概述
- 建立在Hadoop基础上的数据仓库,能够管理查询Hadoop中的数据
- 本质上,Hive是一个SQL解析引擎,将SQL语句转译成M/R Job,在Hadoop执行
- Hive的表其实就是HDFS的目录,字段即为文件中的列,可以直接在M/R Job里使用这些数据
- 在HDFS中的默认存放位置:/user/hive/warehouse(hive-conf.xml的hive.metastore.warehouse.dir属性)
系统架构
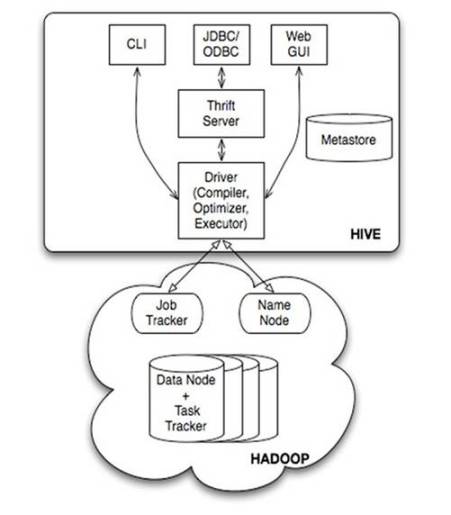
- 用户接口
- CLI:Shell命令行
- JDBC/ODBC:Java Connection (与使用传统数据库JDBC的方式类似)
- WebGUI:通过浏览器访问 Hive
- MetaStore
- 存储元数据(例如:表名,表属性,列属性,分区属性,数据所在路径等)
- 存储在数据库中,目前支持 mysql、derby(默认,内置)
- 默认使用内嵌的derby数据库作为存储引擎
- Derby引擎的一次只能打开一个会话
- MySQL等外置存储引擎,可支持多用户同时访问
- Driver
- 包含解释器,编译器,优化器,执行器
- 完成HQL=>Job,Trigger Exec
- Hadoop
- 用 HDFS 进行存储
- 利用 MapReduce 进行计算
- 注意:大部分的查询由 MapReduce 完成,但有些不是,例如
select * from table(包含*的查询)
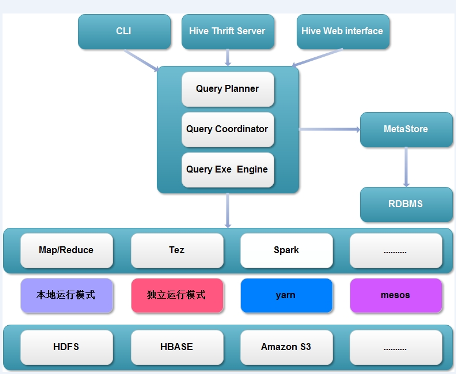
现在Hive的整体框架,计算引擎不仅仅支持Map/Reduce,并且还支持Tez、Spark等。根 据不同的计算引擎又可以使用不同的资源调度和存储系统
数据存储
存储结构主要包括:数据库、文件、表、视图
- 使用 HDFS 进行存储,无专门的数据存储格式,也没有为数据建立索引
- 用户只需在建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据文件为Table
- 默认可以直接加载文本文件(TextFile),也支持SequenceFile
- 每一个 Table 在 Hive 中都有一个相应的目录存储数据
安装
Hive可以安装在Hadoop集群中的任何一台机器上 metastore支持三种存储模式
- 本地内嵌模式(默认):元数据保持在Hive内嵌的derby中,只允许一个会话连接
- 本地独立模式:元数据保持在本地的一个DB中,允许多会话连接
远端独立模式:元数据保持在远程的一个DB中,允许多会话连接
安装Hive:
- 下载解压
- 设置环境变量(
/etc/profile文件)HIVE_HOMEHADOOP_HOMEPATH
- 配置(
$HIVE_HOME/conf目录下)hive-log4j.properties.template=>hive-log4j.propertieshive-default.xml.template=>hive-site.xml<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.exec.stagingdir</name> <value>/tmp/hive/.hive-staging</value> </property> <property> <name>hive.exec.scratchdir</name> <value>/tmp/hive</value> </property> <property> <name>hive.exec.local.scratchdir</name> <value>/tmp/hive</value> </property> <property> <name>hive.downloaded.resources.dir</name> <value>/tmp/hive/${hive.session.id}_resources</value> </property> <property> <name>hive.server2.logging.operation.log.location</name> <value>/tmp/hive/operation_logs</value> </property>
HDFS上创建和授权目录
hadoop fs -mkidr /tmp hadoop fs -chmod g+w /tmp hadoop fs -mkidr /user/hive/warehouse hadoop fs -chmod g+w /user/hive/warehouse
使用外部数据库(例如MySQL)作为Hive的metastore:
安装MySQL
> rpm -qa |grep mysql # 检查mysql > rpm -e --nodeps mysql # 强力卸载mysql > rpm -i mysql-server-******** # 安装mysql服务端 > rpm -i mysql-client-******** # 安装mysql客户端 > mysqld_safe & # 启动mysql 服务端 > mysql_secure_installation # 设置root用户密码- mysql 连接权限修改
> mysql -u root -p mysql> use mysql; mysql> select host,user from user; mysql> grant all privileges on *.* to 'root'@'%' identified by 'mypassword' with grant option; mysql> select host,user from user; mysql> flush privileges; - 添加mysql的jdbc驱动包(置于到
$HIVE_HOME/lib目录下) - 添加配置Hive (
$HIVE_HOME/conf/hive-site.xml)<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://cj.storm:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>admin</value> </property>
运行Hive:
- 保证Hadoop是启动状态
- 设置Hive运行模式
- 分为本地与集群两种,可通过
mapred.job.tracker参数设置 - 例如:
> hive -e "SET mapred.job.tracker=local"
- 分为本地与集群两种,可通过
- 启动Hive
- 启动命令行
> hive --service cli,同> hive - 启动Web(port:9999)
> hive --service hwi &,需要另外下载放入hive-hwiwar包
- 启动命令行
- 验证
- Hive命令
> hive -help > hive hive> show databases; OK default hive> exit;
- Hive命令
HiveQL
数据库
类似传统数据库的DataBase,系统默认使用数据库default,也可指定
> hive
hive> create database <数据库名> ;
hive> use <数据库名> ;
...
