Starter
一套基于
Twisted事件驱动的异步爬虫框架是为持续运行设计的专业爬虫框架,提供了操作的Scrapy命令行
VS. Requests
Requests Scrapy 功能库,重点在于页面下载(页面级爬虫) 框架,重点在于爬虫结构(网站级爬虫) 阻塞IO 基于 Twisted事件驱动,异步并发性考虑不足 并发性好 定制灵活 一般定制灵活,深度定制困难 场景:小需求 场景:大需求 install:
pip install scrapycheck:
scrapy -h$ scrapy -h Scrapy 1.6.0 - no active project Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy [ more ] More commands available when run from project directory Use "scrapy <command> -h" to see more info about a command
使用
创建工程:
scrapy startproject <name> [dir]
创建
Spider:- 在工程中产生一个Scrapy爬虫:
scrapy genspider [options] <spiderName> <domain> - 编写
vi <spiderName>.py- start_urls: 初始URL地址
- parse(response): 获取页面后的解析处理
- 在工程中产生一个Scrapy爬虫:
编写
Item Pipeline:pipelines.py: 定义对爬取项Scraped Item的处理类setting.py: 添加到ITEM_PIPELINES配置项
配置优化
- 配置
settings.py文件 - eg: 配置并发连接选项
CONCURRENT_REQUESTS:Downloader最大并发请求下载数量,默认32CONCURRENT_ITEMS:Item Pipeline最大并发ITEM处理数量,默认100CONCURRENT_REQUESTS_PER_DOMAIN: 每个目标域名最大的并发请求数量,默认8CONCURRENT_REQUESTS_PER_IP: 每个目标IP最大的并发请求数量,默认0,非0有效
- 配置
执行:
scrapy crawl <spiderName>
Demo
创建项目
$ scrapy startproject douban_demo New Scrapy project 'douban_demo', using template directory '/usr/local/lib/python3.7/site-packages/scrapy/templates/project', created in: /Users/cj/space/python/douban_demo You can start your first spider with: cd douban_demo scrapy genspider example example.com查看项目目录
$ tree . ├── douban_demo │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-37.pyc │ │ └── settings.cpython-37.pyc │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ ├── __init__.py │ ├── __pycache__ │ └── __init__.cpython-37.pyc └── scrapy.cfg 4 directories, 10 files- 查看自动创建的
pipelines.py# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class DoubanDemoPipeline(object): def process_item(self, item, spider): return item - 查看自动创建的
items.py# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class DoubanDemoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass 查看自动生成的
settings.py# -*- coding: utf-8 -*- # Scrapy settings for douban_demo project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'douban_demo' SPIDER_MODULES = ['douban_demo.spiders'] NEWSPIDER_MODULE = 'douban_demo.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'douban_demo (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # ...
创建Spider
# 进入项目目录,创建一个Spider $ cd douban_demo/ $ scrapy genspider movie movie.douban.com Created spider 'movie' using template 'basic' in module: douban_demo.spiders.movie查看新建的spider:
spider/movie.py# -*- coding: utf-8 -*- import scrapy class MovieSpider(scrapy.Spider): name = 'movie' allowed_domains = ['movie.douban.com'] start_urls = ['http://movie.douban.com/'] def parse(self, response): pass编写spider:
spider/movie.py# -*- coding: utf-8 -*- import scrapy import re import json from douban_demo.items import MovieItem class MovieSpider(scrapy.Spider): name = 'movie' allowed_domains = ['movie.douban.com'] start_urls = ['https://movie.douban.com/j/search_subjects?type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0'] def parse(self, response): print(response.url) result=json.loads(response.body) subjects=result.get('subjects') if len(subjects)>0: for subject in subjects: # print(subject) yield MovieItem(subject)- items.py
# -*- coding: utf-8 -*- import scrapy class MovieItem(scrapy.Item): # {'rate': '7.0', 'cover_x': 7142, 'title': '飞驰人生', 'url': 'https://movie.douban.com/subject/30163509/', 'playable': True, 'cover': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2542973862.jpg', 'id': '30163509', 'cover_y': 10000, 'is_new': False} rate=scrapy.Field() title=scrapy.Field() url=scrapy.Field() id=scrapy.Field() is_new=scrapy.Field()
编写pipeline.py(optional)
from scrapy.conf import settings class MoviePipeline(object): def process_item(self, item, spider): print(item) return item配置
setting.pyUSER_AGENT='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0' LOG_LEVEL = 'INFO' FEED_EXPORT_ENCODING='utf-8' # Obey robots.txt rules ROBOTSTXT_OBEY = False ITEM_PIPELINES = { 'douban_demo.pipelines.MoviePipeline':100 }运行Spider
$ scrapy crawl movie $ scrapy crawl movie -o movies.json -s FEED_EXPORT_ENCODING=utf-8 -L INFO
架构
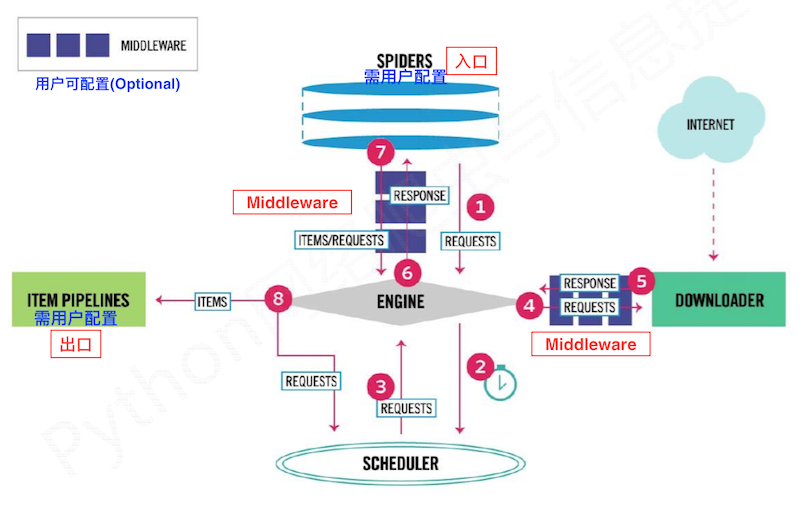
“5+2”结构
引擎
Engine:- 控制所有模块之间的数据流,根据条件触发事件
下载器
Downloader:- 根据请求下载网页
调度器
