Hadoop
Nobody wants data,what they want are the answers
概述
适合
大数据的,分布式,存储(HDFS)与计算(MapReduce)平台HDFS: Hadoop Distributed File System 分布式文件系统- 思想
- 单次写入,多次读取 (不支持并发写,可追加,不可原内容修改)
- 以Block存储,多副本
- 面向大文件存储(小文件不合适)
- 主从结构
- namenode(1) -- 管理(接收请求,存储元数据)
- secondNamenode(1) -- 辅助管理(存储元数据快照)
- datanode(n) -- 存储数据(block)
- 思想
MapReduce: Engine+Logic 并行计算框架,处理计算HDFS中的数据- 思想
- 分而治之
- mapper(Data-Local,尽可能移动计算到数据端)+ reducer
- 主从结构
- jobTracker(1) -- 管理(接收、分配、监控任务)
- taskTracker(n)-- 执行任务(mapper或reducer)
- 思想
YARN: Yet Another Resource Negotiator 资源管理调度系统 (Hadoop2.x加入)特点(分布式特点)
- 扩容能力(Scalable)
- 能可靠地存储和处理千兆字节(PB)数据
- 成本低(Economical)
- 可以通过普通机器组成的服务器群来分发以及处理数据
- 服务器群可达数千个节点
- 高效率(Efficient)
- 可在的节点上并行地处理数据
- 可靠性(Reliable)
- 自动维护数据的多份副本
- 在任务失败后能自动地重新部署计算任务
- 扩容能力(Scalable)
版本说明
Apache Hadoop
- 0.20.2 => hadoop 1.x
- 0.23.0 => hadoop 2.x
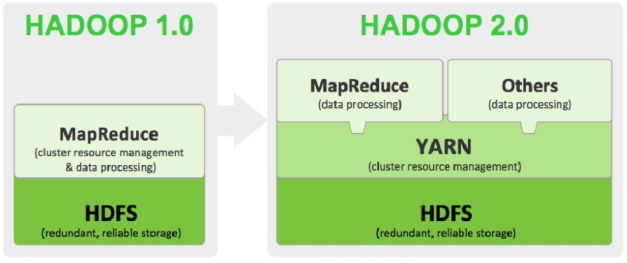
Hadoop 1.x
- HDFS (分布式文件系统)
- MapReduce (离线计算框架)
Hadoop 2.x
- HDFS (支持NameNode横向扩展)
- MapReduce (运行在YARN上)
- YARN (资源管理系统)
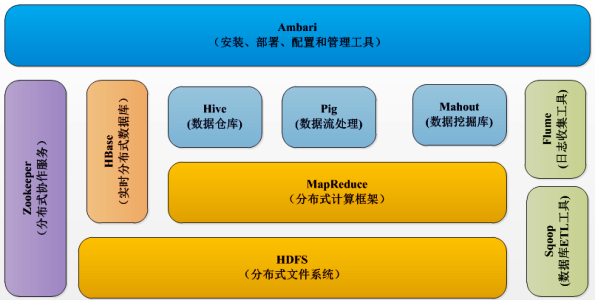
生态系统
Hadoop1.x 生态系统
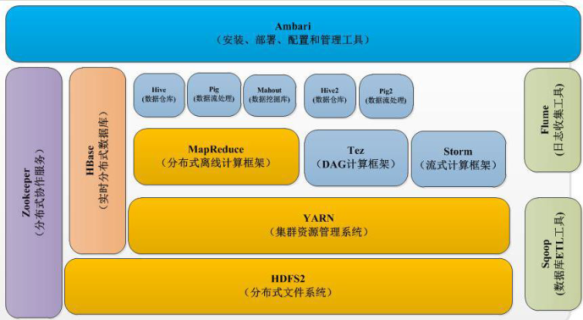
Hadoop2.x 生态系统
安装部署
- 本地模式
- 本地运行
- 只负责存储,没有计算功能
- 伪分布模式
- 在一台机器上模拟分布式部署
- 方便学习和调试
- 集群模式
- 在多个机器上配置 hadoop
- 是真正的“分布式”
部署进程说明:
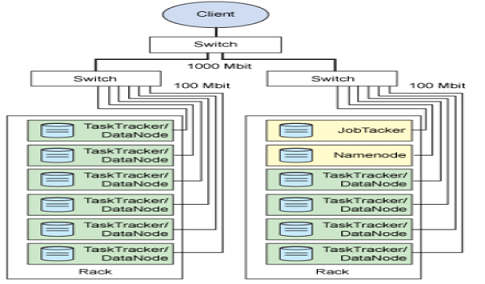
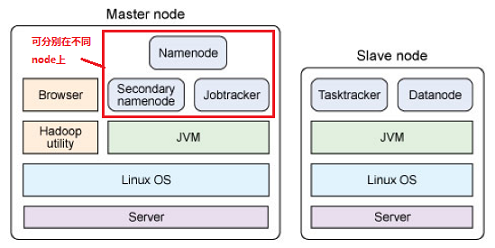
DataNode(HDFS)与TaskTracker(MapReduce),共享一个节点(Slave,可多个)NameNode(HDFS)与JobTracker(MapReduce),可在同一个或两个不同的节点(Master)NameNode(HDFS)与SecondaryNameNode(HDFS),尽量安排在两个不同的节点(Master)部署逻辑图
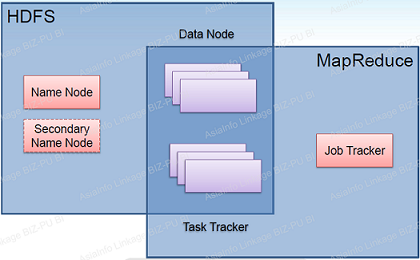
- 集群的物理分布
- 单个节点中的物理结构
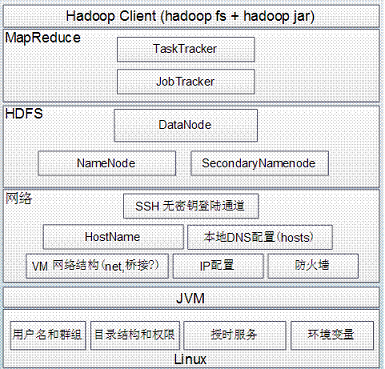
- Hadoop 组件依赖关系
环境准备
Linux环境设置
- 关闭iptables :
service iptables stop> service iptables status > service iptables stop > chkconfig iptables off > chkconfig --list | grep iptables - 设置hostname:
/etc/sysconfig/network> hostname cj > vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=cj > restart 设置静态ip:
/etc/sysconfig/network-scripts/ifcfg-eth0> vi /etc/sysconfig/network-scripts/ifcfg-eth0 ... BOOTPROTO=static IPADDR=10.40.33.100 NETMASK=255.255.255.0 ... > service network restart > ifconfig设置DNS(绑定hostname & ip ):
/etc/hosts(windows下:C:\windows\system32\drivers\etc\hosts)> vi /etc/hosts 10.40.33.100 cj.storm cj ... # 其他节点
- 关闭iptables :
JVM 安装
- rpm安装
rpm -ivh xxx.rpm> rpm -ivh jdk-8u45-linux-x64.rpm # 默认安装到/usr/java > rpm -q --whatprovides java - 配置环境变量(JAVA_HOME,PATH):
/etc/profile> vi /etc/profile export JAVA_HOME=/usr/java/jdk1.8.0_45 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar > source /etc/profile - 测试是否安装成功
javac> java -version > javac -version
- rpm安装
Hadoop 用户
> groupadd hadoop > useradd -g hadoop hadoop > passwd hadoopSSH 免密码登录
- 切换用户:
su xxx> su hadoop - 生成两个钥匙(公有,私有):
ssh-keygen -t rsa> mkdir .ssh > cd .ssh > ssh-keygen -t rsa > ls id_rsa,id_rsa.pub - 将公有钥匙添加到authorized_keys:
cp id_rsa.pub >> authorized_keys> cp id_rsa.pub >> authorized_keys - 权限修改:
chmod> chmod 744 /home/hadoop > chmod 700 /home/hadoop/.ssh > chmod 644 /home/hadoop/.ssh/authorized_keys - 验证(第一次需要输入密码,以后就不用了):
ssh localhost> ssh localhost > ssh -v localhost # ouput debug infomation > exit - 注意:如果
authorized_keys文件、$HOME/.ssh目录 或 $HOME目录让本用户之外的用户有写权限,那么sshd都会拒绝使用~/.ssh/authorized_keys文件中的key来进行认证的
- 切换用户:
Hadoop1.x 安装
安装Hadoop
- 上传并解压
> tar -zxvf hadoop-1.2.1.tar.gz -C /home/hadoop/ - 配置环境变量(HADOOP_INSTALL,PATH):
/etc/profile> vi /etc/profile export HADOOP_INSTALL=/home/hadoop/hadoop-1.2.1 export PATH=$PATH:$HADOOP_INSTALL/bin > source /etc/profile
- 上传并解压
配置
