概述
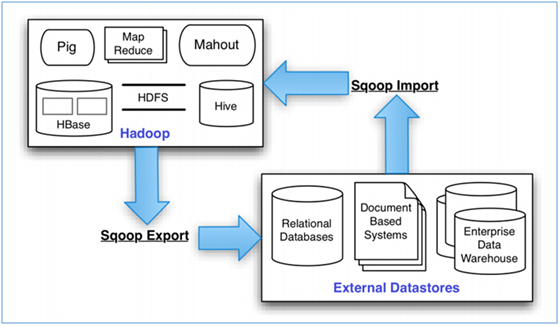
SQOOP -- 使用MapReduce实现用于对数据进行导入导出
- Import: 把MySQL、Oracle等数据库中的数据导入到HDFS、Hive、HBase中
- Export: 把HDFS、Hive、HBase中的数据导出到MySQL、Oracle等数据库中
- 注意:导入导出的事务是以Mapper任务为单位
- 官网
- 用户手册
安装
- 下载解压
- 配置环境变量(
/etc/profile)- SQOOP_HOME
- HADOOP_HOME
- PATH
- 将要使用的JDBC Connector Jar包放入
$SQOOP_HOME/lib下
使用示例
查询
list databases
sqoop list-databases \ --connect jdbc:mysql://cj.storm:3306 --username root --password cj123list tables
sqoop list-tables \ --connect jdbc:mysql://cj.storm:3306/hive --username root --password cj123- list jobs
sqoop job --list
Import(MySQL=>HDFS)
一些参数说明:
-m <num>: 使用的mapper数(注意:对于无主键的表,需要增加参数--split-by xxx或-m 1)--warehouse-dir <path>: 指定存放的数据仓库(默认:/user/{USER_NAME})--target-dir <path>: 指定存放的数据路径 (默认:/user/{USER_NAME}/{tablename})--null-string <str>: 指定用什么代表空字段(默认:NULL)--hive-import: 表导入到hive中--hive-table <tablename>: hive table name--hive-overwrite: overwite hive tablemysql table => hdfs file:# use --warehouse-dir # final file: /output/log/part-m-00000 sqoop import \ --connect jdbc:mysql://cj.storm:3306/sqoop --username root --password cj123 \ --table log --fields-terminated-by ',' \ --warehouse-dir '/output' \ -m 1 # use --target-dir & query # final file: /output/log_2/part-m-00000 sqoop import \ --connect jdbc:mysql://cj.storm:3306/sqoop --username root --P \ --query "select * from log where \$CONDITIONS" \ --target-dir /output/log_2 \ -m 1 # use --target-dir & columns & where sqoop import \ --connect jdbc:mysql://cj.storm:3306/sqoop --username root --password cj123 \ --table log \ --columns "ip,status,method" \ --where "status='200' and method in ('GET','POST')" \ -m 1 \ --target-dir /output/log_3 \ --fields-terminated-by ","mysql table => hive table:# use hive-import sqoop import --connect jdbc:mysql://cj.storm:3306/hive --username root --password cj123 --table TBLS --fields-terminated-by '\t' --null-string '**' -m 1 --hive-import # use hive-import & hive-table sqoop import \ --connect jdbc:mysql://cj.storm:3306/hive --username root --password cj123 \ --table TBLS \ --fields-terminated-by '\t' \ --null-string '**' \ -m 1 \ --hive-import \ --hive-table 'tbls_2' # check hive table hive -e 'describe formatted tbls' hive -e 'describe formatted tbls_2'mysql table schema => hive table schema:# just copy table schema (no data) sqoop create-hive-table \ --connect jdbc:mysql://cj.storm:3306/sqoop --username root --password cj123 \ --table log \ --hive-table log_sqoop \ --fields-terminated-by ','
Job
- create job:
sqoop job \ --create myjob \ -- import --connect jdbc:mysql://cj.storm:3306/hive --username root -P \ --table TBLS \ --fields-terminated-by '\t' \ --null-string '**' \ -m 1 \ --hive-import \ --hive-table 'tbls_4' - exec job:
sqoop job --exec myjob - 查看 job:
sqoop job --list sqoop job --show myjob - 删除 job:
sqoop job --delete myjob