Scheduler:- 对所有爬取请求进行调度管理
爬虫
Spider(需要用户编写配置代码):- 解析
Downloader返回的响应Response - 产生爬取项
Scraped item - 产生额外的爬取请求
Request
- 解析
管道
Item Pipelines(需要用户编写配置代码):- 以流水线方式处理
Spider产生的爬取项Scraped item - 由一组操作顺序组成,类似流水线,每个操作是一个
Item Pipeline类型 - 可能操作包括: 清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
- 以流水线方式处理
中间件 (用户可以编写配置代码):
- 下载中间件
Downloader Middleware: 修改、丢弃、新增请求Request或响应Response - 爬虫中间件
Spider Middleware: 修改、丢弃、新增Request或爬取项Scraped item
- 下载中间件
出入口
框架入口:
Spider的初始爬取请求
框架出口:
Item Pipeline
数据流:
Engine控制各模块数据流,不间断从Scheduler处获得爬取Request,直至Request为空
用户编写:
Spider:处理链接爬取和页面解析Item Pipelines:处理信息存储Middleware:Spider Middleware: 过滤new requests&Scraped ItemDownloader Middleware: 过滤request&response
Setting:配置
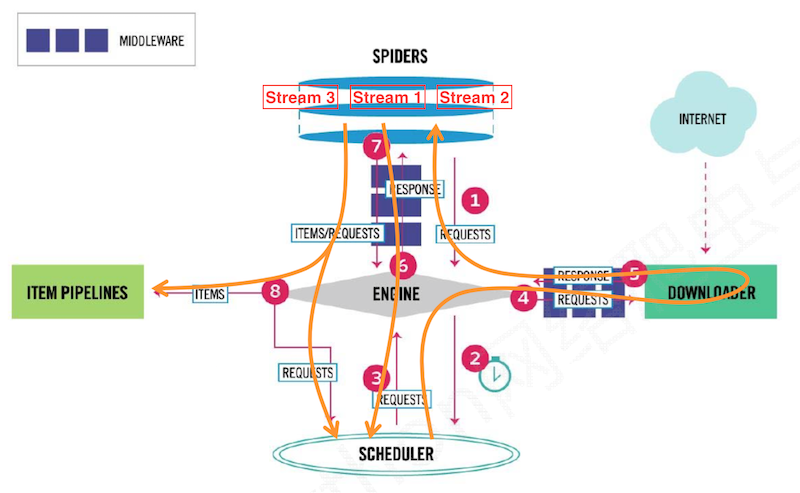
流程(数据流的三个路径)
- UR2IM 流程
URL -> Request -> Response -> Item -> More URL ^ |-> store | |__________________________________| - 路径1:
- Spider =>
request=> Engine =>request=> Schedule (Engine从Spider处获得爬取Request,然后将Request转发给Scheduler,用于调度)
- Spider =>
- 路径2:
- Schedule =>
request=> Engine =>request=> Downloader Middleware => Downloader (Engine从Scheduler处获得下一个要爬取的Request,通过Downloader Middleware后发给Downloader) - Downloader =>
response=> Downloader Middleware => Engine => Spider Middleware => Spider (爬取网页后Downloader形成响应Response, 通过Downloader Middleware后发回Engine,Engine将收到的响应通过Spider Middleware发送给Spider处理)
- Schedule =>
- 路径3:
- Spider =>
Scraped Item&New Requests=> Engine (Spider处理响应后产生爬取项Scraped Item和新的爬取请求Requests给Engine) - Engine =>
Scraped Item=> Item Pipeline (Engine将爬取项Scraped Item发送给框架出口Item Pipeline) - Engine =>
New Requests=> Scheduler (Engine将爬取Request发送给Scheduler)
- Spider =>
常用命令
Scrapy采用命令行创建和运行爬虫
命令行格式:scrapy <command> [options] [args]
Scrapy 命令:
$ scrapy -h Scrapy 1.6.0 - project: douban Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test check Check spider contracts crawl Run a spider edit Edit spider fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates list List available spiders parse Parse URL (using its spider) and print the results runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy Use "scrapy <command> -h" to see more info about a command常用命令说明:
命令 说明 scrapy startproject <name> [dir]创建一个新工程 scrapy genspider [options] <name> <domain>创建一个爬虫 scrapy list列出工程中所有爬虫 scrapy crawl <spider>运行一个爬虫 scrapy settings [options]获得爬虫配置信息 scrapy shell [url]启动URL调试命令行 Global Options:
Global Options -------------- ---logfile=FILE log file. if omitted stderr will be used --loglevel=LEVEL, -L LEVEL log level (default: DEBUG) --nolog disable logging completely --profile=FILE write python cProfile stats to FILE --pidfile=FILE write process ID to FILE --set=NAME=VALUE, -s NAME=VALUE set/override setting (may be repeated) --pdb enable pdb on failure
Generate a spider options:
$ scrapy genspider -h Usage ===== scrapy genspider [options] <name> <domain> Generate new spider using pre-defined templates Options ======= --help, -h show this help message and exit --list, -l List available templates --edit, -e Edit spider after creating it --dump=TEMPLATE, -d TEMPLATE Dump template to standard output --template=TEMPLATE, -t TEMPLATE Uses a custom template. --force If the spider already exists, overwrite it with the templateRun a spider options:
Usage ===== scrapy crawl [options] <spider> Run a spider Options ======= --help, -h show this help message and exit -a NAME=VALUE set spider argument (may be repeated) --output=FILE, -o FILE dump scraped items into FILE (use - for stdout) --output-format=FORMAT, -t FORMAT format to use for dumping items with -oSet spider settings:
Usage ===== scrapy settings [options] Get settings values Options ======= --help, -h show this help message and exit --get=SETTING print raw setting value --getbool=SETTING print setting value, interpreted as a boolean --getint=SETTING print setting value, interpreted as an integer --getfloat=SETTING print setting value, interpreted as a float --getlist=SETTING print setting value, interpreted as a list
示例:使用 scrapy shell 交互式调试
$ scrapy shell
...
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x105cd57f0>
[s] item {}
[s] settings <scrapy.settings.Settings object at 0x105cd58d0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>>
>>> exit()
$ scrapy shell https://movie.douban.com/top250
...