hadoop-env.sh(配置JAVA_HOME)export JAVA_HOME=/usr/javacore-site.xml<configuration> <!-- 指定hadoop运行时产生文件的存放目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp</value> </property> <!-- 指定HDFS的namenode的通信地址 --> <property> <name>fs.default.name</name> <value>hdfs://cj.storm:9000</value> </property> <!-- 指定HDFS的secondNamenode的存放目录 --> <property> <name>fs.checkpoint.dir</name> <value>/home/hadoop/data1/namesecondary</value> </property> </configuration>hdfs-site.xml<configuration> <!-- HDFS 元数据存放目录--> <property> <name>dfs.name.dir</name> <value>/home/hadoop/data1/hdfs/name</value> </property> <!-- HDFS Block存放目录--> <property> <name>dfs.data.dir</name> <value>/home/hadoop/data1/hdfs/data</value> </property> <!-- HDFS Block Size 默认为64M--> <property> <name>dfs.block.size</name> <value>8388608</value> </property> <!-- HDFS block 副本数,伪分布式下必须为1 --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- HDFS 文件系统权限控制--> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>mapred-site.xml<configuration> <!-- 指定jobtracker地址 --> <property> <name>mapred.job.tracker</name> <value>cj.storm:9001</value> </property> </configuration>
启用进程
- 初始化(namenode格式化,第一次时):
hadoop namenode -format - 启动所有:
start-all.sh - 退出安全模式:
hadoop dfsadmin -safemode leave - 启动某个进程:
hadoop-daemon.sh start xxx - 关闭所有:
stop-all.sh - 关闭某个进程:
hadoop-daemon.sh stop xxx
- 初始化(namenode格式化,第一次时):
验证
- 进程查看:
jps - web访问
- HDFS (NameNode: http://cj.storm:50070,SecondNameNode: http://cj.storm:50090)
- MapReduce (JobTracker: http://cj.storm:50030,TaskTracker: http://cj.storm:50060)
- 注意:在windows下需维护linux主机名和IP的映射关系(
C:\Windows\System32\drivers\etc)
- HDFS查看 :
hadoop fs -lsr / - MapReduce测试 :
hadoop jar $HADOOP_HOME/hadoop-examples-1.2.1.jar pi 10 100 - 日志查看 :
ls $HADOOP_HOME/logs/*-cj.log
- 进程查看:
Hadoop2.x 安装
安装Hadoop
- 上传并解压
> tar -zxvf hadoop-2.7.2.tar.gz -C /home/hadoop/ - 配置环境变量(HADOOP_INSTALL,PATH):
/etc/profile> vi /etc/profile export HADOOP_INSTALL=/home/hadoop/hadoop-2.7.2 export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin > source /etc/profile
- 上传并解压
配置
hadoop-env.sh(配置JAVA_HOME)export JAVA_HOME=/usr/javacore-site.xml(同Hadoop1.x)hdfs-site.xml(同Hadoop1.x)mapred-site.xml<configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>yarn-site.xml<configuration> <!-- 指定YARN的老大(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>cj.storm</value> </property> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
启用进程
- 先启动HDFS:
start-dfs.sh - 再启动YARN:
start-yarn.sh
- 先启动HDFS:
验证
- 进程查看:
jps - web访问
- HDFS (http://cj.storm:50070)
- MapReduce (http://cj.storm:8088)
- 注意:在windows下需维护linux主机名和IP的映射关系(
C:\Windows\System32\drivers\etc)
- 进程查看:
集群模式部署
示例:
3个节点
- Master:NameNode,SecondeNameNode,JobTracker -- cj.storm
- Slave1:DataNode,TaskTracker -- user1.storm
- Slave2:DataNode,TaskTracker -- user2.storm
某个hadoop节点配置master和slave信息:
vi masters配置secondnamenode host#localhost cj.stormvi slaves配置datanode/tasktracker host#localhost user1.storm user2.storm
- DNS配置
vi /etc/hosts10.40.33.100 cj.storm cj 10.40.33.101 user1.storm user1 10.40.33.102 user2.storm user2
- 同步到其他节点
scp- 同步DNS信息
- 同步SSH
authorized_keys(注意权限问题) - 同步hadoop
> scp -rp /home/hadoop/hadoop-1.2.1 hadoop@user1.storm:~ > scp -rp /home/hadoop/hadoop-1.2.1 hadoop@user2.storm:~
日志
- 存放配置:【hadoop-env.sh】(默认在hadoop安装目录的logs下)
> vi $HADOOP_HOME/conf/hadoop-env.sh export HADOOP_LOG_DIR=${HADOOP_HOME}/logs - 命名规则:【hadoop-用户名-进程名-主机名-日志格式后缀】

.log:通过log4j记录,日滚动,内容比全.out:记录标准输出和错误的日志,默认情况系统保留最新5个日志文件
配置文件说明
- 优先级:
core<hdfscore<mapred<yarn
- core-site.xml (默认:
core-default.xml) - hdfs-site.xml (默认:
hdfs-default.xml) - mapred-site.xml (默认:
mapred-default.xml) - yarn-site.xml (Hadoop2.x)
HDFS
把客户端的大文件存放在很多节点的数据块中
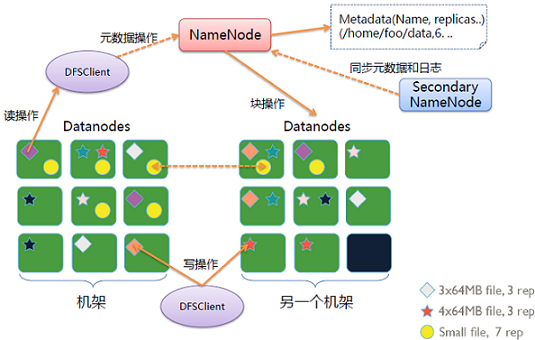
各进程说明
Namenode & Secondary
Namenode 负责管理:
- 接收用户的操作请求
- 管理数据节点和文件目录结构
- 始终在内存中维护
metadata(元数据)- 内容:
FileName, replicas, block-ids,id2host,... - eg:
/test/a.log, 3 ,{blk_1,blk_2}, [{blk_1:[h0,h1,h3]},{blk_2:[h0,h2,h4]}],...
