Values [ 1 2 3 ] [ 1 2 3 0 ],[ 1 2 3 1 ] Values [ 4 1 6 ] [ 4 1 6 0 ] Values [ 3 0 8 ] / - filter
Input Tuple Output Tuple Fields a b c a b c Values [ 1 2 3] / Values [ 2 1 1] [ 2 1 1] Values [ 2 3 4] / - Projection
Input Tuple Output Tuple Fields a b c b c Values [ 1 2 3] [2,3] Values [ 2 1 1] [ 1,2] Values [ 2 3 4] [3,4] - partitionAggregate
- 对每个partition执行一个function操作(实际上是聚合操作),最后把局部聚合值emit出来,通过网络传输供后面使用
- 由 partitionAggregate发送出的 tuple 会将输入 tuple 的域替换

- persistentAggregate
- 对源源不断发送过来数据流做一个总的聚合,每个批次(batch)的聚合值只是一个中间状态
- 通过与trident新提出的state概念结合,实现中间状态的持久化,同时支持事务性
- 只能使用CombinerAggregator或者ReducerAggregator (不能使用Aggregator)
- partitionPersist
- 是一个接收 Trident 聚合器作为参数并对 state 数据源进行更新的方法
- persistentAggregate 就是构建于 partitionPersist 上层的一个编程抽象
- stateQuery
- 按批次对持久化的数据做查询
- function
Repartitioning-- 对stream的重新划分(仅仅是划分,不改变stream内容),产生网络传输- shuffle:随机将tuple均匀地分发到目标partition里。
- broadcast:每个tuple被复制到所有的目标partition里,在DRPC中有用 — 你可以在每个partition上使用stateQuery。
- partitionBy:对每个tuple选择partition的方法是:(该tuple指定字段的hash值) mod (目标partition的个数),该方法确保指定字段相同的tuple能够被发送到同一个partition。(但同一个partition里可能有字段不同的tuple)
- global:所有的tuple都被发送到同一个partition。
- batchGlobal:确保同一个batch中的tuple被发送到相同的partition中。
- patition:该方法接受一个自定义分区的function(实现CustomStreamGrouping)
Aggregation-- 聚合,可能产生网络传输- aggregate:对流做全局聚合
- 每个批次(batch)的流只能在1个partition中执行,并不能实现并发的功能
- 当使用ReduceAggregator或者Aggregator聚合器时,流先被重新划分成一个大分区(仅有一个partition),然后对这个partition做聚合操作;
- 当使用CombinerAggregator时,Trident首先对每个partition局部聚合,然后将所有这些partition重新划分到一个partition中,完成全局聚合。
- 相比而言,CombinerAggregator更高效,推荐使用
- aggregate:对流做全局聚合
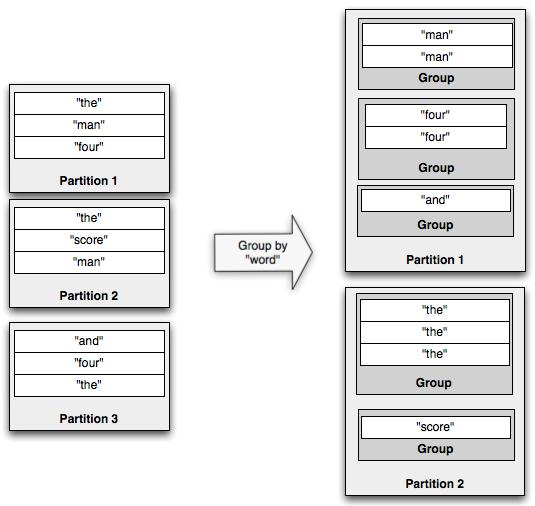
on grouped streams-- 作用在分组流上的操作- groupby
- 先对流中的指定字段做partitionBy操作,让指定字段相同的tuple能被发送到同一个partition里。
- 然后在每个partition里根据指定字段值对该分区里的tuple进行分组
- groupby
Merge & Join-- stream间的合并和连接(根据tuple的域Field)- merge 合并两个Stream所有Field
- join 依某Field连接两个Stream
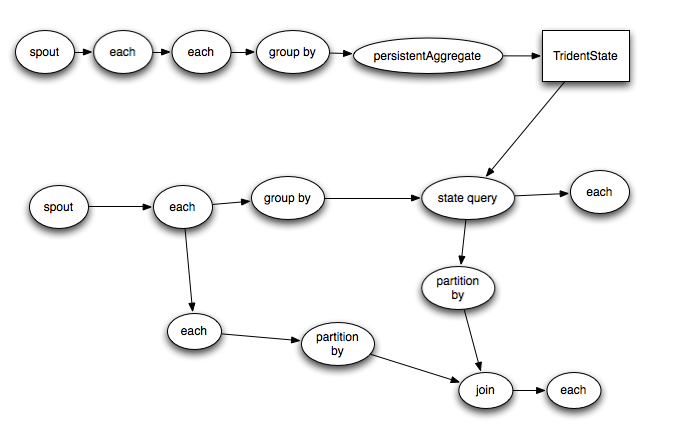
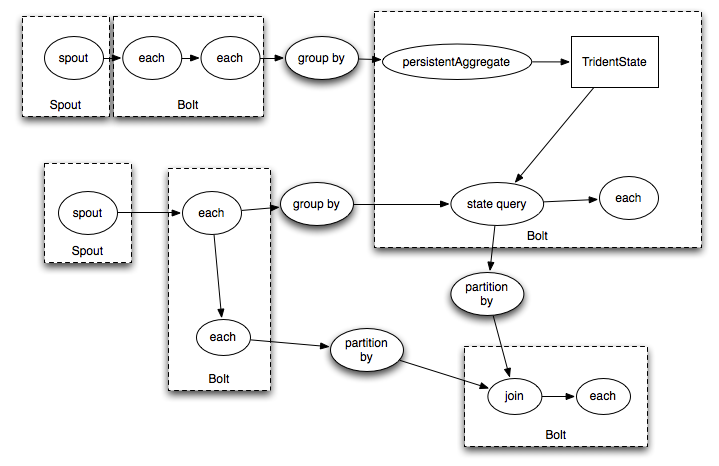
应用示例
Java API
依赖包:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm</artifactId>
<version>${storm.version}</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
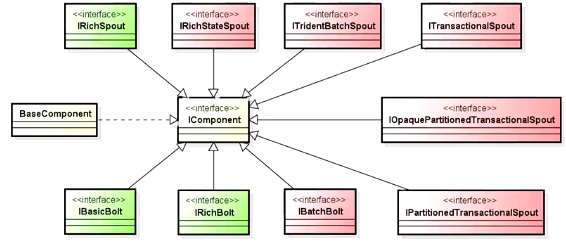
- interface
IComponent- void declareOutputFields(OutputFieldsDeclarer declarer);
- Map
- interface
ISpout- void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