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x1037be908>
[s] item {}
[s] request <GET https://movie.douban.com/top250>
[s] response <200 https://movie.douban.com/top250>
[s] settings <scrapy.settings.Settings object at 0x1037be9e8>
[s] spider <Top250Spider 'top250' at 0x103bb2048>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>> records=response.xpath('//ol[@class="grid_view"]//div[@class="item"]/div[@class="info"]')
>>> len(records)
25
>>> records.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num
"]/text()').extract()
['9.6', '9.6', '9.4', '9.4', '9.5', '9.4', '9.3', '9.5', '9.3', '9.3', '9.3', '9.2', '9.2', '9.3', '9.2', '9.2', '9.2', '9.2', '9.3', '9.3', '9.2', '9.2', '9.0', '9.0', '9.2']
>>> records[0].xpath('./div[@class="hd"]/a/span[@class="title"]/text()')
[<Selector xpath='./div[@class="hd"]/a/span[@class="title"]/text()' data='肖申克'>, <Selector xpath='./div[@class="hd"]/a/span[@class="title"]/text()' data='\xa0/\xa0The Shawshank Redemption'>]
>>> records[0].xpath('./div[@class="hd"]/a/span[@class="title"]/text()').extract()
['肖申克的救赎', '\xa0/\xa0The Shawshank Redemption']
>>> records[0].xpath('./div[@class="hd"]/a/span[@class="title"]/text()').get()
'肖申克的救赎'
>>> records[0].xpath('./div[@class="hd"]/a/span[@class="title"]/text()').extract_first()
'肖申克的救赎'
>>>records[0].xpath('./div[@class="hd"]/a/span[@class="title"]/text()').re('[A-Za-z ]+')
['The Shawshank Redemption']
>>> records=response.css('.grid_view .item .info')
>>> len(records)
25
# >>> records.css('.bd .star .rating_num').xpath('text()').extract()
# >>> records.css('.bd .star .rating_num::text').extract()
# >>> records.css('.bd .star .rating_num').re('[\d.]+')
>>> records.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()
['9.6', '9.6', '9.4', '9.4', '9.5', '9.4', '9.3', '9.5', '9.3', '9.3', '9.3', '9.2', '9.2', '9.3', '9.2', '9.2', '9.2', '9.2', '9.3', '9.3', '9.2', '9.2', '9.0', '9.0', '9.2']
>>> len(response.css('div'))
183
>>> len(records.css('div'))
100
>>> exit()
解析文档
- 可使用BeautifulSoup,lxml解析,而Scrapy内部使用的是lxml(效率更高),可使用Xpath,CssSelector进行文档定位解析
response.xpath()和response.css()返回的Selector对象列表SelectorList是可以被串联起来的- 获取
Selector对象/SelectorList中的data,可以使用.extract/getall(),.extract_first/get(),.re(pattern) - 获取
Selector对象/SelectorList中标签的某个属性值,可以使用.attrib['attrName'] - xpath可使用
/@attrName获取属性值,eg:response.xpath(//div[@class="item"]//img/@src) - css selector 可使用伪代码
::,eg:- select text nodes, use
::text - select attribute values, use
::attr(attrName) - eg:
response.css('title::text').get(default=''),response.css('a::attr(href)').getall()
- select text nodes, use
- Selector 文档
Settings 优先级
SETTINGS_PRIORITIES = {
'default': 0,
'command': 10,
'project': 20,
'spider': 30,
'cmdline': 40,
}
- default:
scrapy/settings/default_settings.py - project:
[project]/settings.py - spider: Spider中配置的
custom_settings属性 - cmdline: 命令行运行时传入的
-s xxxx=xxx参数
$ scrapy settings --get CONCURRENT_REQUESTS
16
$ scrapy settings -s CONCURRENT_REQUESTS=19 --get CONCURRENT_REQUESTS
19
$ scrapy crawl movie -s CONCURRENT_REQUESTS=19
$ scrapy shell -s CONCURRENT_REQUESTS=19
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x105cd57f0>
[s] item {}
[s] settings <scrapy.settings.Settings object at 0x105cd58d0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>> settings.get('CONCURRENT_REQUESTS')
'19'
>>> settings.getint('CONCURRENT_REQUESTS')
19
>>> exit()
Default Settings
项目
BOT_NAME = 'scrapybot' # eg: 'douban' SPIDER_MODULES = [] # eg: ['douban.spiders'] NEWSPIDER_MODULE = '' # eg: 'douban.spiders' TEMPLATES_DIR = abspath(join(dirname(__file__), '..', 'templates')) DEFAULT_ITEM_CLASS = 'scrapy.item.Item' EDITOR = 'vi' if sys.platform == 'win32': EDITOR = '%s -m idlelib.idle' # mail MAIL_HOST = 'localhost' MAIL_PORT = 25 MAIL_FROM = 'scrapy@localhost' MAIL_PASS = None MAIL_USER = None分析
# 日志 Log : LOG_ENABLED = True LOG_ENCODING = 'utf-8' LOG_FORMATTER = 'scrapy.logformatter.LogFormatter' LOG_FORMAT = '%(asctime)s [%(name)s] %(levelname)s: %(message)s' LOG_DATEFORMAT = '%Y-%m-%d %H:%M:%S' LOG_STDOUT = False LOG_LEVEL = 'DEBUG' LOG_FILE = None LOG_SHORT_NAMES = False LOGSTATS_INTERVAL = 60.0 # 统计 Stats : STATS_CLASS = 'scrapy.statscollectors.MemoryStatsCollector' STATS_DUMP = True STATSMAILER_RCPTS = [] DEPTH_STATS_VERBOSE = False DOWNLOADER_STATS = True # Telnet: TELNETCONSOLE_ENABLED = 1 TELNETCONSOLE_PORT = [6023, 6073] TELNETCONSOLE_HOST = '127.0.0.1' TELNETCONSOLE_USERNAME = 'scrapy' TELNETCONSOLE_PASSWORD = None爬取策略
# Cookie COOKIES_ENABLED = True COOKIES_DEBUG = False # Request DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } # User-Agent USER_AGENT = 'Scrapy/%s (+https://scrapy.org)' % import_module('scrapy').