- 内容:
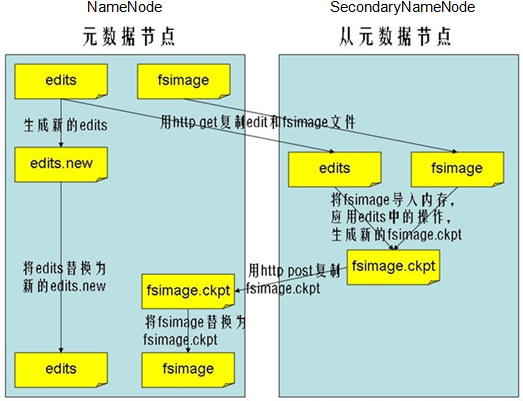
Namenode 主要维护的文件:
fsimage- 元数据镜像文件,即namenode中metedata的镜像(存放位置配置
dfs.name.dir) - 文件目录与数据块之间的关系(
name <=> block) 静态:- 不随时与namenode内存中的metedata保持一致
- 每隔一段时间由SecondNamenode合并fsimage和edits,推送给Namenode更新
- 元数据镜像文件,即namenode中metedata的镜像(存放位置配置
edits- 操作日志文件(存放位置配置
dfs.name.edit.dir) - 数据块与节点之间的关系(
block <=> node) 动态变化:- 每次Namenode启动时rebuilt到内存中
- 写请求到来时,namenode先向edits文件中写日志,成功后更新内存中的metadata,向客户端返回
- 操作日志文件(存放位置配置
fstime- 保存最近一次checkpoint的时间
- checkpiont 时机设置
fs.checkpoint.period:指定两次checkpoint的最大时间间隔(默认3600秒)fs.checkpoint.size:规定edits文件的最大值,超过则强制checkpoint(默认64M)
SecondaryNamenode 辅助Namenode :
- HA的一个解决方案,但不支持热备
- 监控HDFS状态的辅助后台程序
- 每隔一段时间获取HDFS元数据的快照
- 通知Namenode切换edits
- 从Namenode下载fsimage和edits
- 合并生成新的fsimage,推送至NameNode
- NameNode替换旧的fsimage
Datanode
负责存储:
- 存储位置:${hadoop.tmp.dir}/dfs/data
- 文件块数据(block)
- HDFS 最基本的存储单位
- 文件被分成block存储在磁盘上
- 为保证数据安全,block会有多个副本,存放在不同物理机上(默认为3个,配置
dfs.replication)
- 块数据的校验和(meta)
注意:
- 一个文件小于一个Block的大小时,只占用一个block,占有磁盘空间为文件实际大小(与普通文件系统不同)
- HDFS适合存储大文件,不适合小文件
- 每个文件占用的block在namenode内存中都有管理
- 多个小文件也许只占用一个block,对存储并不影响,但对namenode有影响(会增加namenode的内存压力)
- Block也不易太大,会增加读写复制移动重传等操作压力
HDFS 的web 接口
HDFS 对外提供了可供访问的http server,开放了很多端口
- core-site.xml,hdfs-site.xml
- Namenode:dfs.http.address
- Datanode:dfs.datanode.http.address
- mapred-site.xml
- JobTracker:mapred.job.tracker.http.addresss
- TaskTracker:mapred.task.tracker.http.address
Shell Cmd
> hadoop fs -ls # list /home/<currentUser>
> hadoop fs -ls / # list HDFS根目录下的内容
> hadoop fs -ls hdfs://cj.storm:9000/ # list HDFS根目录下的内容
> hadoop fs -lsr hdfs://cj.storm:9000/ # list HDFS as tree
> hadoop fs -mkdir hdfs://cj.storm:9000/dl
> hadoop fs -put /usr/local/tomcat1/logs/localhost_access_log.2015-07-15.txt hdfs://cj.storm:9000/dl
> hadoop fs -text hdfs://cj.storm:9000/dl/localhost_access_log.2015-07-15.txt
hadoop fs命令选项列表:
| 选项名称 | 使用格式 | 含义 |
|---|---|---|
| -ls | -ls <路径> | 查看指定路径的当前目录结构 |
| -lsr | -lsr <路径> | 递归查看指定路径的目录结构 |
| -du | -du <路径> | 统计目录下个文件大小 |
| -dus | -dus <路径> | 汇总统计目录下文件(夹)大小 |
| -count | -count [-q] | <路径> 统计文件(夹)数量 |
| -mv | -mv <源路径> <目的路径> | 移动 |
| -cp | -cp <源路径> | <目的路径> 复制 |
| -rm | -rm [-skipTrash] <路径> | 删除文件/空白文件夹 |
| -rmr | -rmr [-skipTrash] <路径> | 递归删除 |
| -put | -put <多个linux 上的文件> |
上传文件 |
| -copyFromLocal | -copyFromLocal <多个linux 上的文件> |
从本地复制 |
| -moveFromLocal | -moveFromLocal <多个linux 上的文件> |
从本地移动 |
| -getmerge | -getmerge <源路径> |
合并到本地 |
| -cat | -cat |
查看文件内容 |
| -text | -text |
查看文件内容 |
| -copyToLocal | -copyToLocal [-ignoreCrc] [-crc] [hdfs 源路径] [linux 目的路径] | 从本地复制 |
| -moveToLocal | -moveToLocal [-crc] |
从本地移动 |
| -mkdir | -mkdir |
创建空白文件夹 |
| -setrep | -setrep [-R] [-w] <副本数> <路径> | 修改副本数量 |
| -touchz | -touchz <文件路径> | 创建空白文件 |
| -stat | -stat [format] <路径> | 显示文件统计信息 |
| -tail | -tail [-f] <文件> | 查看文件尾部信息 |
| -chmod | -chmod [-R] <权限模式> [路径] | 修改权限 |
| -chown | -chown [-R] [属主][:[属组]] | 路径修改属主 |
| -chgrp | -chgrp [-R] | 属组名称路径修改属组 |
| -help | -help [命令选项] | 帮助 |
Java API
URL
String HDFS_PATH="hdfs://cj.storm:9000";
@Test
public void testURL() throws IOException{
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
URL url=new URL(HDFS_PATH+"/dl/localhost_access_log.2015-07-15.txt");
InputStream in=url.openStream();
IOUtils.copyBytes(in, System.out, 1024, true);
}
FileSystem
<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.block.size</name>
<value>8388608</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
String HDFS_PATH="hdfs://cj.storm:9000";
@Test
public void testFileSystem() throws IOException, URISyntaxException{
FileSystem fileSystem=FileSystem.get(new URI(HDFS_PATH),new Configuration());
// create dir
fileSystem.mkdirs(new Path("/t1"));
//upload file
FileInputStream in1=new FileInputStream("D:/input/012.txt");
FSDataOutputStream out=fileSystem.create(new Path("/t1/012.txt"));
IOUtils.copyBytes(in1,out,1024,true);
//file status -- upload by eclipse client (depends on project classpath:hdfs-site.xml)
FileStatus status=fileSystem.getFileStatus(new Path("/t1/012.txt"));
System.out.println("012.txt");
System.out.println("BlockSize:"+status.getBlockSize());
System.out.println("Length:"+status.getLen());
System.out.println("Replication:"+status.getReplication());
System.out.println("----------------------------");
//file status -- upload by hdfs cmd (depends on server conf/hdfs-site.xml)
status=fileSystem.getFileStatus(new Path("/dl/localhost_access_log.2015-07-15.txt"));
System.out.println("localhost_access_log.2015-07-15.txt:");
System.out.println("BlockSize:"+status.getBlockSize());
System.out.println("Length:"+status.getLen());
System.out.println("Replication:"+status.getReplication());
System.out.println("----------------------------");
//download file
FSDataInputStream in2=fileSystem.open(new Path("/t1/012.txt"));
IOUtils.copyBytes(in2,System.out,1024,true);
// delete file or dir
//boolean result=fileSystem.delete(new Path("/t1"),true);
//System.out.println("Delete:"+result);
}
注意:上传文件时,报AccessControlException:
- 方法1:set master server hdfs-site.xml dfs.permissions false