hive> drop database <数据库名>;
hive> drop database <数据库名> cascade;
表
查看表:
# 查看所有的表 show tables; # 支持模糊查询 show tables '*tmp*'; # 查看表有哪些分区 show partitions tmp_tb; #查看表详情 describe tmp_tb; describe formatted tmp_tb;- 修改表结构(alter)
alter table tmp_tb add columns (cols,string); alter table tmp_tb add if not exists partition(day='2016-04-01',city='wx'); alter table tmp_tb drop if exists partition (daytime='2016-05-01',city='sz'); alter table tmp_tb clustered by (ip) into 3 buckets; - 删除表(drop)
drop table - 清空表 (truncate)
# 无法清空外部表 truncate table table_name; # 不指定分区,将清空表中的所有分区 truncate table table_name partition (dt='20080808'); 视图(view)
CREATE VIEW v1 AS select * from t1;创建表
# 创建表 Create [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type, ...)] [PARTITIONED BY (col_name data_type, ...)] [ CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS ] [ROW FORMAT DELIMITED row_format] [STORED AS file_format] [LOCATION hdfs_path] # 复制表结构 CREATE [EXTERNAL] TABLE target_table LIKE source_table [LOCATION hdfs_path];- EXTERNAL :标识创建一个外部表
- PARTITIONED By :分区(每个分区列单独一个目录,分区列本身不会存储在数据文件中)
- CLUSTERED By :分桶,根据指定列的Hash值切分(一个桶一个数据文件,内容包含桶列)
- ROW FORMAT DELIMITED :指定数据分割符(默认只认单个字符)
- FIELDS TERMINATED BY
- LINES TERMINATED BY
- COLLECTION ITEMS TERMINATED BY
- MAP KEYS TERMINATED BY
- ...
- STORED AS :数据存储方式
- TEXTFILE 纯文本,不压缩
- SEQUENCEFILE 序列化,压缩
- LOCATION :创建表时就加载数据,指定数据文件所在位置(可选)
加载数据(Load dataset)
- LOAD Cmd:将HDFS文件导入已创建的Hive表(加载时不做检查,查询时检查)
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]!hadoop fs -ls input/hive/stocks_db; load data inpath 'input/hive/stocks_db' into table stocks; - CTAS:将Hive查询结果存放入一个新创表,原子级(select失败,table不会创建),目标表不能是分区表和外部表
CREATE TABLE [IF NOT EXISTS] table_name AS SELECT …create table stocks_ctas as select * from stocks; INSERT...SELECT:将Hive查询结果存入一个已创表
INSERT OVERWRITE|INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement FROM from_statementinsert into table stocks_ctas select s.* from stocks s; insert overwrite table stocks_ctas select s.* from stocks s; # 可以在同一个查询中使用多个insert子句 from stocks_ctas insert into t1 select id,name insert into t2 select id,tel where age>25- LOCATION:指定Hive表数据文件位置(注意:不会再移动数据文件到Hive配置的数据仓库中)
!hadoop fs -ls /user/hive/input/hive/stocks_db; create table stocks_loc(...) row format delimited fields terminated by ',' location '/user/hive/input/hive/stocks_db';
- LOAD Cmd:将HDFS文件导入已创建的Hive表(加载时不做检查,查询时检查)
说明:
Hive中有两种性质的表(Table Type):
- managed_table (Hive内部表)
- 使用Load data命令插数据时,会将数据文件
移动到数据仓库(由hive-site.xml配置的hive.metastore.warehouse.dir指定) - 使用Drop table命令删除表时,元数据(metastore的db中)与对应的数据文件都会被删除
- 使用Load data命令插数据时,会将数据文件
- external_table (Hive外部表)
- 使用Load data命令插数据时,不会将数据文件
移动到数据仓库 - 使用Drop table命令删除表时,只有元数据会被删除,实际数据文件不会有影响
- 使用Load data命令插数据时,不会将数据文件
- managed_table (Hive内部表)
Hive中表的数据类型:
- 基本数据类型
- tinyint/smallint/int/bigint
- float/double
- boolean
- string
- 复杂数据类型
- Array/Map/Struct
- 没有date/datetime
- 基本数据类型
分区表
# 使用普通表,会scan整张表,效率低
select * from stocks where symbol='XYZ' and ymd='2003-02-01';
# 使用分区表,会先找到对应分区列目录,效率高
select * from stocks_partition where symbol='XYZ' and ymd='2003-02-01';
分区表(partition table) 粗粒度的划分,分区列成了目录(为虚拟列),条件查询时可定位到目录提高效率
- 创建分区表
create table if not exists stocks_partition( col1 string, col2 string, exch_name string, yr int ) partitioned by (symbol string) row format delimited fields terminated by ',' ; 加载数据
Using
insert# add partition(symbol=B7J) data: insert into table stocks_partition partition(symbol='B7J') select col1,col2,exch_name,yr from stocks where symbol ='B7J'; # add partition(symbol=BB3) data: insert into table stocks_partition partition(symbol='BB3') select col1,col2,exch_name,yr from stocks where symbol ='BB3'; => 也合并成一个insert from stocks insert into table stocks_partition partition(symbol='B7J') select col1,col2,exch_name,yr from stocks where symbol='B7J' insert into table stocks_partition partition(symbol='BB3') select col1,col2,exch_name,yr from stocks where symbol ='BB3'; # 注意:如下方式是错误的 insert overwrite table stocks_partition partition(symbol='APPL') select col1,col2,exch_name,yr from stocks where symbol='ZUU';Using