__version__ # robots.txt ROBOTSTXT_OBEY = False # 代理 HTTPPROXY_ENABLED = True HTTPPROXY_AUTH_ENCODING = 'latin-1' # referer REFERER_ENABLED = True REFERRER_POLICY = 'scrapy.spidermiddlewares.referer.DefaultReferrerPolicy' # rediret REDIRECT_ENABLED = True REDIRECT_MAX_TIMES = 20 # uses Firefox default setting REDIRECT_PRIORITY_ADJUST = +2 # retry RETRY_ENABLED = True RETRY_TIMES = 2 # initial response + 2 retries = 3 requests RETRY_HTTP_CODES = [500, 502, 503, 504, 522, 524, 408] RETRY_PRIORITY_ADJUST = -1 # meta refresh METAREFRESH_ENABLED = True METAREFRESH_MAXDELAY = 100 # DNS DNSCACHE_ENABLED = True DNSCACHE_SIZE = 10000 DNS_TIMEOUT = 60 # Http缓存 HTTPCACHE_ENABLED = False HTTPCACHE_DIR = 'httpcache' HTTPCACHE_IGNORE_MISSING = False HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' HTTPCACHE_EXPIRATION_SECS = 0 HTTPCACHE_ALWAYS_STORE = False HTTPCACHE_IGNORE_HTTP_CODES = [] HTTPCACHE_IGNORE_SCHEMES = ['file'] HTTPCACHE_IGNORE_RESPONSE_CACHE_CONTROLS = [] HTTPCACHE_DBM_MODULE = 'anydbm' if six.PY2 else 'dbm' HTTPCACHE_POLICY = 'scrapy.extensions.httpcache.DummyPolicy' HTTPCACHE_GZIP = False # 并发 CONCURRENT_ITEMS = 100 CONCURRENT_REQUESTS = 16 CONCURRENT_REQUESTS_PER_DOMAIN = 8 CONCURRENT_REQUESTS_PER_IP = 0 REACTOR_THREADPOOL_MAXSIZE = 10 # Depth DEPTH_LIMIT = 0 DEPTH_STATS_VERBOSE = False DEPTH_PRIORITY = 0 # 结束爬取 CLOSESPIDER_TIMEOUT = 0 CLOSESPIDER_PAGECOUNT = 0 CLOSESPIDER_ITEMCOUNT = 0 CLOSESPIDER_ERRORCOUNT = 0 # 自动限速 AUTOTHROTTLE_ENABLED = False AUTOTHROTTLE_DEBUG = False AUTOTHROTTLE_MAX_DELAY = 60.0 AUTOTHROTTLE_START_DELAY = 5.0 AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Memory MEMDEBUG_ENABLED = False # enable memory debugging MEMDEBUG_NOTIFY = [] # send memory debugging report by mail at engine shutdown MEMUSAGE_CHECK_INTERVAL_SECONDS = 60.0 MEMUSAGE_ENABLED = True MEMUSAGE_LIMIT_MB = 0 MEMUSAGE_NOTIFY_MAIL = [] MEMUSAGE_WARNING_MB = 0 # other AJAXCRAWL_ENABLED = False COMPRESSION_ENABLED = True组件
# 1. Scheduler SCHEDULER = 'scrapy.core.scheduler.Scheduler' SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleLifoDiskQueue' SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.LifoMemoryQueue' SCHEDULER_PRIORITY_QUEUE = 'queuelib.PriorityQueue' SCHEDULER_DEBUG = False # 2. Downloader DOWNLOADER = 'scrapy.core.downloader.Downloader' DOWNLOADER_HTTPCLIENTFACTORY = 'scrapy.core.downloader.webclient.ScrapyHTTPClientFactory' DOWNLOADER_CLIENTCONTEXTFACTORY = 'scrapy.core.downloader.contextfactory.ScrapyClientContextFactory' DOWNLOADER_CLIENT_TLS_METHOD = 'TLS' # Use highest TLS/SSL protocol version supported by the platform, # also allowing negotiation DOWNLOADER_STATS = True RANDOMIZE_DOWNLOAD_DELAY = True DOWNLOAD_DELAY = 0 DOWNLOAD_HANDLERS = {} DOWNLOAD_HANDLERS_BASE = { 'data': 'scrapy.core.downloader.handlers.datauri.DataURIDownloadHandler', 'file': 'scrapy.core.downloader.handlers.file.FileDownloadHandler', 'http': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler', 'https': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler', 's3': 'scrapy.core.downloader.handlers.s3.S3DownloadHandler', 'ftp': 'scrapy.core.downloader.handlers.ftp.FTPDownloadHandler', } DOWNLOAD_TIMEOUT = 180 # 3mins DOWNLOAD_MAXSIZE = 1024*1024*1024 # 1024m DOWNLOAD_WARNSIZE = 32*1024*1024 # 32m DOWNLOAD_FAIL_ON_DATALOSS = True # 3. Item Pipeline ITEM_PROCESSOR = 'scrapy.pipelines.ItemPipelineManager' ITEM_PIPELINES = {} ITEM_PIPELINES_BASE = {} # 4. Spider Middleware SPIDER_MIDDLEWARES = {} SPIDER_MIDDLEWARES_BASE = { # Engine side 'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50, 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500, 'scrapy.spidermiddlewares.referer.RefererMiddleware': 700, 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800, 'scrapy.spidermiddlewares.depth.DepthMiddleware': 900, # Spider side } # 5. Downloader Middleware DOWNLOADER_MIDDLEWARES = {} DOWNLOADER_MIDDLEWARES_BASE = { # Engine side 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300, 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350, 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400, 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500, 'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550, 'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560, 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590, 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600, 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700, 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750, 'scrapy.downloadermiddlewares.stats.DownloaderStats': 850, 'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900, # Downloader side } # 6. Extension Middleware EXTENSIONS = {} EXTENSIONS_BASE = { 'scrapy.extensions.corestats.CoreStats': 0, 'scrapy.extensions.telnet.TelnetConsole': 0, 'scrapy.extensions.memusage.MemoryUsage': 0, 'scrapy.extensions.memdebug.MemoryDebugger': 0, 'scrapy.extensions.closespider.CloseSpider': 0, 'scrapy.extensions.feedexport.FeedExporter': 0, 'scrapy.extensions.logstats.LogStats': 0, 'scrapy.extensions.spiderstate.SpiderState': 0, 'scrapy.extensions.throttle.AutoThrottle': 0, }Output
# Feeds & Exporter: FEED_TEMPDIR = None FEED_URI = None FEED_URI_PARAMS = None # a function to extend uri arguments FEED_FORMAT = 'jsonlines' FEED_STORE_EMPTY = False FEED_EXPORT_ENCODING = None FEED_EXPORT_FIELDS = None FEED_STORAGES = {} FEED_STORAGES_BASE = { '': 'scrapy.extensions.feedexport.FileFeedStorage', 'file': 'scrapy.extensions.feedexport.FileFeedStorage', 'stdout': 'scrapy.extensions.feedexport.StdoutFeedStorage', 's3': 'scrapy.extensions.feedexport.S3FeedStorage', 'ftp': 'scrapy.extensions.feedexport.FTPFeedStorage', } FEED_EXPORTERS = {} FEED_EXPORTERS_BASE = { 'json': 'scrapy.exporters.JsonItemExporter', 'jsonlines': 'scrapy.exporters.JsonLinesItemExporter', 'jl': 'scrapy.exporters.JsonLinesItemExporter', 'csv': 'scrapy.exporters.CsvItemExporter', 'xml': 'scrapy.exporters.XmlItemExporter', 'marshal': 'scrapy.exporters.MarshalItemExporter', 'pickle': 'scrapy.exporters.PickleItemExporter', } FEED_EXPORT_INDENT = 0 # file s3/gcs store FILES_STORE_S3_ACL = 'private' FILES_STORE_GCS_ACL = '' # image s3/gsc store IMAGES_STORE_S3_ACL = 'private' IMAGES_STORE_GCS_ACL = '' # ftp FTP_USER = 'anonymous' FTP_PASSWORD = 'guest' FTP_PASSIVE_MODE = True
数据类型