- void activate();
- void nextTuple(); //循环调用
- void ack(Object msgId);
- void fail(Object msgId);
- void deactivate();
- void close();
- interface
IBolt- void prepare(Map stormConf, TopologyContext context, OutputCollector collector);
- void execute(Tuple input); //循环调用
- void cleanup();
- interface
IRichSpoutextends ISpout, IComponent - interface
IRichBoltextends IBolt, IComponent interface
IBasicBoltextends IComponent- void prepare(Map stormConf, TopologyContext context);
- void execute(Tuple input, BasicOutputCollector collector); //循环调用
- void cleanup();
说明:
- 提交Topology后:
- 执行各Component的
construct方法 - 执行各Component的
declareOutputFields方法 - 执行Spout的
open,activate方法 & Bolt的prepare方法(只执行一次) - 执行Spout的
nextTuple& Bolt的execute方法 (不断循环执行) - 执行Spout的
ack或fail方法(使用ack机制发送tuple,在每一个tuple tree完成后触发)
- 执行各Component的
IRichBolt与IBasicBolt的区别在于:后者会自动ackpublic class SplitSentence extends BaseRichBolt{ OutputCollector _collector; @Override public void prepare(Map conf,Topology context,OutputCollector collector){ _collector=collector; } @Override public void execute(Tuple tuple){ String sentence=tuple.getString(0); for(String word:sentence.split(" ")){ _collector.emit(tuple,new Value(word)); //发送tuple } _collector.ack(tuple); //手动ack } @Override public void declareOutputFields(OutputFieldDeclarer declarer){ declarer.declare(new Fields("word")); } }public class SplitSentence extends BaseBaseBolt{ @Override public void execute(Tuple tuple,BasicOutputCollector collector){ String sentence=tuple.getString(0); for(String word:sentence.split(" ")){ _collector.emit(tuple,new Value(word)); //发送tuple } } @Override public void declareOutputFields(OutputFieldDeclarer declarer){ declarer.declare(new Fields("word")); } }TridentTopology:可接入3种spout,创建stream- 非事务类型:
IBathSpout - 事务类型:
ITridentSpout,IPartitionedTridentSpout - 非透明事务类型:
IOpaquePartitionedTridentSpout
- 非事务类型:
- 提交Topology后:
构建topology,即
StormTopology对象- 使用
TopologyBuilder(Spout & Bolt原语)TopologyBuilder builder=new TopologyBuilder(); builder.setSpout(...); builder.setBolt(...); ... builder.createTopology(); - 使用
TridentTopology(Trident原语)TridentTopology topology=new TridentTopology(); topology.newStream(...) ... .build();
- 使用
提交topology
- 提交给正式storm集群,使用
StormSubmitter- StormSubmitter.submitTopology(topologyName, stormConf, topology);