location# add partition(symbol=ZUU) data: insert overwrite directory 'output/hive/stocks-zuu' select col1,col2,exch_name,yr from stocks where symbol='ZUU'; alter table stocks_partition add if not exists partition (symbol='ZUU') location '/output/hive/stocks-zuu'
- 添加删除分区
alter table stocks_partition add if not exists partition(symbol='ZUU'); alter table stocks_partition drop if exists partition(symbol='ZUU'); - 查看表分区
hive> show partitions stocks_partition OK symbol=B7K symbol=BB3 symbol=ZUU 数据查询
selecet * from stocks_partitions where symbol='XYZ' and ymd='2003-02-01'; # 若设置了strict方式,则select的where中一定要包含partition column条件查询 set hive.mapred.mode=strict; select * from stocks_partitions where ymd='2003-02-01';动态分区
- 创建动态分区表
create table if not exists stocks_dynamic_partition( col1 string, col2 string ) partitioned by (exch_name string,yr int,sym string) row format delimited fields terminated by ',' ; - 启动动态分区
set hive.exec.dynamic.partition=true; 加载数据(注意:默认动态分区要求至少有一个静态分区)
# 如下方式,默认会报错 # SemanticException:dynamic partition strict mode requires at least one static partition column insert overwrite table stocks_dynamic_partition partition(exch_name,yr,symbol) select col1,col2,exch_name,year(ymd),symbol from stocks; => 解决方案1: set hive.exec.dynamic.partition.mode=nostrict; => 解决方案2: insert overwrite table stocks_dynamic_partition partition(exch_name='ABCSE',yr,symbol) select col1,col2,exch_name,year(ymd),symbol from stocks;- 查看表
show partitions stocks_dynamic_partition; select * from stocks_dynamic_partition where exch_name='ABCSE' and yr=2013 limit 10; - 注意动态分区的分区数量是有限制的,可根据需要扩大设置(不推荐partition数量过多):
set hive.exec.max.dynamic.partitions=1000; set hive.exec.max.dynamic.partitions.pernode=500; - 数据表的目录结构
stocks_dynamic_partition/exch_name=ABCSE/yr=2013/symbol=GEL/ stocks_dynamic_partition/exch_name=ABCSE/yr=2013/symbol=ZUU/ stocks_dynamic_partition/exch_name=ABCSE/yr=2014/symbol=GEL/ ...
- 查看表
- 创建动态分区表
桶表
桶表(Bucket Table)
- 细粒度的划分,桶列仍在数据文件中
主要应用:
- 提高数据抽样效率
- 提升某些查询操作效率,例如mapside join
创建表
# 必须设置这个数据,hive才会按照你设置的桶的个数去生成数据 set hive.enforce.bucketing = true; create table t4(id int) clustered by(id) into 4 buckets;- 插入数据
insert into table t4 select id from t3; # 追加 insert overrite table t4 select id from t3; # 全部重写 抽样查询
# 查询带桶的表(在一部分桶上检索,效率高) select * from t4 tablesample(bucket 1 out of 4 on id); # 不带桶的表(会在整个数据集上检索,效率低) select * from t3 tablesample(bucket 1 out of 4 on id); select * from t3 tablesample(bucket 1 out of 4 on rand());- 数据表的目录结构
t4/000000_0 t4/000000_1 t4/000000_2 t4/000000_3 分区+分桶:
# 创建表 create table if not exists stocks_bucket( col1 string, col2 string, symbol string ) partitioned by (exch_name string,yr string) clustered by (symbol) into 3 buckets row format delimited fields terminated by ',' ;# 设置动态分区和使用桶 set hive.exec.dynamic.partition=true; set hive.enforce.bucketing = true; # 插入数据 insert into table stocks_bucket partition (exch_name='ABCE',yr) select col1,col2,year(ymd) from stocks# 抽样查询对比 select * from stocks tablesample(bucket 3 out of 5 on symbol) s; # 低效 select * from stocks_bucket tablesample(bucket 3 out of 5 on symbol) s; # 高效# 数据表的目录结构 stocks_bucket/exch_name=ABCE/yr=2013 stocks_bucket/exch_name=ABCE/yr=2013/000000_0 stocks_bucket/exch_name=ABCE/yr=2013/000000_1 stocks_bucket/exch_name=ABCE/yr=2013/000000_2 stocks_bucket/exch_name=ABCE/yr=2014 stocks_bucket/exch_name=ABCE/yr=2014/000000_0 stocks_bucket/exch_name=ABCE/yr=2014/000000_1 stocks_bucket/exch_name=ABCE/yr=2014/000000_2 ...