- 方法2:hadoop fs -chmod 777 xxx
- 方法3:change windows user to server user
RPC
概述
RPC:Remote Procedure Call
- 远程过程(对象方法)调用协议
- Client端触发,Server端运行,返回结果给Client
- 不同java进程间对象方法的调用,Server端提供对象供Client端调用,被调用对象的方法执行发生在Server端
RPC示例
- Server端:
- Object:
public interface IStudent extends VersiondPrototocol{ public static final long VERSION=2343L; public boolean sayHi(); }public class Student implements IStudent{ public boolean sayHi(){ System.out.printIn("Hello"); return true; } @Override public long getProtocolVersion(String protocol,long clientVersion) throws IOException{ return IStudent.VERSION; } } - 发布服务:
String Server_Address="localhost"; int Port=12345; Server server=RPC.getServer(new Student,Server_Address,Port,new Configuration()); server.start();
- Object:
- Client端:
- Object Interface:
public interface IStudent extends VersiondPrototocol{ public static final long VERSION=2343L; public boolean sayHi(); } - 调用服务:
IStudent proxy=(IStudent)RPC.waitForProxy(IStudent.class,IStudent.VERSION,new InetSocketAddress(Server_Address,Server_Port),new Configuration()); boolean result=proxy.sayHi(); System.out.print(result); RPC.stopProxy(proxy);
- Object Interface:
Hadoop RPC
- Hadoop的整个体系结构就是构建在RPC之上的(见org.apache.hadoop.ipc)
- Namenode/JobTracker 实际就是RPC Server+WebServer(Jetty)
- 各节点间的通讯协议
extends VersionedProtocol
HDFS 提供的通讯协议
ClientProtocol(Client <=> Namenode)- Client端与NameNode(Server端)的通讯接口
- 在Client端实际不能直接调用
ClientProtocol提供的方法,而是使用FileSystem - 传送文件时,是直接传送到
Datanode - (NameNode记录相关信息,指定传送到哪个Datanode中)
- 注意:文件不是传送到NameNode后由NameNode再向Datanode传送的
ClientDatanodeProtocol(Client <=> Datanode)- Client端与DataNode(Server端)的通讯接口
- for block recovery
DatanodeProtocol(Datanode <=> Namenode)- Datanode(Client端)与NameNode(Server端)的通讯接口
- 主动向NameNode发送心跳(setHeartbeat)
- 发送给Namenode的心跳中包含Datanode自身的一些信息
- NameNode返回回来的是下发给Datanode的命令
NamenodeProtocol(SecondaryNamenode <=> Namenode)- SecondaryNameNode(Client端)与NameNode(Server端)的通讯接口
注:Client端通过DFSClient对象与NameNode,Datanode通讯
DFSClient内部:
- 调用
ClientProtocol对象方法与NameNode通讯 - 通过
DataStreamer在对应Datanode上写入或删除block (DataStreamer内部会调用DatanodeProtocol对象方法向NameNode确定blockId和block所写位置) - 例如:上传文件到HDFS
//upload file FileInputStream in1=new FileInputStream("D:/input/012.txt"); FSDataOutputStream out=fileSystem.create(new Path("/t1/012.txt")); IOUtils.copyBytes(in1,out,1024,true);
MapReduce 提供的通讯协议
JobSubmissionProtocol(Client <=> JobTracker)- 调用JobSubmissionProtocol的submitJob,即执行是JobTracker(Server端)的submitJob
InterTrackerProtocol(TaskTracker <=> JobTracker)- 调用了heartbeat将tasktracker的状态通过RPC机制发送给jobTracker,返回值就是JobTracker的指令(方式同HDFS中的DatanodeProtocol)
MapReduce
MapReduce框架: 提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理(数据存储、划分、分发、结果收集、错误恢复等)细节
MR 思想:
- 分而治之,化整为零
- 排序优化,降低内存
版本说明
- hadoop 0.x 一般使用包 mapred
- mapper: extends MapReduceBase implements Mapper
- reducer: extends MapReduceBase implements Reducer
- job: JobConf,JobClient.runJob(jobConf)
- mapper: extends MapReduceBase implements Mapper
- hadoop 1.x 一般使用包 mapreduce
- mapper: extends Mapper
- reducer: extends Reducer
- job: Job,job.waitForComplete(true);
- mapper: extends Mapper
各进程说明
JobTracker负责管理 (master,只有一个):- 接收用户提交的计算任务
- 分配计算任务给TaskTrackers执行
- 监控TaskTracker的执行情况
TaskTracker负责具体计算任务(slave,可有多个):- 执行JobTracker分配的计算任务
- 管理各个任务在每个节点上的执行情况
- 可负责MapTask或ReduceTask
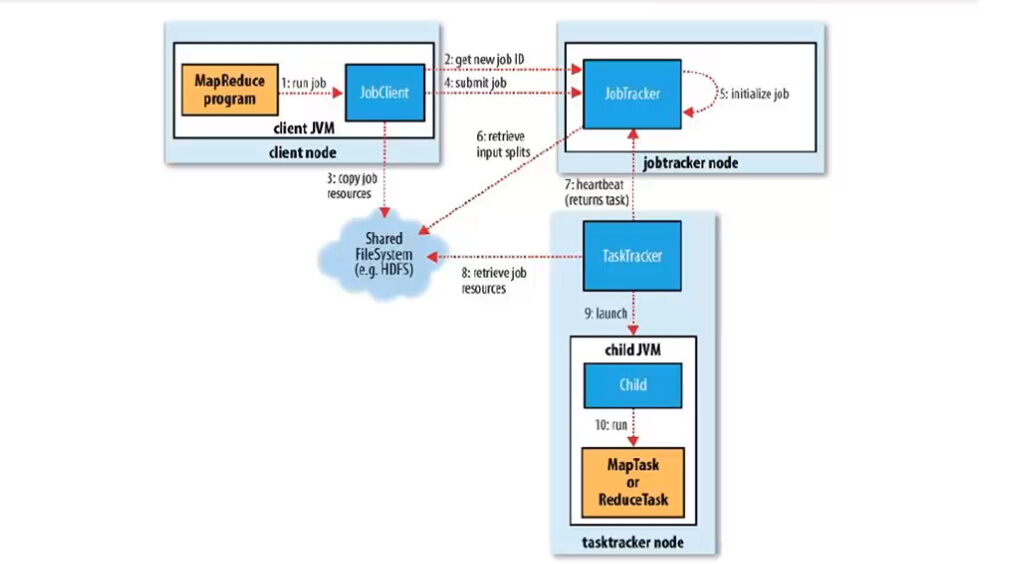
执行流程
- 客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar ...)
- JobClient通过RPC和JobTracker进行通信,返回一个存放jar包的地址(HDFS)和jobId
- client将jar包写入到HDFS当中(path = hdfs上的地址 + jobId)
- 开始提交任务(任务的描述信息,不是jar, 包括jobid,jar存放的位置,配置信息等等)
- JobTracker进行初始化任务
- 读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask
- TaskTracker通过心跳机制领取任务(任务的描述信息)
- 下载所需的jar,配置文件等
- TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask)
- 将结果写入到HDFS当中
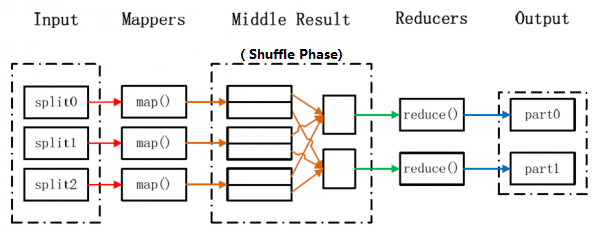
并行计算模型
InputFormat
public interface InputFormat<K, V> { InputSplit[] getSplits(JobConf job, int numSplits) throws IOException; RecordReader<K, V> getRecordReader(InputSplit split,JobConf job, Reporter reporter) throws IOException; }- InputSplit:分片(逻辑上)
- RecordReader:分片读取器
- break data into
key-value pairsfor input to the mapper (byte-oriented view => record-oriented view) - processing
record boundaries(eg:LineRecordReader 对每个Split会多读取一行)
- break data into
Mapper (
byte-oriented=><k1,v1>=><k2,v2>)public void run(Context context) throws IOException, InterruptedException { setup(context); try { while (context.nextKeyValue()) { map(context.getCurrentKey(), context.getCurrentValue(), context); } } finally { cleanup(context); } }- Context extends MapContext extends TaskInputOutputContext
- InputSplit split
- RecordReader
- Context extends MapContext extends TaskInputOutputContext
Shuffle
- 3.1 Mapper端
Partitioner-- 分区(逻辑上,将key-value pairs 划分到不同reducer的标记)Sort-- 本地Mapper的数据,在不同分区中,按key排序Combiner(optional) -- 按key分组后进行规约(本地的reduce<k,v>=><k,{v1,v2,...}>)- CompressionCode (optional) -- 压缩
- Mapper output (on HDFS) -- 物理上Partition输出(eg: part-r-00000,part-r-00001,...)