Requestclass scrapy.http.Request()- 表示一个HTTP请求,由
Spider生成,Downloader执行 - 属性:
.url: Request对应的请求URL地址.method: 对应的请求方法,'GET' 'POST'等.headers: 字典类型风格的请求头.body: 请求内容主体,字符串类型.meta: 用户添加的扩展信息,在Scrapy内部模块间传递信息使用.encoding.dont_filter: 默认为False(表示要过滤掉重复Request)
- 方法:
.copy().replace()
- 子类:
FormRequestfrom_response()
XmlRpcRequest
Responseclass scrapy.http.Response()- 表示一个HTTP响应,由
Downloader生成,Spider处理 - 属性:
.url: Response对应的URL地址.status: HTTP状态码,默认是200.headers: Response对应的头部信息.body: Response对应的内容信息,字符串类型.flags: 一组标记.request: 产生Response类型对应的Request对象.meta.text
- 方法:
.copy().replace().urljoin().xpath().css().follow()
- 子类:
TextResponse.encoding- 子类:
XmlResponse,HtmlResponse
Itemclass scrapy.item.Item()- 表示一个从HTML页面中提取的信息内容,由
Spider生成,Item Pipeline处理 - 似字典类型,可按照字典类型操作
Spider
Refer Scrapy Spider
创建运行Spider
创建Spider:
scrapy genspider <-t [template:default is basic]> [spiderName] [domain]- 查看有效Spider template:
scrapy genspider --list$ scrapy genspider --list Available templates: basic crawl csvfeed xmlfeed - eg: 创建基础Spider
$ scrapy genspider movie movie.douban.com Created spider 'movie' using template 'basic' in module: douban_demo.spiders.movie - eg: 创建CrawlSpider:
$ scrapy genspider -t crawl top250 movie.douban.com Created spider 'top250' using template 'crawl' in module: douban_demo.spiders.top250
- 查看有效Spider template:
运行Spider:
scrapy crawl [spiderName] < -a [argName]=[argValue] > < -o [File]> <-t [Format] >-a [argName=argValue]: passed arguments to spider,Spiders can access arguments in their__init__methods-o [File]: dump scraped items into FILE,recognize file extension as format,also could use-t [Format]set output formateg:
$ scrapy crawl movie # 传参给spider,spider中初始化函数中添加参数: # def __init__(self, category=None, *args, **kwargs) $ scrapy crawl movie -a category=top # 输出到文件,根据文件后缀名,以对应格式输出 $ scrapy crawl movie -o movies.json # [{},{},...] $ scrapy crawl movie -o movies.jl # {},{},... => recommend ! $ scrapy crawl movie -o movies.csv # xxx,xxx,xxx,... # -s,-L same as set in setting.py: FEED_EXPORT_ENCODING='utf-8', LOG_LEVEL = 'INFO' $ scrapy crawl movie -o movies.json -s FEED_EXPORT_ENCODING=utf-8 -L INFO # -s CLOSESPIDER_ITEMCOUNT 控制最多爬取10个Item $ scrapy crawl movie -o movies.json -s CLOSESPIDER_ITEMCOUNT=10 # use - for stdout $ scrapy crawl movie -t json -o -> movies.json
基类:Spider
Sample1: 自动生成的basic spider (scrapy genspider movie movie.douban.com)
# -*- coding: utf-8 -*-
import scrapy
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/']
def parse(self, response):
pass
Sample2: 使用start_urls/start_requests() & parse(response) => self.logger/log, yield Item,Request
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
]
#def start_requests(self):
# yield scrapy.Request('http://www.example.com/1.html', self.parse)
# yield scrapy.Request('http://www.example.com/2.html', self.parse)
# yield scrapy.Request('http://www.example.com/3.html', self.parse)
def parse(self, response):
self.logger.info('A response from %s just arrived!', response.url)
# or self.log('....')
for h3 in response.xpath('//h3').getall():
yield {"title": h3}
for href in response.xpath('//a/@href').getall():
yield scrapy.Request(response.urljoin(href), self.parse)
Note:
- 属性:
- name
- allowed_domains
- start_urls
- custom_settings
- crawler
- settings
- logger
- 方法:
- init(self, name=None, **kwargs)
- from_crawler(cls, crawler, _args, *_kwargs)
- start_requests(self)
- parse(self,response)
- log(self, message, level=logging.DEBUG, **kw])
- closed(self,reason)
- Key:
nameallowed_domainscustom_settingsstart_urls=[]/start_requests(self)=> yield Request (Note: 这里产生的Request的dont_filter=True)parse(self,response)=> yield Item,yield Requestclosed(self,reason)=> Called when the spider closes(for thespider_closedsignal)
子类:CrawlSpider
Sample1:自动生成的crawl spider (scrapy genspider -t crawl top250 movie.douban.com)
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Top250Spider(CrawlSpider):
name = 'top250'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
Sample2:rules=(...) & self def callback parse_item(self,response)
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from douban_demo.items import Top250Item
class Top250Spider(CrawlSpider):
name = 'top250'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
rules = (
Rule(
LinkExtractor(allow=r'\?start=\d+.*',restrict_xpaths='//div[@class="paginator"]')
, callback='parse_item', follow=True),
)
def parse_item(self, response):
print(response.url)
records=response.xpath('//ol[@class="grid_view"]//div[@class="item"]/div[@class="info"]')
for r in records:
item=Top250Item()
link=r.xpath('./div[@class="hd"]/a/@href').get()
item['id']=link.split('/')[-2]
item['title']=r.xpath('./div[@class="hd"]/a/span[@class="title"]/text()').extract_first()
item['rate']=r.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract_first()
item['quote']=r.xpath('./div[@class="bd"]/p[@class="quote"]/span/text()').extract_first()
yield item
Note:
- 属性:
- rules=()
Rule(...): defines a certain behaviour for crawling the site (内部通过request.meta的rule传递)link_extractor:scrapy.linkextractors.LinkExtractordefines how links will be extracted from each crawled pagecallback=None: callable,handle response => yield Item,yield Requestcb_kwargs=None: dict, passed args to the callback functionfollow=None: True/False, if still extract the response with this rule (callback:None => default follow:True; els default follow:False)process_links=None: callable,used for filtering extract links.process_request=None: callable,used for filtering extract requests.