抽样
tablesample 抽样
- tablesample(n precent/rows)
- n precent
- n rows
- tablesample(nM)
- n兆
tablesample(bucket x out of y [on columns])
- x: 从第几个桶开始抽样(从1开始)
- y: 抽样的桶数(若是分桶表,则必须为总bucket数的倍数或者因子)
- columns: 抽样的列
- 注意:
- 基于已经分桶的表抽样,查询只会扫描相应桶中的数据
- 基于未分桶表的抽样,查询时候需要扫描整表数据
示例:
# 1. t1 为未分桶表 # 1.1 scan全表,根据col1分为10个桶,从第3个桶中取数据; select * from t1 tablesample(bucket 3 out of 10 on col1); # 1.2 scan全表,根据随机数分为10个桶,从第3个桶中取数据; select * from t1 tablesample(bucket 3 out of 10 on rand()); # 2. t2 为分桶表,有10个桶 # 2.1 直接从第3个桶中取数据 select * from t2 tablesample(bucket 3 out of 10 on col1); # 2.2 共抽取2(10/5)个桶的数据,从第3个和第8(3+5)个桶中抽取数据 select * from t2 tablesample(bucket 3 out of 5 on col1); # 2.3 共抽取0.5(10/20)个桶的数据,从第3个桶中抽取一半数据 select * from t2 tablesample(bucket 3 out of 20 on col1);
- 例如:
- tablesample(50 precent)
- tablesample(50 rows)
- tablesample(50M)
- tablesample(bucket 3 out of 10)
- tablesample(bucket 3 out of 10 on rand())
单表查询
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE condition]
[GROUP BY col_list] [Having condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] | [ORDER BY col_list] ]
[LIMIT number]
- where:过滤(mapper端)
- group by:局部分组(reducer端),select中可使用一些聚合函数,例如sum,avg,count等
- cluster by:等价于distribute by + sort by ,只是无法指定排序规则(默认asc)
- distribute by:分区(partitioner),按指定字段划分数据到各个reduce/file
- sort by:局部排序(reducer端)
- order by:全局排序,只有一个reducer(数据量很大时慎用)
- limit:减少数据量,传输到reduce端(单机)的数据记录数就减少到
n*(map个数)
示例:
- 加查询结果写入HDFS中
insert overwrite local directory '/home/hive/output/hive/stocks' row format delimited fields terminated by ',' select * from stocks distributed by symbol sort by symbol asc,price_close desc; - 全局排序 order by
# 无论设置了多少个reducer,这里只会使用一个reducer(数据量很大时效率低) set mapreduce.job.reduces=3; select * from stocks order by price_close desc; - 局部排序 sort by
# 每个reducer中排序 set mapreduce.job.reduces=3; select * from stocks sort by price_close desc; - 分区 distribute/cluster by
# distribute by 控制某个特定行应该到哪个reducer # sort by 为每个reducer产生一个排好序的文件 # distribute by + sort by = cluster by set mapreduce.job.reduces=3; select * from stocks distributed by symbol sort by symbol asc; select * from stocks cluster by symbol; - 聚合操作 group by
select symbol,count(*) from stocks group by symbol; - Top N查询
SET mapred.reduce.tasks = 1 SELECT * FROM sales SORT BY amount DESC LIMIT 5
连接查询
使用Join
{inner} join,{left|right|full} [outer] join,cross joinSELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department); SELECT a.* FROM a LEFT JOIN b ON (a.id = b.id AND a.department = b.department); SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2);- 特例:
LEFT SEMI JOINSELECT a.key, a.value FROM a WHERE a.key in (SELECT b.key FROM B); SELECT a.key, a.val FROM a LEFT SEMI JOIN b ON (a.key = b.key);
Hive中的Join可分为:
- Common Join(Reduce阶段完成join)
- Map阶段:读取源表的数据,以Join on条件中的列为key,以join后所关心的(select或者where中需要用到的)列为value(value中包含Tag,用于标明此value对应哪个表)
- Shuffle阶段:根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
- Reduce阶段:根据key的值完成join操作,通过Tag识别不同表中的数据
- Map Join(Map阶段完成join):通常用于一个很小的表和一个大表进行join的场景
- Local Task(Client端本地执行):扫描小表,装载到DistributeCache中
- Map Task:读取DistributeCache数据至内存,遍历大表记录,两者进行join,输出结果
- 无Reducer Task
- Common Join(Reduce阶段完成join)
Hive中的join操作
join操作是在where操作之前执行,即where条件不能起到减少join数据的作用,应尽量在
on中加入约束条件SELECT a.val, b.val FROM a JOIN b ON (a.key=b.key) WHERE a.ds='2009-07-07' AND b.ds='2009-07-07' => 优化为: SELECT a.val, b.val FROM a JOIN b ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07')多表连接,会转换成多个MR Job,但关联条件相同的多表join会自动优化成一个mapreduce job
# 在两个mapred程序中执行join SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) # 在一个mapre程序中执行join SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)- 多表连接,前一个join生成的数据会缓存到内存,通过stream取后一张表数据,应尽量将记录多的表放在后面join,也可使用
/*+ STREAMTABLE(table) */指定将哪个大表stream化SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) Map Side Join
- 可在查询中使用
/*+ mapjoin(table) */指定将哪个小表装载到DistributeCache中# 注意: 这里无法使用a FULL/RIGHT JOIN b SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a join b on a.key = b.key; - Auto Map Side Join:系统自动判断使用mapjoin(由参数hive.auto.convert.join决定,默认为true)