- 3.2 Reducer端
Copy-- 从各个Mapper端copy对应分区的数据到ReducerSort & Merge-- 各个Mapper来的数据,按key合并排序 (<k,v> => <k,{v1,v2,...}>)
- 3.1 Mapper端
Reducer (
<k,{v1,v2,...}> => <k,v>)public void run(Context context) throws IOException, InterruptedException { setup(context); try { while (context.nextKey()) { reduce(context.getCurrentKey(), context.getValues(), context); } } finally { cleanup(context); } }- Context extends ReduceContext extends TaskInputOutputContext
- RawKeyValueIterator input
- RawComparator
comparator - Deserializer
keyDeserializer - Deserializer
valueDeserializer
- Context extends ReduceContext extends TaskInputOutputContext
OutputFormat
public abstract class OutputFormat<K, V> { public abstract RecordWriter<K, V> getRecordWriter(TaskAttemptContext context ) throws IOException, InterruptedException; public abstract void checkOutputSpecs(JobContext context) throws IOException, InterruptedException; public abstract OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException; }- RecordWriter 将key-value paris 输出到output file
注:
MapTask: Mapper+Shuffle(Mapper端)ReduceTask:Reducer+Shuffle(Reducer端)- Mapper数量=InputSplit数量
- 由conf参数
mapred.min.split.size,mapred.max.split.size,blockSize` 共同决定 splitSize = max{minSize, min{maxSize, blockSize}}- 一般为BlockSize,即有BlockNum个Split
- 由conf参数
- Reducer数量=Partition数量
- 由
job.setNumReduceTasks(..)设 - 默认为1
- 由
Spill溢出- 每个map有一个环形内存缓冲区,用于存储任务的输出
- 一旦达到阀值,后台线程把内容写到一个溢出写文件(partition,sort,combiner-optional 后再写入)
- Mapper完成后,合并全部溢出写文件为各个分区且排序的文件,供Reducer使用
io.sort.mb设置缓冲区大小(默认100M)io.sort.spill.percent设置阀值(默认0.8)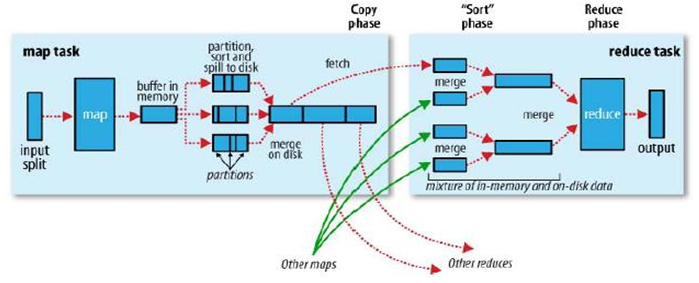
Partitioner
Partition作用:
- 负载均衡 (对Mapper产生的中间结果进行分区,以便交给各个Reducer并行处理,提高效率)
- 如何分区是关键:要快,且尽量均匀
abstract Partitionerpublic abstract int getPartition(KEY key, VALUE value, int numPartitions);- 返回
[0,numPartitions-1]的数字,即分区标识 - Job默认使用
HashPartitioner,按key分区(相同key会划分到同一个reducer)
实现类:
- 基于hash分区的实现:
which reducer=(hash & Integer.MAX_VALUE) % numReduceTasksHashPartitioner(默认): hash为key.hashCode()BinaryPatitioner:对键值K的[rightOffset,leftOffset]这个区间取hashKeyFieldBasedPartitioner:提供了多个区间用于计算hash
- 不基于hash分区的实现:
TotalOrderPartitioner- 通过 trie 树,按照大小将数据分成若干个区间(分片)
- 且保证后一个区间的所有数据均大于前一个区间数据
- 通常用在数据
全排序 - 典型的应用实例:TeraSort,HBase批量数据导入
- 基于hash分区的实现:
LocalAggregation
本地聚合,减少传输到reducer的数据量(注意处理不要影响最终结果)
示例:计算平均值(输入文件每行记录:string,count)
方式一: out-mapper Combiner (extends Reducer)
/* 注意:mapper的输出键值对和reducer的输入键值对类型要匹配 class Mapper method map(string word,integer count) Emit(word,count) */ class Mapper method map(string word,integer count) Emit(word,pair(count,1)) class Combiner method reduce(string word,integer-list [c1,c2,...]) sum := 0 cnt := 0 foreach integer c in [c1,c2,...] sum := sum+c cnt := cnt+1 Emit(word,pair(sum,cnt)) class Reducer method reduce(string word,pairs[(s1,c1),(s2,c2),...]) sum := 0 cnt := 0 foreach pair(s,c) in pairs[(s1,c1),(s2,c2),...] sum := sum+s cnt := cnt+c avg := sum/cnt Emit(word,avg)方案二:in-mapper Combiner (map时统计,cleanup时emit)
class Mapper method setup S := new AssociativeArray C := new AssociativeArray method map(string word,integer count) S{word} := S{word}+count C{word} := C{word}+1 method cleanup foreach word in S Emit(word,pair(S{word},C{word})) //class Reducer 同上- 注:
- 方案二更高效(方案一并没有减少在mapper产生的key-value对数量)
- 方案二需注意内存溢出问题,可通过周期性的“flush“内存中的数据来解决
- 例如修改为:
/* mapper读入K条时,就flush H (emit & clear)*/ class Mapper method setup S := new AssociativeArray C := new AssociativeArray limit:=100 method map(string word,integer count) S{word} := S{word}+count C{word} := C{word}+1 if(S.size()>100) foreach word in S Emit(word,pair(S{word},C{word})) S.clear(); C.clear(); method cleanup foreach word in S Emit(word,pair(S{word},C{word}))
Key-Value 数据类型
MapReduce中的Key-Value:
Key:必须实现
interface WritableComparable(一般需要重写toString,hashCode,equals方法)public interface WritableComparable<T> extends Writable, Comparable<T> { }- 内部可另外实现一个比较优化器
WritableComparator(implements RawComparator),实现直接比较数据流中的数据(无需反序列化为对象后比较)
- 内部可另外实现一个比较优化器
Value:必须实现
interface Writablepublic interface Writable { void write(DataOutput out) throws IOException; //Serialize void readFields(DataInput in) throws IOException; //Deserialize }
接口说明:
Writable:- 根据 java.io 的
DataInput和DataOutput实现的简单、有效的序列化对象 - 用于进程间通信,永久存储
- Hadoop中一些Java类型对应的Writable封装
Java类型 WritableComparable 序列化后长度 boolean BooleanWritable 1 byte ByteWritable 1 int IntWritable 4 int VIntWritable 1~5 long LongWritable 8 long VLongWritable 1~9 float FloatWritable 4 double DoubleWritable 8 String Text / null NullWritable / eg:
Text text = new Text("test"); text.toString(); text.set("Hello"); IntWritable one = new IntWritable(1); one.get(); one.set(2);
- 根据 java.io 的
RawComparator:- 优化比较,允许直接比较流中的记录,省去反序列化对象的开销
public interface RawComparator<T> extends Comparator<T> { public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2); } WritableComparator是RawComparator对WritableComparable类的一个通用实现- compare默认实现:从数据流中反序列化出对象,使用对象的compareTo方法比较
- 充当了RawComparator实例的一个工厂方法
- 可通过静态方法注册比较器:
WritableComparator.define(Class c,WritableComparator comparator) - 例如:IntWritable 中注册使用了RawComparator
public static class Comparator extends WritableComparator { public Comparator() { super(IntWritable.class); } public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { int thisValue = readInt(b1, s1); int thatValue = readInt(b2, s2); return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1)); } } static { // register this comparator WritableComparator.define(IntWritable.class, new Comparator()); } - 在Job中,也可通过
job.setSortComparatorClass(cls)设置key的比较器
- 优化比较,允许直接比较流中的记录,省去反序列化对象的开销
Input & Output
InputFormat 负责处理MapReduce的输入部分
- 有三个作用:
- 验证作业的输入是否规范(例如输入路径是否存在等)
- 把输入文件按照一定规则切分成
InputSplit(逻辑上),每个InputSplit 由一个Mapper执行- InputSplit 接口方法:
getLength,getLocations
- InputSplit 接口方法:
- 提供
RecordReader的实现类,把InputSplit读到Mapper中进行处理- RecordReader接口方法:
nextKeyValue,getCurrentKey,getCurrentValue等
- RecordReader接口方法:
- 抽象方法:
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;RecordReader<K, V> getRecordReader(InputSplit split,JobConf job,Reporter reporter) throws IOException;
- 实现类:
- FileInputFormat
FileInputFormat Key Value Description TextInputFormat the byte offset of line line contents 按行读取(默认) NLineInputFormat the byte offset of line line contents 可以控制在每个split中数据的行数,默认为1行 KeyValueTextInputFormat first tab character the remainder of line 按行读,第一列为key,其余为value (以tab区分列) SequenceFileInputFormat user-defined user-defined 二进制方式读取(一般为压缩文件) CombineFileInputFormat user-defined user-defined 将多个小文件合成一个split作为输入 - RandomInputFormat
- DBInputFormat
- EmptyInputFormat
- ...