LinkExtractor(...): used for extracting links from response- allow=()
- deny=()
- allow_domains=()
- deny_domains=()
- deny_extensions=None
- restrict_xpaths=()
- restrict_css=()
- tags=('a', 'area')
- attrs=('href', )
- canonicalize=False
- unique=True
- process_value=None
- strip=True
- rules=()
- 方法:
parse_start_url(self, response): call for start_urls responses => yieldItem/Requestprocess_results(self, response, results):call for parse_start_url results => yieldItem/Request
- Key:
start_urls=[]/start_requests(self)=> yield Request- for start requests responses:
parse_start_url(self,response),process_results(self,respons,results)=> yieldItem/Request - after start requests follow the rules:
rules=(Rule(LinkExtractor(...),callback='parse_item',follow=True),...)=> yieldRequest - def callback func(note:avoid using
parseas callback):parse_item(self,response)=> yieldItem/Request
Sample: LinkExtractor
$ scrapy shell https://movie.douban.com/top250/
...
>>> from scrapy.linkextractors import LinkExtractor
>>> le=LinkExtractor(allow=r'\?start=\d+.*',restrict_xpaths='//div[@class="paginator"]')
>>> le.extract_links(response)
[Link(url='https://movie.douban.com/top250?start=25&filter=', text='2', fragment='', nofollow=False),
Link(url='https://movie.douban.com/top250?start=50&filter=', text='3', fragment='', nofollow=False),
Link(url='https://movie.douban.com/top250?start=75&filter=', text='4', fragment='', nofollow=False),
Link(url='https://movie.douban.com/top250?start=100&filter=', text='5', fragment='', nofollow=False),
Link(url='https://movie.douban.com/top250?start=125&filter=', text='6', fragment='', nofollow=False),
Link(url='https://movie.douban.com/top250?start=150&filter=', text='7', fragment='', nofollow=False),
Link(url='https://movie.douban.com/top250?start=175&filter=', text='8', fragment='', nofollow=False),
Link(url='https://movie.douban.com/top250?start=200&filter=', text='9', fragment='', nofollow=False),
Link(url='https://movie.douban.com/top250?start=225&filter=', text='10', fragment='', nofollow=False)]
>>> le.allow_res
[re.compile('\\?start=\\d+.*')]
>>> le.restrict_xpaths
('//div[@class="paginator"]',)
子类:XMLFeedSpider
Sample1:
from scrapy.spiders import XMLFeedSpider
from myproject.items import TestItem
class MySpider(XMLFeedSpider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com/feed.xml']
iterator = 'iternodes' # This is actually unnecessary, since it's the default value
itertag = 'item' # change it accordingly
def parse_node(self, response, node):
self.logger.info('Hi, this is a <%s> node!: %s', self.itertag, ''.join(node.getall()))
item = TestItem()
item['id'] = node.xpath('@id').get()
item['name'] = node.xpath('name').get()
item['description'] = node.xpath('description').get()
return item
Sample2: 用xmlfeed爬取新浪博客的订阅信息(scrapy genspider -crawl xmlfeed sinaRss sina.com.cn)
<rss xmlns:sns="http://blog.sina.com.cn/sns" version="2.0">
<channel>
<title>科幻星系</title>
<description/>
<link>http://blog.sina.com.cn/sfw</link>
<item>
<title>手机进化凶猛背后的“凄凉”电池何时才能飞奔起来?</title>
<link>http://blog.sina.com.cn/s/blog_4a46c3960102zgcw.html</link>
<description>...</description>
</item>
<item>
<title>中国5G,如何避免重复投资?</title>
<link>http://blog.sina.com.cn/s/blog_4a46c3960102zgcb.html</link>
<description>...</description>
</item>
<item>
<title>与英特尔分道扬镳,苹果的5G业务掉队了吗??</title>
<link>http://blog.sina.com.cn/s/blog_4a46c3960102zgbj.html</link>
<description>...</description>
</item>
</channel>
</rss>
# -*- coding: utf-8 -*-
from scrapy.spiders import XMLFeedSpider
class SinaRssSpider(XMLFeedSpider):
name = 'sinaRss'
allowed_domains = ['sina.com.cn']
start_urls = ['http://blog.sina.com.cn/rss/1246151574.xml']
iterator = 'iternodes' # This is actually unnecessary, since it's the default value
itertag = 'item' # change it accordingly
def parse_node(self, response, selector):
item = {}
item['title'] = selector.xpath('title/text()').get()
item['link'] = selector.xpath('link/text()').get()
return item
使用 scrapy parse 查看:
$ scrapy parse --spider=sinaRss http://blog.sina.com.cn/rss/1246151574.xml
...
>>> STATUS DEPTH LEVEL 1 <<<
# Scraped Items ------------------------------------------------------------
[{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zgcw.html',
'title': '手机进化凶猛背后的“凄凉”电池何时才能飞奔起来?'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zgcb.html',
'title': '中国5G,如何避免重复投资?'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zgbj.html',
'title': '与英特尔分道扬镳,苹果的5G业务掉队了吗?'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zga4.html',
'title': '为什么越来越多的知名品牌热衷打造快闪店?'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zg9a.html',
'title': '电商专供还是电商专坑,背后的这些猫腻你知道多少?'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zg8n.html',
'title': '八年坎坷崎岖路:安卓平板为何终究是扶不起的“阿斗”'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zg87.html',
'title': '火爆的直播能让电视购物焕发第二春吗?'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zg7f.html',
'title': '各大厂商发力5G新机,未来全球手机市场或将呈现新格局'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zg6r.html',
'title': '研发2nm芯片,台积电如何做到天下第一?'},
{'link': 'http://blog.sina.com.cn/s/blog_4a46c3960102zg6j.html',
'title': '芬兰采购中国无人机,值得骄傲吗?'}]
# Requests -----------------------------------------------------------------
[]
Note:
- 属性:
iterator = 'iternodes'- 'iternodes'(default): a fast iterator based on regular expressions
- 'html': an iterator which uses Selector (load all DOM in memory)
- 'xml': an iterator which uses Selector (load all DOM in memory)
itertag = 'item': the name of the node (or element) to iterate innamespaces = (): A list of(prefix, uri)tuples
- 方法:
parse(self, response)- call
adapt_response(self, response): returnresponse - call
parse_nodes(self, response, nodes)=> yieldItem/Request- call
parse_node(self, response, selector): returnItem/Request - call
process_results(self, response, results): filterItem/Request
- call
- call
- Key:
- pre:
adapt_response(self, response) - process item:
parse_node(self, response, selector) - post:
process_results(self, response, results)
- pre:
子类:CSVFeedSpider
Sample:
from scrapy.spiders import CSVFeedSpider
from myproject.items import TestItem
class MySpider(CSVFeedSpider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com/feed.csv']
delimiter = ';'
quotechar = "'"
headers = ['id', 'name', 'description']
def parse_row(self, response, row):
self.logger.info('Hi, this is a row!: %r', row)
item = TestItem()
item['id'] = row['id']
item['name'] = row['name']
item['description'] = row['description']
return item
Note:
- 属性:
delimiter: separator character for each field, default is,quotechar: enclosure character for each field,default is"headers: A list of the column names in the CSV file
- 方法:
parse(self, response)- call
adapt_response(self, response): returnresponse - call
parse_rows(self, response)=> yieldItem/Request- call
parse_row(self, response, row): returnItem/Request - call
process_results(self, response, results): filterItem/Request
- call
- call
- Key:
- pre:
adapt_response(self, response) - process item:
parse_node(self, response, row) - post:
process_results(self, response, results)
- pre:
子类:SitemapSpider
Sample1:
from scrapy.spiders import SitemapSpider
class MySpider(SitemapSpider):
sitemap_urls = ['http://www.example.com/robots.txt']
sitemap_rules = [
('/shop/', 'parse_shop'),
]
sitemap_follow = ['/sitemap_shops']
def sitemap_filter(self, entries):
for entry in entries:
date_time = datetime.strptime(entry['lastmod'], '%Y-%m-%d')
if date_time.year >= 2005:
yield entry
def parse_shop(self, response):
pass # ... scrape shop here ...