# Local Task 中找出符合mapjoin条件的表,装载到DistributeCache中,后续使用map join;若未找到符合条件的表,则使用common join set hive.auto.convert.join=true; # 根据参数hive.mapjoin.smalltable.filesize的设置判断mapjoin的表 SELECT a.key, a.value FROM a join b on a.key = b.key; - 与map join相关的hive参数
# hive.join.emit.interval # hive.auto.convert.join # hive.mapjoin.smalltable.filesize # hive.mapjoin.size.key # hive.mapjoin.cache.numrows Sort Map Bucket Map Join:根据join key将各个关联表进行Bucket,提高join效率
# 创建分桶表 create table a_smb(...) clustered by (key) sort by (key) into 10 buckets; create table b_smb(...) clustered by (key) sort by (key) into 5 buckets; # 为分桶表加载数据 set hive.enforce.bucketing=true; insert into table a_smb select * from a; insert into table b_smb select * from b; # 打开SMB Map Join set hive.auto.convert.sortmerge.join=true; set hive.optimize.bucketmapjoin = true; set hive.optimize.bucketmapjoin.sortedmerge = true; set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat; select * from a_smb a join b_smb on a.key=b.key;
- 可在查询中使用
示例
示例1:导入Apache log
- log格式:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 创建表:
CREATE TABLE apachelog ( host STRING, identity STRING, username STRING, time STRING, request STRING, status STRING, size STRING, referer STRING, agent STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?", "output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s" ) STORED AS TEXTFILE;添加jar包到hive的执行环境:
add jar $HIVE_HOME/lib/hive-contrib-1.2.1.jar- 加载数据:
# inpath will be deleted! load data inpath '/input/access_2013_05_31.log' into table apachelog; - 查询:
show tables; describe formatted apachelog; select * from apachelog limit 10; select count(*) from apachelog; select status,count(*) from apachelog group by status; - HDFS目录:
/user/hive/warehouse/apachelog /user/hive/warehouse/apachelog/access_2013_05_31.log
示例2:创建内部表
- 创建内部表log:
create table log( ip string, datetime string, method string, url string, status string, size string ) row format delimited fields terminated by ',' ; 插入数据:
insert into table log select host,time,substring(split(request,' ')[0],2) as method,split(request,' ')[1] as url,status,size from apachelog; # 重新过滤掉某些数据(hive中没有delete操作,只能overwrite) insert overwrite table log select * from log where length(method)<7 and method in ('GET','POST','PUT','DELETE','OPTION','HEAD');查询:
describe formatted log; set mapred.reduce.tasks=3; select method from log where length(method)<7 group by method; select status,method,count(*) from log group by status,method;- HDFS目录:
/user/hive/warehouse/log /user/hive/warehouse/log/000000_0
示例3:内部静态分区表
- 创建内部分区表log_partition:(注意分区字段不能包含在建表字段中)
create table log_partition( ip string, datetime string, url string, size string ) partitioned by (status string,method string) row format delimited fields terminated by ',' ; 插入partition数据:(使用insert...select)
insert into table log_partition partition(status='200',method='GET') select ip,datetime,url,size from log where status='200' and method='GET'; insert into table log_partition partition(status='200',method='POST') select ip,datetime,url,size from log where status='200' and method='POST' from log insert overwrite table log_partition partition(status='301',method='GET') select ip,datetime,url,size where status='301' and method='GET' insert overwrite table log_partition partition(status='301',method='POST') select ip,datetime,url,size where status='301' and method='POST' insert overwrite table log_partition partition(status='400',method='GET') select ip,datetime,url,size where status='400'and method='GET';插入partition数据:(使用alter...location)
insert overwrite directory '/user/hive/warehouse/log_partition/status=400/method=POST' row format delimited fields terminated by ',' select ip,datetime,url,size from log where status='400' and method='POST'; alter table log_partition add if not exists partition (status='400',method='POST') location '/user/hive/warehouse/log_partition/status=400/method=POST';- 删除partition数据:(注意会删除partition对应的目录和文件)
alter table log_partition drop if exists partition (status='301',method='GET'); - 查看:
describe formatted log_partition; show partitions log_partition; select * from log_partition where status='400' and method='POST'; - HDFS目录:
/user/hive/warehouse/log_partition /user/hive/warehouse/log_partition/status=200 /user/hive/warehouse/log_partition/status=200/method=GET /user/hive/warehouse/log_partition/status=200/method=GET/000000_0 /user/hive/warehouse/log_partition/status=301 /user/hive/warehouse/log_partition/status=301/method=POST /user/hive/warehouse/log_partition/status=301/method=POST/000000_0 /user/hive/warehouse/log_partition/status=400 /user/hive/warehouse/log_partition/status=400/method=GET /user/hive/warehouse/log_partition/status=400/method=GET/000000_0 /user/hive/warehouse/log_partition/status=400/method=POST /user/hive/warehouse/log_partition/status=400/method=POST/000000_0