- FileInputFormat
- 注意:FileInputFormat对于每个小于splitSize的文件当做一个split,并分配一个map任务,效率底下,可考虑使用CombineFileInputFormat
OutputFormat 负责处理MapReduce的输出部分
- 三个作用:
- 验证作业的输出是否规范(例如输出路径是否已存在等)
- 提供
RecordWriter的实现类,把数据按某个格式写出 - 提供
OutputCommitter实现类,维护管理side-effect file(临时存放结果数据的文件)
- 抽象方法:
void checkOutputSpecs(JobContext context)RecordWriter<K, V> getRecordWriter(TaskAttemptContext context)OutputCommitter getOutputCommitter(TaskAttemptContext context)
- 实现类:
- FileOutputFormat
- TextOutputFormat: “key /t value /n“格式输出(默认)
- SequenceFileOutputFormat
- FilterOutputFormat
- LazyOutputFormat
- DBOutputFormat
- NullOutputFormat
- ...
- FileOutputFormat
Counter
计数器
- 方便以全局的视角来审查程序的运行情况以及各项指标,及时做出错误诊断并进行相应处理
- 例如: 一个MapReduce任务的输出
Counters: 19 // 共有19个计数器 File Output Format Counters // 【FileOutputFormat 组】 Bytes Written=19 // reduce输出到hdfs的字节数 FileSystemCounters // 【FileSystem 组】 FILE_BYTES_READ=481 HDFS_BYTES_READ=38 FILE_BYTES_WRITTEN=81316 HDFS_BYTES_WRITTEN=19 File Input Format Counters // 【FileInputFormat 组】 Bytes Read=19 // map从hdfs读取的字节数 Map-Reduce Framework // 【MapReduce 组】 Map output materialized bytes=49 Map input records=2 // map读入的记录行数 Reduce shuffle bytes=0 Spilled Records=8 Map output bytes=35 Total committed heap usage (bytes)=266469376 SPLIT_RAW_BYTES=105 Combine input records=0 Reduce input records=4 // reduce从map端接收的记录行数 Reduce input groups=3 // reduce函数接收的key数量,即归并后的k2数量 Combine output records=0 Reduce output records=3 // reduce输出的记录行数 Map output records=4 // map输出的记录行数 Counter(implements Writable)- 成员变量:
- String name
- String displayName
- long value
- 声明一个计数器
context.getCounter(Enum enum)context.getCounter(String groupName,String counterName)
- 设置计数器的值
- 设置值:
counter.setValue(long value); - 增加计数:
counter.increment(long incr);
- 设置值:
- 成员变量:
全局数据
全局作业参数:保存在
Configuration中conf.setXxx("...",...);context.getConfiguration().getXxx("...");
全局数据文件:使用
DistributedCache文件传递机制(适合小文件,可完整读取到内存中)- 将文件传送到DistributedCache中,各节点从DistributedCache中将文件复制到本地的文件系统中使用
DistributedCache.addCacheFile(uri, conf)DistributedCache.getCacheFiles(conf)
MapReduce 应用示例
计数 去重 排序 TopKey 选择 投影 分组 多表连接 单表连接 倒排索引 Inverted index | 页面排序 PageRank | 词频统计分析 | 同现关系 (矩阵算法) 动态规划 | 快速排序 | 堆排序 图算法 | 聚类 | 推荐系统 | 机器学习 | 数据挖掘
统计
示例:文本单词数量统计
- input:
ABC DEF AED DIE EIL ABC JFIE ABC DEF output:
ABC 3 AED 1 DEF 2 DIE 1 EIL 1 JFIE 1最简版:map+reduce
- Mapper
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private Text word=new Text(); private IntWritable one=new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr=new StringTokenizer(value.toString()); while(itr.hasMoreTokens()){ word.set(itr.nextToken()); context.write(word, one); } } } - Reducer
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result=new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int sum=0; for(IntWritable val:values){ sum+=val.get(); } result.set(sum); context.write(key,result); } }
- Mapper
优化版:map+local aggregation(in-mapper combiner)+reduce
Mapper
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private Map<String,Integer> temp=new HashMap<String,Integer>(); private int limit=500; private int i=0; @Override protected void setup(Context context) throws IOException, InterruptedException { limit=context.getConfiguration().getInt("flush.limit", limit); i=0; } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr=new StringTokenizer(value.toString()); String word=null; Integer sum=0; while(itr.hasMoreTokens()){ sum=temp.get(word); if(sum==null) temp.put(word, 1); else temp.put(word,sum+1); i++; if(i==limit){ cleanup(context); temp.clear(); i=0; } } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { Text word=new Text(); IntWritable count=new IntWritable(); for(String key:temp.keySet()){ word.set(key); count.set(temp.get(key)); context.write(word,count); } } }- Reducer
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result=new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int sum=0; for(IntWritable val:values){ sum+=val.get(); } result.set(sum); context.write(key,result); } }
Job
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf=new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: SimpleWordCount <in> <out>"); System.exit(2); } // delete exist output path FileSystem fs=FileSystem.get(conf); Path outputPath=new Path(otherArgs[1]); if(fs.exists(outputPath)){ fs.delete(outputPath, true); } Job job=new Job(conf,"WordCount"); job.setJarByClass(WordCount.class); //1.Input FileInputFormat.addInputPath(job, new Path(otherArgs[0])); job.setInputFormatClass(TextInputFormat.class); //2.Mapper job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //job.setCombinerClass(WordCountReducer.class); // Optional //3.Reducer job.setNumReduceTasks(2); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //4.Output FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); job.setOutputFormatClass(TextOutputFormat.class); boolean result=job.waitForCompletion(true); System.exit(result ? 0 : 1); }
按值排序
示例:SecondarySort -- first column desc ; second column asc
- input:
A 1 r1994 B 2 r1995 C 1 r1998 B 1 r1992 A 3 r1994 C 2 r1992 A 2 r1995 C 3 r1996 B 3 r1998 - output:
C (1,r1998) (2,r1992) (3,r1996) B (1,r1992) (2,r1995) (3,r1998) A (1,r1994) (2,r1995) (3,r1994)
实现方案:用复合键让系统完成排序 (pairs)
- 在map和reduce阶段进行排序时,比较的是key
- value是不参与排序比较的
- 想让value部分也进行排序,将value中需要排序的部分加入到key中形成复合键pairs
- 此时分区,分组时也是按照新的复合键pairs
- 可以自定义Partitioner仅对pair中原来的k进行散列,以保证原来同一key的键值对分区到同一个Reduce节点上
- 可自定义Comparator仅对pair中原来的k进行比较分组,以保证原来同一key的键值对分到同一组
具体实现:
Composite Key
