概述
Hadoop2中有两个重要的变更:
- DFS的NameNode可以以集群的方式布署,增强了NameNodes的水平扩展能力和高可用性,分别是:HDFS Federation与HA;
- MapReduce将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的组件,并更名为YARN(Yet Another Resource Negotiator)
HDFS
1.x缺点
Namenode problems:
- Only One
- under great memory pressure
SecondaryNamenode problems:
- It’s confusing name
- No up-to-date FSIMAGE file
- No automatic failover
2.x改进
Muti-Namenode (水平扩展和高可用)
- Federation (different namespace)
- 多个Namenode,一组Datanode
- 使用不同的HDFS目录(即不同的namespace,互不影响)
- 应用举例:不同Federation HDFS配置使用不同的Block大小以处理不同的需求
- HA (same namespace)
- 多个Namenode,一组Datanode
- 使用相同的HDFS目录(即相同的namespace,只有一个Namenode负责读写)
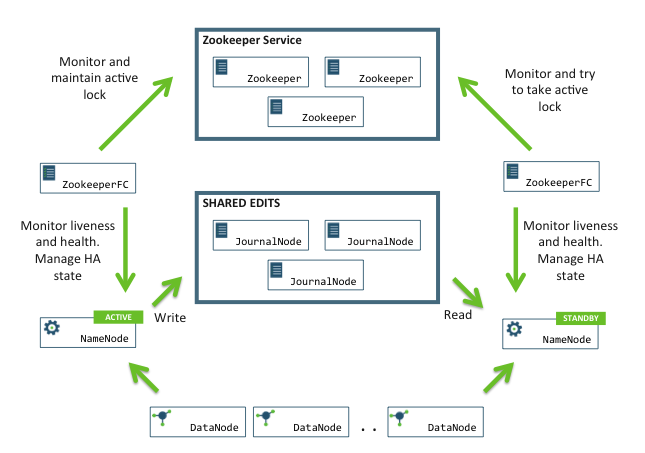
- 只有一个Namenode为Active,对外提供读写服务,其他为StandBy
- Active NN 一旦故障便自动切换到 standby NN(借助Zookeeper完成热切)
- 系统通过JournalNodes守护进程使Standby和Active的Namenode保持元数据同步
- Active NN 将修改持久化(写)到JournalNodes
- StandBy NN 从JournalNodes读取修改信息,更新内部元数据
- JournalNodes是轻量级的进程(通过editlog持久化存储),需为奇数个
- 注意:Standby NN也执行namespace状态的checkpoints,所以不要再运行Secondary NN、CheckpointNode、BackupNode
 (图片来自 http://blog.csdn.net/jiewuyou)
(图片来自 http://blog.csdn.net/jiewuyou)
HDFS示例
Nodes DNS:
- cluster1 namenode
- masterA.cls1
- masterB.cls1
- cluster2 namenode
- masterA.cls2
- masterB.cls2
- datanode
- slave1.cls
- slave2.cls
- slave3.cls
- zookeeper
- slave1.cls
- slave2.cls
- slave3.cls
- journalnode
- slave1.cls
- slave2.cls
- slave3.cls
Configuration
hadoop-env.sh (on all nodes)
export JAVA_HOME=/usr/local/jdk1.8Cluster1 (on masterA.cls1,masterB.cls1)
- core-site.sh
<property> <name>fs.defaultFS</name> <value>hdfs://cluster1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>slave1.cls:2181,slave2.cls:2181,slave3.cls:2181</value> </property> hdfs-site.xml
<property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.nameservices</name> <value>cluster1,cluster2</value> </property> <!-- journal nodes --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://slave1.cls:8485;slave2.cls:8485;slave3.cls:8485/cluster1</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/hadoop/tmp/journal</value> </property> <!-- Using ssh to switch namenode --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- Cluster1 --> <property> <name>dfs.ha.namenodes.cluster1</name> <value>masterA.cls1,masterB.cls1</value> </property> <property> <name>dfs.namenode.rpc-address.cluster1.masterA.cls1</name> <value>masterA.cls1:9000</value> </property> <property> <name>dfs.namenode.http-address.cluster1.masterA.cls1</name> <value>masterA.cls1:50070</value> </property> <property> <name>dfs.namenode.rpc-address.cluster1.masterB.cls1</name> <value>masterB.cls1:9000</value> </property> <property> <name>dfs.namenode.http-address.cluster1.masterB.cls1</name> <value>masterB.cls1:50070</value> </property> <property> <name>dfs.ha.automatic-failover.enabled.cluster1</name> <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.cluster1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- Cluster2 --> <property> <name>dfs.ha.namenodes.cluster2</name> <value>masterA.cls2,masterB.cls2</value> </property> <property> <name>dfs.namenode.rpc-address.cluster2.masterA.cls2</name> <value>masterA.cls2:9000</value> </property> <property> <name>dfs.namenode.http-address.cluster2.masterA.cls2</name> <value>masterA.cls2:50070</value> </property> <property> <name>dfs.namenode.rpc-address.cluster2.masterB.cls2</name> <value>masterB.cls2:9000</value> </property> <property> <name>dfs.namenode.http-address.cluster2.masterB.cls2</name> <value>masterB.cls2:50070</value> </property> <property> <name>dfs.ha.automatic-failover.enabled.cluster2</name> <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.cluster2</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
- core-site.sh
Cluster2 (on masterA.cls2,masterB.cls2)
- core-site.sh (copy from cluster1) update:
<property> <name>fs.defaultFS</name> <value>hdfs://cluster2</value> </property>- hdfs-site.xml (copy from cluster1) update:
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://slave1.cls:8485;slave2.cls:8485;slave3.cls:8485/cluster2</value> </property>
- hdfs-site.xml (copy from cluster1) update:
- core-site.sh (copy from cluster1) update:
slaves (on all nodes)
slave1.cls slave2.cls slave3.cls
Run
- start zookeeper
# slave1.cls,slave2.cls,slave3.cls zkServer.sh start start namenode
# slave1.cls,slave2.cls,slave3.cls sbin/hadoop-daemon.sh start journalnode # masterA.cls1,masterB.cls1 bin/hdfs zkfc -formatZK # masterA.cls1 bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode # masterB.cls1 bin/hdfs namenode -bootstrapStandby sbin/hadoop-daemon.sh start namenode # masterA.cls1,masterB.cls2 sbin/hadoop-daemon.sh start zkfc- start datanode
# slave1.cls,slave2.cls,slave3.cls sbin/hadoop-daemons.sh start datanode
MapReduce
1.x缺点
- JobTracker under greate pressure
- Job Coordination
- Scheduling
- Resource Management
- Cluster 资源利用率不高 (不同作业需要搭建不同的集群环境)
2.x改进
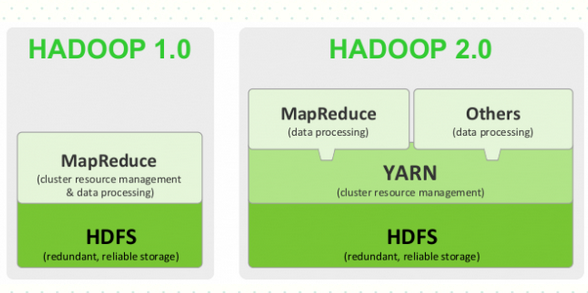
引入Yarn
- JobTracker的功能分离成Yarn的两个单独的组件完成
- ResourceManager 全局管理所有应用程序计算资源的分配
- ApplicationMaster 负责某一应用的任务调度和协调(每个应用一个,例如MapReduce,Storm,Spark等)
- Yarn具有通用性,因此整个集群也可作为其他计算框架的管理平台(例如Spark,Storm等)
Yarn
Yarn:
- 一套资源统一管理和调度的平台
- 可管理各种计算框架,包括 MapReduce 、 Spark 、 Strom 等
说明:
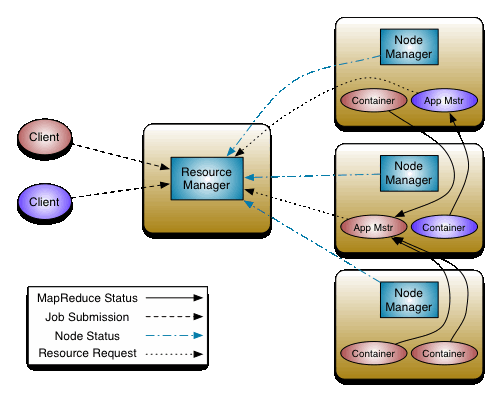
ResourceManager
- YARN集群的Master,负责管理整个集群的资源分配和作业调度
- 接收提交的job,根据job的Context,NodeManager反馈的status,启动分配一个NodeManager的Container作为ApplicationManager
- 主要包含两个组件:
- Scheduler 负责将集群资源分配给应用程序
- ApplicationManager 负责接收任务,调度启动每个Job所属的ApplicationMaster, 监控重启ApplicationMaster
NodeManager
- YARN集群的Slave,是集群中实际拥有实际资源的工作节点
- 负责Container状态的维护,并向RM保持心跳(类似RM在每台机器的上代理)
- 注:
- RM可将某个NM上的Container分配给某个Job的AppMstr
- AppMstr将组成Job的多个Task调度到对应的NM上进行执行
- 一般DN和NM在同一个节点
ApplicationMaster
- 负责申请资源,监控管理任务运行(一个Job生命周期内的所有工作)
- 比如:
- 运行Task的资源,由AM向RM申请;
- 启动/停止NM上某Task的对应的Container,由AM向NM请求来完成
- 是一个可变部分,用户可对不同编程模型写自己的AM实现,让更多类型的编程模型能够跑在此集群中
Container
- 资源的抽象,Yarn为了作资源隔离而提出的一个框架
- 对NodeManager上的资源进行量化,组装成一个个Container,服务于已授权资源的任务
- 完成任务后,系统回收资源,供后续任务申请使用
- 资源包括:内存,CPU,硬盘,网络等
- 对于资源的表示以内存为单位,比之前以剩余slot数目更合理
- 资源的抽象,Yarn为了作资源隔离而提出的一个框架
Yarn配置示例
Configuration
- mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> - yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>masterA.cls1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> ...
Run
# masterA.cls1
sbin/start-yarn.sh
sbin/stop-yarn.sh