Sample2: 马蜂窝 sitemapindex
View
http://www.mafengwo.cn/sitemapIndex.xml:<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <sitemap> <loc>http://www.mafengwo.cn/article-0.xml</loc> <lastmod>2019-03-15</lastmod> </sitemap> <sitemap> <loc>http://www.mafengwo.cn/article-1.xml</loc> <lastmod>2019-03-15</lastmod> </sitemap> <sitemap> <loc>http://www.mafengwo.cn/article-2.xml</loc> <lastmod>2019-03-15</lastmod> </sitemap> <sitemap> <loc>http://www.mafengwo.cn/articleList-0.xml</loc> <lastmod>2019-03-15</lastmod> </sitemap> <sitemap> <loc>http://www.mafengwo.cn/shop-0.xml</loc> <lastmod>2019-03-15</lastmod> </sitemap> </sitemapindex>View
http://www.mafengwo.cn/shop-0.xml:<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url> <loc>http://www.mafengwo.cn/v100029</loc> <lastmod>2019-07-03 02:51:02</lastmod> <changefreq>weekly</changefreq> <priority>0.7</priority> </url> <url> <loc>http://www.mafengwo.cn/v100027</loc> <lastmod>2019-07-03 02:51:02</lastmod> <changefreq>weekly</changefreq> <priority>0.7</priority> </url> <url> <loc>http://www.mafengwo.cn/shop/mdd.php?mddid=10186</loc> <lastmod>2019-07-03 02:51:02</lastmod> <changefreq>weekly</changefreq> <priority>0.7</priority> </url> <url> <loc>http://www.mafengwo.cn/shop/mdd.php?mddid=10030</loc> <lastmod>2019-07-03 02:51:02</lastmod> <changefreq>weekly</changefreq> <priority>0.7</priority> </url> </urlset>Create Spider:
scrapy genspider siteUpdate mafengwo.cn# -*- coding: utf-8 -*- from scrapy.spiders import SitemapSpider class SiteUpdateSpider(SitemapSpider): name = 'siteUpdate' allowed_domains = ['mafengwo.cn'] sitemap_urls=['http://www.mafengwo.cn/sitemapIndex.xml'] sitemap_rules=[ (r'/v\d+','parse_shop') # for parse web page(eg:html) ] sitemap_follow=[r'/shop-\d+.xml'] # for scrapy deep sitemap loc def sitemap_filter(self, entries): for entry in entries: # 1. entry: sitemap object( # <sitemap> # <loc>http://www.mafengwo.cn/shop-0.xml</loc> # <lastmod>2019-07-03</lastmod> # </sitemap> # ) # 2. entry: url object( # <url> # <loc>http://www.mafengwo.cn/v100292</loc> # <lastmod>2019-07-03 02:51:02</lastmod> # <changefreq>weekly</changefreq> # <priority>0.7</priority> # </url> # ) if entry['loc'].find('.xml')!=-1 or entry['loc'].find('mddid')==-1: # print("entry", entry) yield entry def parse_shop(self,response): # get response from detail web url page(not sitemap loc) # eg: http://www.mafengwo.cn/v100292 (html) if response.status==200: item={} item['title']=response.css('.t1').xpath('string(.)').get() # 使用split()去除`\xa0`,即` `(编码原因变成了`\xa0`字符,`strip()`和`replace()`均无法有效去除该字符) intro="".join(response.css('.address p').xpath('string(.)').getall()).split() item['introduce']=" ".join(intro) return itemexecute
scrapy crawl siteUpdate -o mafengwo.jl -s FEED_EXPORT_ENCODING=utf-8
Note:
- 属性:
sitemap_urls = (): 可以指向robots.txt(会从中提取Sitemap网址)/sitemap网址sitemap_rules = [('', 'parse')]: A list of tuples(regex, callback),regex用来匹配Sitemap中列出的网址sitemap_follow = ['']:适用于SitemapIndex文件,符合这里设置的regex的sitemap会深入抓取(默认'',即都会)sitemap_alternate_links = False:是否url使用列出的备用链接
- 方法:
start_requests(self): or usesitemap_urlssitemap_filter(self,entries): entries get from the response body- if
sitemapindex& matchsite_follow: yieldRequestforsitemap - if
urlset& matchsite_rules: yieldRequestfor web page => callback func:parse=> yieldItem/Request
Item
- 属性:
- fields={}
- 方法:
- copy(item)
- keys()
- values()
- items()
- pop(key)
- clear()
- get(key,default)
- setdefault(key,default)
- update(...)
- popitem(...)