public class NewK implements WritableComparable<NewK>{ private Text first; private int second; public NewK(Text first,int second){ this.first=first; this.second=second; } public Text getFirst() { return first; } public void setFirst(Text first) { this.first = first; } public Integer getSecond() { return second; } public void setSecond(int second) { this.second = second; } @Override public void write(DataOutput out) throws IOException { first.write(out); out.writeInt(second); } @Override public void readFields(DataInput in) throws IOException { first.readFields(in); second=in.readInt(); } @Override public int compareTo(NewK o) { int cmp=first.compareTo(o.first); return cmp==0?this.second-o.second:cmp; } @Override public int hashCode() { return this.first.hashCode()+this.second; } @Override public boolean equals(Object obj) { if(obj instanceof NewK){ NewK o=(NewK)obj; return this.first.equals(o.getFirst()) && this.second==o.getSecond(); } return false; } @Override public String toString() { return "["+this.first+","+this.second+"]"; } }- Mapper
public static class SecondarySortMapper extends Mapper<LongWritable, Text, NewK, Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr=new StringTokenizer(value.toString()); if(itr.countTokens()>=3){ NewK newK=new NewK(new Text(itr.nextToken()),Integer.parseInt(itr.nextToken())); context.write(newK, new Text(itr.nextToken())); } } } Shuffler
- Partitioner
public static class NewKPartitioner extends Partitioner<NewK, Text> { @Override public int getPartition(NewK key, Text value, int numPartitions) { return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions; } } SortComparator
// first desc ; second asc public static class NewKSortComparator extends WritableComparator{ private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator(); public NewKSortComparator() { super(NewK.class); } @Override public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2,int l2) { try { // 字节流中的Text字段:Len+Content=VInt+byte[] // VInt:第一个byte描述VInt的长度,例如为n,则后面n-1个byte的内容为Text Content的长度 // 获取VInt的长度:WritableUtils.decodeVIntSize(b1[s1]) // 获取Content的长度(即VInt的值):readVInt(b1, s1) int firstLen1=WritableUtils.decodeVIntSize(b1[s1])+readVInt(b1, s1); int firstLen2=WritableUtils.decodeVIntSize(b1[s1])+readVInt(b2,s2); int cmp=TEXT_COMPARATOR.compare(b1, s1, firstLen1, b2, s2, firstLen2); if(cmp!=0) return -cmp; int secondValue1=readInt(b1,s1+firstLen1); int secondValue2=readInt(b2,s2+firstLen2); return secondValue1-secondValue2; } catch (IOException e) { throw new IllegalArgumentException(e); } } }- GroupComparator
public static class NewKGroupingComparator extends WritableComparator{ public NewKGroupingComparator(){ super(NewK.class); } @Override public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2,int l2) { try { int n1=WritableUtils.decodeVIntSize(b1[s1]); int n2=WritableUtils.decodeVIntSize(b2[s2]); int firstContentLen1=readVInt(b1, s1); int firstContentLen2=readVInt(b2,s2); return compareBytes(b1,s1+n1,firstContentLen1,b2,s2+n2,firstContentLen2); } catch (IOException e) { throw new IllegalArgumentException(e); } } }
- Partitioner
- Reducer
public static class SecondarySortReducer extends Reducer<NewK, Text, Text, Text>{ @Override protected void reduce(NewK key, Iterable<Text> values,Context context) throws IOException, InterruptedException { for(Text val:values){ context.write(key.getFirst(), new Text("("+key.getSecond()+","+val.toString()+")")); } } } Job
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf=new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: SecondarySort <in> <out>"); System.exit(2); } // delete exist output path FileSystem fs=FileSystem.get(conf); Path outputPath=new Path(otherArgs[1]); if(fs.exists(outputPath)){ fs.delete(outputPath, true); } Job job=new Job(conf,"SecondarySort"); job.setJarByClass(SecondarySort.class); //1.Input FileInputFormat.addInputPath(job, new Path(otherArgs[0])); job.setInputFormatClass(TextInputFormat.class); //key:column1,value:remaining columns //2.Mapper job.setMapperClass(SecondarySortMapper.class); job.setMapOutputKeyClass(NewK.class); job.setMapOutputValueClass(Text.class); job.setPartitionerClass(NewKShuffle.NewKPartitioner.class); // partition by NewK.first job.setSortComparatorClass(NewKShuffle.NewKSortComparator.class); // 确定Key排序策略:NewK.first&NewK.second(默认使用key的实现的compareTo方法) //3.Reducer job.setNumReduceTasks(1); // only one reducer for all-key sorted job.setGroupingComparatorClass(NewKShuffle.NewKGroupingComparator.class); //确定分组策略:NewK.first相同,则属于同一个组(默认同上面setSortComparatorClass) job.setReducerClass(SecondarySortReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //4.Output FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); job.setOutputFormatClass(TextOutputFormat.class); boolean result=job.waitForCompletion(true); System.exit(result ? 0 : 1); }
TopK
示例:
- input:
A 39 Hello 34 K 93 B 123 Person 99 D 3023 C 39 - output(top 3):
Person 99 B 123 D 3023
实现方案:
- Reducer(1个): topk(S) = topk(topk(s1), topk(s2), topk(s3), ...)
- TreeMap 自动排序
具体实现:
Mapper
public static class TopKMapper extends Mapper<Text, IntWritable, IntWritable, Text>{ private TreeMap<Integer,String> temp=new TreeMap<Integer,String>(); private int limitK=10; private int i=0; @Override protected void setup(Context context) throws IOException,InterruptedException { limitK=context.getConfiguration().getInt("top.k", limitK); i=0; } @Override protected void map(Text key, IntWritable value, Context context) throws IOException, InterruptedException { temp.put(value.get(), key.toString()); i++; if(i==limitK){ temp.pollFirstEntry(); //temp.remove(temp.firstKey()); i--; } } @Override protected void cleanup(Context context)throws IOException, InterruptedException{ for(Integer key:temp.keySet()){ context.write(new IntWritable(key), new Text(temp.get(key))); } } }Reducer