- 提交给本地虚拟集群,使用
LocalCluster(一般用于测试)- (new LocalCluster()).submitTopology(topologyName, stormConf, topology);
- 提交给正式storm集群,使用
使用Spout&Bolt原语
示例:单词统计 (根据配置,从指定路径读取文件行作为输入源,这里未使用ack机制)
wordReader => wordSpliter => wordCounter
(Spout,1) (Bolt,2) (Bolt,3)
public static void main(String[] args)
{
if(args.length!=2){
System.err.println("Set Args!");
return;
}
TopologyBuilder builder=new TopologyBuilder();
builder.setSpout("wordReader", new WordReaderSpout());
builder.setBolt("wordSpliter",new WordSpliterBolt(),2).shuffleGrouping("wordReader");
builder.setBolt("wordCounter",new WordCounterBolt(),3).fieldsGrouping("wordSpliter",new Fields("word"));
Config config=new Config();
config.put("INPUT_PATH",args[0]);
config.put("TIME_OFFSET",args[1]);
config.setDebug(false);
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("WordCountTopology", config,builder.createTopology());
}
WordReaderSpout:
public class WordReaderSpout extends BaseRichSpout{
private static final long serialVersionUID = 4838334026285320050L;
private SpoutOutputCollector collector;
private String inputPath;
@Override
public void open(@SuppressWarnings("rawtypes") Map conf, TopologyContext context,SpoutOutputCollector collector){
this.inputPath=(String)conf.get("INPUT_PATH");
this.collector=collector;
}
@Override
public void nextTuple(){
Collection<File> files=FileUtils.listFiles(new File(inputPath),
FileFilterUtils.notFileFilter(FileFilterUtils.suffixFileFilter("bak")), null);
try{
for(File file:files){
List<String> lines=FileUtils.readLines(file);
for(String line:lines)
collector.emit(new Values(line)); //发送一行句子
FileUtils.moveFile(file,new File(file.getPath()+System.currentTimeMillis()+".bak"));
}
} catch (IOException e){
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("line"));
}
}
WordSpliterBolt:
public class WordSpliterBolt extends BaseBasicBolt{
private static final long serialVersionUID = -3841856624992471803L;
@Override
public void execute(Tuple input, BasicOutputCollector collector){
String line=input.getString(0);
String[] words=line.split("\\s+");
for(String word:words){
collector.emit(new Values(word)); //发送一个单词
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("word"));
}
}
public class WordCounterBolt extends BaseBasicBolt{
private static final long serialVersionUID = -3841856624992471803L;