示例4:内部动态分区表
- 创建内部分区表log_dynamic_partition:
create table log_dynamic_partition like log_partition; - 打开动态分区:
set hive.exec.dynamic.partition=true; - 插入数据:(注意:1. 字段和顺序;2. 第一个为静态partition)
insert into table log_dynamic_partition partition(status='200',method) select ip,datetime,url,size,method from log where status='200'; - 插入数据:(注意:1. 字段和顺序;2. 所有都为动态partition)
# 设置为nostrict模式 set hive.exec.dynamic.partition.mode=nostrict; # 插入 insert overwrite table log_dynamic_partition partition(status,method) select ip,datetime,url,size,status,method from log; - 查看:
describe formatted log_dynamic_partition; show partitions log_dynamic_partition; select * from log_dynamic_partition where status='400' and method='POST'; - HDFS目录:
/user/hive/warehouse/log_dynamic_partition /user/hive/warehouse/log_dynamic_partition/status=200 /user/hive/warehouse/log_dynamic_partition/status=200/method=GET /user/hive/warehouse/log_dynamic_partition/status=200/method=GET/000000_0 /user/hive/warehouse/log_dynamic_partition/status=301 /user/hive/warehouse/log_dynamic_partition/status=301/method=GET /user/hive/warehouse/log_dynamic_partition/status=301/method=GET/000000_0 /user/hive/warehouse/log_dynamic_partition/status=301/method=POST /user/hive/warehouse/log_dynamic_partition/status=301/method=POST/000000_0 /user/hive/warehouse/log_dynamic_partition/status=400 /user/hive/warehouse/log_dynamic_partition/status=400/method=GET /user/hive/warehouse/log_dynamic_partition/status=400/method=GET/000000_0 /user/hive/warehouse/log_dynamic_partition/status=400/method=POST /user/hive/warehouse/log_dynamic_partition/status=400/method=POST/000000_0 ...
示例5:内部表分桶
- 创建分桶表log_bucket: (注意:分桶字段为建表中的字段)
create table log_bucket( ip string, datetime string, method string, url string, status string, size string ) clustered by (status,method) into 5 buckets row format delimited fields terminated by ',' ; - 打开分桶:
set hive.enforce.bucketing = true; - 插入数据:
insert into table log_bucket select * from log; - 查看:
describe formatted log_bucket; select * from log_bucket tablesample(bucket 1 out of 5 on status); select * from log tablesample(bucket 1 out of 5 on status); - HDFS目录:
/user/hive/warehouse/log_bucket /user/hive/warehouse/log_bucket/000000_0 /user/hive/warehouse/log_bucket/000001_0 /user/hive/warehouse/log_bucket/000002_0 /user/hive/warehouse/log_bucket/000003_0 /user/hive/warehouse/log_bucket/000004_0
示例6:内部分区分桶表
- 创建分区分桶表log_partition_bucket:
create table log_partition_bucket( ip string, datetime string, url string, size string ) partitioned by (status string,method string) clustered by (ip) into 5 buckets row format delimited fields terminated by ',' ; - 打开动态分区和分桶:
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nostrict; set hive.enforce.bucketing = true; - 插入数据:
insert into table log_partition_bucket partition(status,method) select ip,datetime,url,size,status,method from log; - 查看:
describe formatted log_partition_bucket; select * from log_partition_bucket tablesample(bucket 1 out of 5 on status) limit 5; - HDFS目录:
/user/hive/warehouse/log_partition_bucket /user/hive/warehouse/log_partition_bucket/status=200 /user/hive/warehouse/log_partition_bucket/status=200/method=GET /user/hive/warehouse/log_partition_bucket/status=200/method=GET/000000_0 /user/hive/warehouse/log_partition_bucket/status=200/method=GET/000001_0 /user/hive/warehouse/log_partition_bucket/status=200/method=GET/000002_0 /user/hive/warehouse/log_partition_bucket/status=200/method=GET/000003_0 /user/hive/warehouse/log_partition_bucket/status=200/method=GET/000004_0 /user/hive/warehouse/log_partition_bucket/status=301 /user/hive/warehouse/log_partition_bucket/status=301/method=GET /user/hive/warehouse/log_partition_bucket/status=301/method=GET/000000_0 /user/hive/warehouse/log_partition_bucket/status=301/method=GET/000001_0 /user/hive/warehouse/log_partition_bucket/status=301/method=GET/000002_0 /user/hive/warehouse/log_partition_bucket/status=301/method=GET/000003_0 /user/hive/warehouse/log_partition_bucket/status=301/method=GET/000004_0 /user/hive/warehouse/log_partition_bucket/status=301/method=POST /user/hive/warehouse/log_partition_bucket/status=301/method=POST/000000_0 /user/hive/warehouse/log_partition_bucket/status=301/method=POST/000001_0 /user/hive/warehouse/log_partition_bucket/status=301/method=POST/000002_0 /user/hive/warehouse/log_partition_bucket/status=301/method=POST/000003_0 /user/hive/warehouse/log_partition_bucket/status=301/method=POST/000004_0 ...