public static class TopKReducer extends Reducer<IntWritable, Text, IntWritable, Text>{ private TreeMap<Integer,String> temp=new TreeMap<Integer,String>(); private int limitK=10; private int i=0; @Override protected void setup(Context context) throws IOException,InterruptedException { limitK=context.getConfiguration().getInt("top.k", limitK); i=0; } @Override protected void reduce(IntWritable key, Iterable<Text> values,Context context) throws IOException, InterruptedException { temp.put(key.get(),values.toString()); i++; if(i==limitK){ temp.pollFirstEntry(); i--; } } @Override protected void cleanup(Context context) throws IOException, InterruptedException{ for(Integer key:temp.keySet()){ context.write(new IntWritable(key), new Text(temp.get(key))); } } }Job
Job job=new Job(conf,"TopK"); job.setJarByClass(TopK.class); //1.Input FileInputFormat.addInputPath(job, new Path(otherArgs[0])); job.setInputFormatClass(KeyValueTextInputFormat.class); //key:Word,value:Count //2.Mapper job.setMapperClass(TopKMapper.class); job.setMapOutputKeyClass(IntWritable.class); job.setMapOutputValueClass(Text.class); //3.Reducer job.setNumReduceTasks(1); // only one reducer job.setReducerClass(TopKReducer.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(Text.class); //4.Output FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); job.setOutputFormatClass(TextOutputFormat.class); boolean result=job.waitForCompletion(true); System.exit(result ? 0 : 1);
全排序
最简版:归并排序(n个mapper+1个reduce)
- Map 阶段:每个 Map Task进行局部排序;
- Reduce 阶段:启动一个 Reduce Task 进行全局排序
- 注意: 由于作业只能有一个 Reduce Task,因而 Reduce 阶段会成为作业的瓶颈
优化版:使用TotalOrderPartitioner (Sampler+map+TotalOrderPartitioner+reduce)
- Job1: 数据采样(InputSampler 通过采样获取分片的分割点,并写入partition file)
- Sampler:
K[] getSample(InputFormat<K,V> inf, Job job) ,Hadoop 自带了几个采样算法:- IntervalSampler
- RandomSampler
- SplitSampler
- writePartitionFile:根据Sampler提供的样本,排序后写入到partition file
- Sampler:
- Job2:MapReduce (使用TotalOrderpartitioner进行分区)
- Job1: 数据采样(InputSampler 通过采样获取分片的分割点,并写入partition file)
优化版具体实现:
Job1: Sampler
// Sampler Job Job samplerJob=new Job(conf,"TotalOrderSampler"); samplerJob.setJarByClass(TotalOrder.class); FileInputFormat.addInputPath(samplerJob, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(samplerJob,new Path(otherArgs[1])); samplerJob.setInputFormatClass(KeyValueTextInputFormat.class); samplerJob.setNumReduceTasks(3); samplerJob.setOutputFormatClass(TextOutputFormat.class); RandomSampler<Text,Text> sampler=new RandomSampler<Text,Text>(0.1,1000,10); TotalOrderPartitioner.setPartitionFile(samplerJob.getConfiguration(),new Path(otherArgs[0],"sampler")); InputSampler.writePartitionFile(samplerJob, sampler); // 默认使用TextInputFormat的Key取样- Job2: MapReduce
// MapReduce Job Job job=new Job(conf,"TotalOrder"); job.setJarByClass(TotalOrder.class); //2.1 Input FileInputFormat.addInputPath(job, new Path(otherArgs[0])); job.setInputFormatClass(KeyValueTextInputFormat.class); // key:Word,value:Count //2.2 Mapper job.setMapperClass(Mapper.class); // default Mapper job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); // Partitioning Configuration(Use TotalOrderPartitioner,partitionOutputPath为samplerJob的OutputPath) job.setPartitionerClass(TotalOrderPartitioner.class); TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), partitionOutputPath); //2.3 Reducer job.setNumReduceTasks(3); // 3 reducers job.setReducerClass(Reducer.class); // default Reducer job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //2.4 Output FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); job.setOutputFormatClass(TextOutputFormat.class); //2.5 exec job boolean result=job.waitForCompletion(true); System.exit(result ? 0 : 1);
多数据源连接
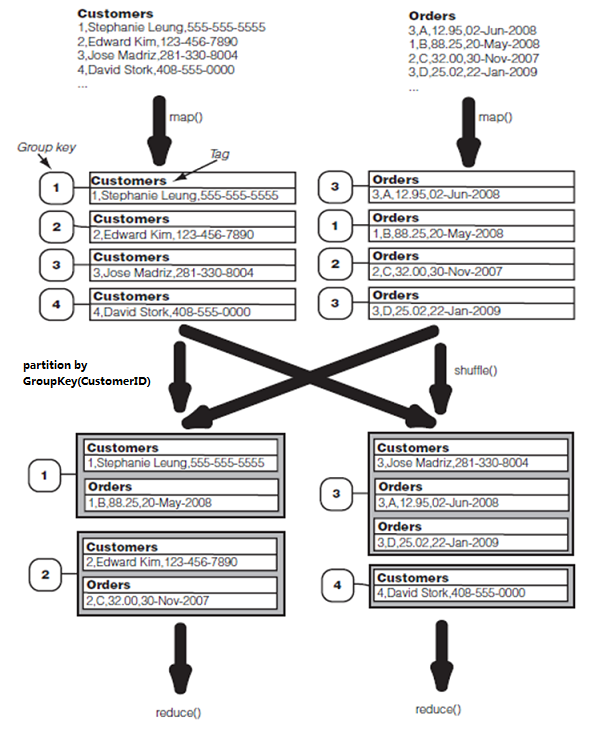
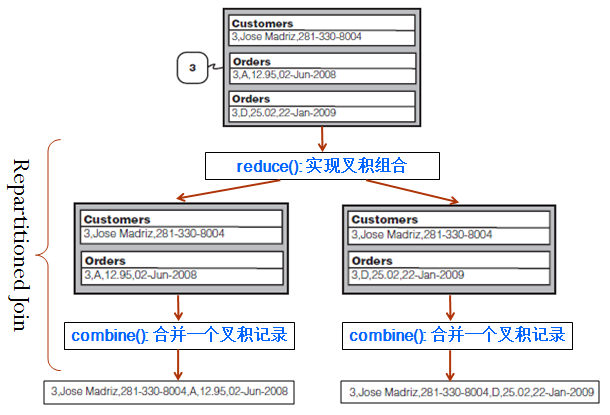
方案一:用DataJoin类实现Reduce端Join(Repartitioned Join:需加入hadoop-datajoin包)
- mapper端: extends DataJoinMapperBase 打标签
- reducer端: extends DataJoinReducerBase 组合
- record: extends TaggedMapOutput 标签+数据
方案二:用文件复制实现Map端Join(Replicated Join: 把较小的数据源文件复制到每个Map节点,然后在Map阶段完成Join操作)
- Job中:使用distributed cache机制用于将一个或多个文件分布复制到所有节点上
- addCacheFile(URI uri) 将一个文件放到distributed cache file中
- mapper端
- setup:读取设置在distributed cache files中的文件(context.getLocalCacheFiles())并读入内存
- map:join
- 注意:即使较小的数据源文件,也可能仍然无法全部保存在内存中处理
- 扩展示例:
- 设有两个数据集S和 R,较小的数据集R可以被分为R1, R2, R3, ……的子集,且每个子集都足以存放在内存中处理
- 则可以对先对每个Ri用Replicated Join进行与S的Join处理,最后将处理结果合并起来(Union),得到S Join R
- Job中:使用distributed cache机制用于将一个或多个文件分布复制到所有节点上
扩展:
- mapper端:过滤,打标签
- 过滤数据记录,生成一个仅包含join key(如 CustomerID)的过滤文件,存放在distributed cache file中
- 过滤掉不在这个列表中的所有Customer记录和Order记录
- reducer端:join
- mapper端:过滤,打标签
限制:
- 以上的多数据源Join只能是具有相同主键/外键的数据源间的连接
- 例如:
- 有三个数据源:Customers(CustomerID),Orders(CustomerID,ItemID),Products(ItemID)
- 在mapReduce中将需要分两个MapReduce作业来完成三个数据源的Join
- 第一个MapReduce作业:完成Customers与Orders的Join
- 第二个MapReduce作业:完成第一个MapReduce Join的结果与Products的Join
链式任务
子任务顺序化执行(前面MapReduce任务的输出作为后面MapReduce的输入:mapreduce1->mapreduce2->...->mapreduceN)
// job1 Configuration jobconf1= new Configuration(); job1 = new Job(jobconf1, “Job1"); job1.setJarByClass(jobclass1); …… FileInputFormat.addInputPath(job1, inpath1); FileOutputFormat.setOutputPath(job1, outpath1); job1.waitForCompletion(true); // job2 Configuration jobconf2= new Configuration(); job2 = new Job(jobconf2, “Job2"); job2.setJarByClass(jobclass2); …… FileInputFormat.addInputPath(job2, outpath1); FileOutputFormat.setOutputPath(job2, outpath2); job2.waitForCompletion(true); // job3 Configuration jobconf3= new Configuration(); job3 = new Job(jobconf3, “Job3"); job3.setJarByClass(jobclass3); …… FileInputFormat.addInputPath(job3, outpath2); FileOutputFormat.setOutputPath(job3, outpath3); job3.waitForCompletion(true);子任务间具有数据依赖关系 (1,2并行,join后3:mapreduce1 || mapreduce 2 -> mapreduce3)
jobx = new Job(jobxconf, “Jobx"); …… joby = new Job(jobyconf, “Joby"); …… jobz = new Job(jobzconf, “Jobz"); jobz.addDependingJob(jobx); // jobz将等待jobx执行完毕 jobz.addDependingJob(joby); // jobz将等待joby执行完毕 JobControl JC = new JobControl(“XYZJob”); JC.addJob(jobx); JC.addJob(joby); JC.addJob(jobz); JC.run();前处理和后处理步骤的链式执行 :链式Mapper(ChainMapper)和链式Reducer (ChainReducer)
未完待续
...