private Map<String,Integer> counts=new HashMap<String,Integer>();
private SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
public void prepare(@SuppressWarnings("rawtypes") Map stormConf, TopologyContext context,OutputCollector collector){
final Long timeOffset=Long.parseLong((String)stormConf.get("TIME_OFFSET"));
new Thread(new Runnable(){
@Override
public void run() {
while(true){
System.out.println(sdf.format(new Date())+"------------------");
for(String key:counts.keySet())
System.out.println(key+" "+counts.get(key));
try{
Thread.sleep(timeOffset*1000);
} catch (InterruptedException e){
e.printStackTrace();
}
}
}
}).start();
}
@Override
public void execute(Tuple input, BasicOutputCollector collector){
String word=input.getString(0).toLowerCase();
if(counts.containsKey(word))
counts.put(word, (counts.get(word)+1));
else
counts.put(word,1);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("word","count"));
}
}
使用Trident
Main: submit topology
public static void main(String[] args) throws Exception {
Config config=new Config();
config.setDebug(false);
if (args != null && args.length > 0) {
config.setNumWorkers(2);
StormSubmitter.submitTopology(args[0], config, buildTopology(null));
} else {
config.setMaxTaskParallelism(3);
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("word2-topology",config, buildTopology());
}
}
buildTopology:
public static StormTopology buildTopology(){
//使用FixedBatchSpout创建一个输入spout,spout的输出字段为sentence,每3个元组作为一个batch
FixedBatchSpout spout=new FixedBatchSpout(new Fields("sentence"), 3,
new Values("China America Japan Italy America"),
new Values("Korea Italy Netherlands China"),
new Values("France America Italy"),
new Values("Japan China Korea"),
new Values("France Netherlands America"),
new Values("America Korea Netherlands Japan"));
//数据是否不断的重复发送
spout.setCycle(false);
TridentTopology topology=new TridentTopology();
//方式一:aggregate for batch tuples on each batches.
topology.newStream("word-spout", spout)
.each(new Fields("sentence"), new SplitFunction(),new Fields("word"))
.groupBy(new Fields("word"))
.aggregate(new Fields("word"), new BatchCount(), new Fields("count")).parallelismHint(3)
.each(new Fields("count"),new PrintFilter())
;
//方式二:partitionAggregate for all batch tuples on each partitions.