示例6:外部表
- 创建外部表log_external:
create external table log_external( ip string, datetime string, method string, url string, status string, size string ) row format delimited fields terminated by ',' location '/input/external'; 插入数据:
# generate file: /input/external/000000_0 insert into table log_external select * from log where status='200'; # generate file: /input/external/000000_0_copy_1 insert into table log_external select * from log where status='400';插入数据:
# generate file: /input/log_301/000000_0 insert overwrite directory '/input/log_301' row format delimited fields terminated by ',' select * from log where status='301'; # generate file: /input/external/000000_0_copy_2 # delete file: /input/log_301/000000_0 load data inpath '/input/log_301' into table log_external;- 查看:
describe formatted log_external; select * from log_external limit 5; select * from log_external where status='400' limit 5; select * from log_external where status='301' limit 5; - HDFS目录:
/input/external/000000_0 /input/external/000000_0_copy_1 /input/external/000000_0_copy_2 - 删除表:(注意:1. 无法使用truncate清空外部表;2. 数据文件不会被删除)
drop table log_external; - 重新创建外部表:(不用重新插入数据就有数据可查出了)
create external table log_external( ip string, datetime string, method string, url string, status string, size string ) row format delimited fields terminated by ',' location '/input/external'; - 查看表:
describe formatted log_external; select * from log_external limit 5; select * from log_external where status='400' limit 5; select * from log_external where status='301' limit 5;
示例7:外部分区分桶表
- 创建外部分区分桶表log_external_partition:
create external table log_external_partition( ip string, datetime string, url string, size string ) partitioned by (status string,method string) clustered by (ip) into 5 buckets row format delimited fields terminated by ',' location '/input/external_partition'; 插入partition数据: (alter location)
insert overwrite directory '/input/log_301_GET' row format delimited fields terminated by ',' select ip,datetime,url,size from log where status='301' and method='GET'; # generate file: /input/log_301_GET/000000_0~000004_0 alter table log_external_partition add partition (status='301',method='GET') location '/input/log_301_GET';插入partition数据:(动态分区)
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nostrict; set hive.enforce.bucketing = true; # generate file: # /input/log_301_GET/000000_0_copy_1 # /input/external_partition/status=xxx/method=yyy/000000_0~000004_0 insert into table log_external_partition partition(status,method) select ip,datetime,url,size,status,method from log;HDFS目录:
/input/log_301_GET /input/log_301_GET/000000_0 /input/log_301_GET/000000_0_copy_1 /input/log_301_GET/000001_0 /input/log_301_GET/000002_0 /input/log_301_GET/000003_0 /input/log_301_GET/000004_0 /input/external_partition /input/external_partition/status=200 /input/external_partition/status=200/method=GET /input/external_partition/status=200/method=GET/000000_0 /input/external_partition/status=200/method=GET/000001_0 /input/external_partition/status=200/method=GET/000002_0 /input/external_partition/status=200/method=GET/000003_0 /input/external_partition/status=200/method=GET/000004_0 /input/external_partition/status=301 /input/external_partition/status=301/method=POST /input/external_partition/status=301/method=POST/000000_0 /input/external_partition/status=301/method=POST/000001_0 /input/external_partition/status=301/method=POST/000002_0 /input/external_partition/status=301/method=POST/000003_0 /input/external_partition/status=301/method=POST/000004_0 ...