topology.newStream("word-spout", spout)
.each(new Fields("sentence"), new SplitFunction(),new Fields("word"))
.partitionBy(new Fields("word"))
.partitionAggregate(new Fields("word"),new BatchCount(), new Fields("count")).parallelismHint(3)
.each(new Fields("count"),new PrintFilter())
;
return topology.build();
}
Function:SplitFunction
public class SplitFunction extends BaseFunction{
private static final long serialVersionUID = -3520791925362776023L;
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence=tuple.getString(0);
String[] words=sentence.toLowerCase().split("\\s+");
for(String word:words){
if(word!=null && word.length()!=0)
collector.emit(new Values(word));
}
}
}
Aggregator:BatchCount
public class BatchCount extends BaseAggregator<Map<String,Long>>{
private static final long serialVersionUID = -6887898093280014532L;
@Override
public Map<String, Long> init(Object batchId, TridentCollector collector) {
System.out.println("batchId:"+batchId);
return new HashMap<String,Long>();
}
@Override
public void aggregate(Map<String, Long> val, TridentTuple tuple,
TridentCollector collector) {
String key=tuple.getString(0);
Long value=val.get(key);
val.put(tuple.getString(0), (value==null?0L:value)+1);
}
@Override
public void complete(Map<String, Long> val, TridentCollector collector) {
collector.emit(new Values(val));
}
}
Filter:PrintFilter
public class PrintFilter extends BaseFilter{
private static final long serialVersionUID = 4222174314803471311L;
private int partitionIndex;
@Override
public void prepare(Map conf, TridentOperationContext context) {
this.partitionIndex = context.getPartitionIndex();
}
@Override
public boolean isKeep(TridentTuple tuple) {
System.out.println("partition [" + partitionIndex + "]: " + tuple.getValues());
return true;
}
}
使用TridentState
buildTopology:使用persistentAggregate返回的是TridentState对象
//此流程用于统计单词数据
TridentState countState= topology.newStream("word-spout", spout)
.each(new Fields("sentence"), new SplitFunction(),new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(3)
//.newValuesStream()
//.each(new Fields("word","count"),new PrintFilter())
;
//另一流程:查询上面的统计结果
topology.newDRPCStream("words",drpc)
.each(new Fields("args"),new SplitFunction(),new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(countState, new Fields("word"),new MapGet(), new Fields("count"))
//.aggregate(new Fields("word"), new Count(), new Fields("count"))
.each(new Fields("word","count"),new PrintFilter())
;
return topology.build();
CombinerAggregator:Count
public static class Count implements CombinerAggregator<Long> {
private static final long serialVersionUID = -2368597420284085245L;
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}
测试:
Config config=new Config();
config.setDebug(false);
config.setMaxTaskParallelism(3);
LocalCluster cluster=new LocalCluster();
LocalDRPC drpc=new LocalDRPC();
cluster.submitTopology("word2-topology",config, buildTopology(drpc));
for (int i = 0; i < 6; i++) {
System.out.println("DRPC RESULT: " + drpc.execute("words", "China Japan Italy"));
Thread.sleep(100);
}
使用Kafka做消息源
加入依赖包:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>${kafka.version}</version>
</dependency>
示例:
使用KafkaSpout:
public static void main(String[] args) {
BrokerHosts brokerHosts=new ZkHosts("cj.storm:2181,cj.storm:2182,cj.storm:2183");
SpoutConfig spoutConfig=new SpoutConfig(brokerHosts, "sentence", "/sentence", "id");
//kafkaConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConfig.scheme=new SchemeAsMultiScheme(new RecordScheme("message"));
TopologyBuilder builder=new TopologyBuilder();
builder.setSpout("wordReader", new KafkaSpout(spoutConfig)());
//setBolt
...
//submit topology
...
}
使用TransactionalTridentKafkaSpout:
public static void main(String[] args) {
BrokerHosts brokerHosts=new ZkHosts("cj.storm:2181,cj.storm:2182,cj.storm:2183");
TridentKafkaConfig spoutConfig=new TridentKafkaConfig(brokerHosts, "sentence", "/sentence", "id");
//kafkaConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConfig.scheme=new SchemeAsMultiScheme(new RecordScheme("message"));
TridentTopology topology = new TridentTopology();
StormTopology stormTopology=topology.newStream("wordReader", new TransactionalTridentKafkaSpout(spoutConfig)())
....
.build();
//submit topology
...
}
RecordScheme: 实现Scheme接口,它主要负责从消息流中解析出需要的数据
public class RecordScheme implements Scheme{
private static final long serialVersionUID = 1246495372611050401L;
private String schemeKey="msg";
public RecordScheme(String schemeKey){
this.schemeKey=schemeKey;
}
public List<Object> deserialize(byte[] bytes) {
try {
String str=new String(bytes, "UTF-8");
return new Values(str);
} catch (UnsupportedEncodingException e) {
System.out.println(e.getMessage());
return null;
}
}
@Override
public Fields getOutputFields() {
return new Fields(schemeKey);
}
}