示例8:全排序
使用order by (不管设置几个reducer,最终只使用一个reducer)
set mapred.reduce.tasks=5; # 全排序 insert overwrite directory '/input/log_order' select ip,size from log order by ip; # 局部排序 insert overwrite directory '/input/log_distribute' select ip,size from log distribute by ip sort by size; # 全排序(数据量很大时,效率会高些) insert overwrite directory '/input/log_order_opt' select * from (select ip,size from log distribute by ip sort by size) s order by ip;- 使用TotalOrderSort
- 生成抽样文件
- 使用TotalOrderSort
示例9:Join
创建两张表并插入数据:(create table as select)
create table a_log row format delimited fields terminated by ',' as select * from log where status='200'; create table b_log row format delimited fields terminated by ',' as select * from log where status='301';- 查询: (会自动判断使用mapjoin)
select * from a_log a join b_log b on a.ip=b.ip where a.method='POST' limit 5; select * from a_log a join b_log b on a.ip=b.ip and a.method='POST' limit 5; - HDFS目录:
/user/hive/warehouse/a_log /user/hive/warehouse/a_log/000000_0 /user/hive/warehouse/b_log /user/hive/warehouse/b_log/000000_0 创建两张分区表并插入数据:
create table a_log_smb like a_log; create table b_log_smb like b_log; alter table a_log_smb clustered by (ip) into 3 buckets; alter table b_log_smb clustered by (ip) into 5 buckets; insert into a_log_smb select * from a_log; insert into b_log_smb select * from b_log;- 查询:(SMP)
select * from a_log_smb a join b_log_smb b on a.ip=b.ip limit 5; - HDFS目录:
/user/hive/warehouse/a_log_smb /user/hive/warehouse/a_log_smb/000000_0 /user/hive/warehouse/a_log_smb/000001_0 /user/hive/warehouse/a_log_smb/000002_0 /user/hive/warehouse/b_log_smb /user/hive/warehouse/b_log_smb/000000_0 /user/hive/warehouse/b_log_smb/000001_0 /user/hive/warehouse/b_log_smb/000002_0 /user/hive/warehouse/b_log_smb/000003_0 /user/hive/warehouse/b_log_smb/000004_0
优化策略
数据倾斜:由于数据的不均衡原因,导致数据分布不均匀,造成数据大量的集中到一点,造成数据热点
Hadoop 计算框架特性:
- 不怕数据大,怕数据倾斜
- job过多,耗时长(job初始化时间长)
常用优化手段:
- 减少Job数
- 并行Job,例如设置:
# 对于同一个SQL产生的JOB,如果不存在依赖的情况下,将会并行启动JOB set hive.exec.parallel=true; set hive.exec.parallel.thread.number=16; 合理设置Mapper和Reducer数
- 减少mapper数:合并小文件
# 100~128M的按照100M分割,<100M合并 set mapred.max.split.size=100000000; set mapred.min.split.size.per.node=100000000; set mapred.min.split.size.per.rack=100000000; set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; - 增加mapper数:拆分文件(分区,分桶)
reducer数
# 每个reduce任务处理的数据量,默认为1000^3=1G hive.exec.reducers.bytes.per.reducer # 每个任务最大的reduce数,默认为999 hive.exec.reducers.max # 设置reducer数量 mapred.reduce.tasks
- 减少mapper数:合并小文件
合理压缩,减少网络传输和I/O压力,例如设置:
set mapred.output.compress = true; set mapred.output.compression.codec = org.apache.hadoop.io.compress.GzipCodec; set mapred.output.compression.type = BLOCK; set mapred.compress.map.output = true; set mapred.map.output.compression.codec = org.apache.hadoop.io.compress.LzoCodec; set hive.exec.compress.output = true; set hive.exec.compress.intermediate = true; set hive.intermediate.compression.codec = org.apache.hadoop.io.compress.LzoCodec;- 以SequenceFile保存,节约序列化和反序列化时间
- 少用count distinct,例如:
select status,count(distinct ip) from log group by status; => select status,count(ip) from (select status,ip from log group by status,ip) a group by status; - join优化
- 尽量将condition放入join on中
- 尽量大表滞后或使用STREAMTABLE(table)标识大表
- 使用SMB Map Join (SMB: Sort Merge Bucket)
- 合理分区,分桶
- 小数据量,尽量使用本地MapReduce,例如设置:
set hive.exec.mode.local.auto=true; set hive.exec.mode.local.auto.inputbytes.max=50000000; set hive.exec.mode.local.auto.tasks.max=10;
自定义函数
查看函数
SHOW FUNCTIONS;
DESCRIBE FUNCTION <function_name>
自定义函数包括三种UDF、UDAF、UDTF,可直接应用于Select语句
- UDF:User-Defined-Function
- 用户自定义函数(只能实现一进一出的操作)
extends UDF
- UDAF:User-Defined Aggregation Funcation
- 用户自定义聚合函数(可实现多进一出的操作)
extends UDAF+ 内部Evaluatorimplements UDAFEvaluator- init 初始化
- iterate 遍历
- terminatePartial 类似Hadoop的Combiner
- merge 合并
- terminate 返回最终的聚集函数结果
- UDTF:User-Defined Table-Generating Function
- 用户自定义表函数(可实现一进多出的操作)
extends GenericUDTF
UDF示例:
- 自定义函数
import org.apache.Hadoop.hive.ql.exec.UDF public class Helloword extends UDF{ public String evaluate(){ return "hello world!"; } public String evaluate(String str){ return "hello world: " + str; } } - 上传jar包到目标机器
- 添加到Hive中
# 进入hive客户端,添加jar包 hive> add jar udf_helloword.jar - 创建临时函数
hive> create temporary function helloword as 'com.cj.hive.udf.Helloword' - 测试
select helloword(name) from users; - 删除临时函数
hive> drop temporaty function helloword;
注:helloworld为临时的函数,所以每次进入hive都需要add jar以及create temporary操作
Java API
- 启动Hive远程服务
> hive --service hiveserver2 >/dev/null 2>/dev/null & - Java客户端加入依赖包
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>${hive.version}</version> </dependency> JAVA客户端连接操作代码
@Test public void testConnection() throws ClassNotFoundException, SQLException { Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection("jdbc:hive2://cj.storm:10000/default", "", ""); Statement stmt = conn.createStatement(); String querySQL = "select * from log_partition where status='200' and method='GET' limit 10"; ResultSet res = stmt.executeQuery(querySQL); while (res.next()) { System.out.println(res.getString(1) + "\t" + res.getString(2)); } res.close(); conn.close(); }