Sample:
自定义一个Item类:
import scrapy class Product(scrapy.Item): # `class Field(dict)`,即dict的一个封装容器 name = scrapy.Field() price = scrapy.Field() stock = scrapy.Field() last_updated = scrapy.Field(serializer=str)常用方法:
# 1. Create item >>> product = Product({'name': 'Laptop PC', 'price': 1500}) # Product(name='Laptop PC', price=1500) >>> product = Product({'name': 'Laptop PC', 'lala': 1500}) # KeyError: 'Product does not support field: lala' >>> product = Product(name='Desktop PC', price=1000) # Product(name='Desktop PC', price=1000) # Create Item from Item >>> product2 = Product(product) # Product(name='Desktop PC', price=1000) >>> product3 = product2.copy() # Product(name='Desktop PC', price=1000) # Creating dicts from items >>> dict(product) # create a dict from all populated values {'price': 1000, 'name': 'Desktop PC'} # 2. Get field values >>> product['name'] Desktop PC >>> product.get('name') Desktop PC >>> product['last_updated'] Traceback (most recent call last): ... KeyError: 'last_updated' >>> product.get('last_updated', 'not set') not set # 3. Set field value >>> product['name'] = 'IPad' >>> product['name'] IPad >>> product['lala'] = 'test' # setting unknown field Traceback (most recent call last): ... KeyError: 'Product does not support field: lala' # 4. Access all populated values >>> product.keys() ['price', 'name'] >>> product.values() ["1000","IPad"] >>> product.items() [('price', 1000), ('name', 'IPad')] # 5. Check if has value >>> 'name' in product # is name field populated? True >>> 'last_updated' in product # is last_updated populated? False # 6. Check if has field >>> 'last_updated' in product.fields # is last_updated a declared field? True >>> 'lala' in product.fields # is lala a declared field? False
ItemLoader
Refer Item Loaders
方便对数据进行格式化,填充Item(字段赋值) (Item提供保存抓取到数据的容器,Itemloader提供的是填充容器的机制)
Sample1:
Item:
class MovieItem(scrapy.Item): id = scrapy.Field() title = scrapy.Field() rate = scrapy.Field() url = scrapy.Field() cover = scrapy.Field() playable = scrapy.Field() crawl_date = scrapy.Field()Spider parse:
# -*- coding: utf-8 -*- import scrapy from douban.items import MovieItem from scrapy.loader import ItemLoader from scrapy.loader.processors import TakeFirst, MapCompose, Join import datetime class HotMovieSpider(scrapy.Spider): name = 'hotMovie' allowed_domains = ['movie.douban.com'] start_urls = ['http://movie.douban.com/'] def parse(self, response): # loader=ItemLoader(item=MovieItem(),response=response) movieSelectors = response.xpath("//*[@id='screening']//li[@data-title]") for s in movieSelectors: loader = ItemLoader(item=MovieItem(), selector=s) loader.add_css('title', '::attr(data-title)', TakeFirst(), MapCompose(str.strip)) loader.add_xpath('rate', './@data-rate', TakeFirst()) loader.add_xpath('url', ".//li[@class='poster']/a/@href", TakeFirst()) loader.add_xpath('cover', ".//li[@class='poster']//img/@src", TakeFirst()) loader.add_css('id', "::attr(data-trailer)", TakeFirst(), re=r'\d+') loader.add_value('crawl_date', datetime.datetime.now()) yield loader.load_item()excute
scrapy crawl hotMovie -o movie.jl, yield item sample:# 注:提取数据时不管使用何种processors,都是列表形式填充到Item { "title": ["蜘蛛侠:英雄远征 Spider-Man: Far From Home"], "rate": ["8.0"], "url": ["https://movie.douban.com/subject/26931786/?from=showing"], "cover": ["https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2558293106.jpg"], "id": ["26931786"], "crawl_date": ["2019-06-30 11:43:19"] }字段值去除列表形式,eg:
# 注:提取数据时不管使用何种processors,都是列表形式填充到Item { "title": "蜘蛛侠:英雄远征 Spider-Man: Far From Home", "rate": "8.0"], "url": "https://movie.douban.com/subject/26931786/?from=showing", "cover": "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2558293106.jpg", "id": "26931786", "crawl_date": "2019-06-30 11:43:19" }方式一:修改
ItemLoader的default_output_processor为Join()(或其他处理List的processor)def parse(self,response): # ... # loader.add_value('crawl_date', datetime.datetime.now()) loader.add_value('crawl_date', str(datetime.datetime.now())) # Join() only used for str List loader.default_output_processor = Join() # add for convert field value List to String yield loader.load_item()- 方式二:配置
Item的Field(output_processor=xxxx)(优先级高于ItemLoader中的default)from scrapy.loader.processors import Join class MovieItem(scrapy.Item): # ... title = scrapy.Field(output_processor=Join())
Note:
- 属性:
itemselectorcontextparentdefault_item_class = Itemdefault_input_processor = Identity()default_output_processor = Identity()default_selector_class = Selector
- 方法:
__init__(self, item=None, selector=None, response=None, parent=None, **context)add_value/replace_value(field_name,value,*processors,**kw),get_value(value, *processors, **kw)add_xpath/replace_xpath(field_name, xpath, *processors, **kw),get_xpath(xpath, *processors, **kw)add_css/replace_css(field_name, css, *processors, **kw),get_css(css, *processors, **kw)nested_xpath(xpath,**context),nested_css(css,**context)get_input_processor/get_output_processor(field_name)get_output_value/get_collected_values(field_name)load_item()
processors:
- 内置的processor
Identity: 不进行任何处理,直接返回原来的数据TakeFirst: 返回第一个非空值Join: 返回用分隔符连接后的值(默认是使用空格连接)Compose: 返回多个函数组合处理后的数据(默认遇到None值时停止处理,可传入stop_on_none = False修改)MapCompose:与Compose类似,只是输入值是被迭代的处理传入各个函数SelectJmes:使用jsonpath,返回json对象某个field值(Requiresjmespath)
- 可直接使用内置的processors,也可使用自定义
在
Compose/MapCompose中的函数也可使用lambda表达式,更简便>>> from scrapy.loader.processors import MapCompose >>> def filter_world(x): ... return None if x == 'world' else x >>> proc = MapCompose(filter_world, str.upper) >>> proc(['hello', 'world', 'this', 'is', 'scrapy']) >>> ['HELLO', 'THIS', 'IS', 'SCRAPY'] >>> proc2 = MapCompose(lambda i : i.replace('=',':'),str.strip) >>> proc2(['a=1',' b = Tom ','c:OK']) ['a:1', 'b : Tom', 'c:OK']- 使用:
- ItemLoader
add/replace/get_value/xpath/css(...)提取数据时传入 - ItemLoader
default_input/output_processor配置 - Item Field
input/output_processor配置
- ItemLoader
- 内置的processor
- 步骤:
add_value/add_xpath/add_css(...)提取数据- 可传入processors处理提取的数据
- 可传入参数
re='regex'正则表达式来过滤匹配值 - 默认提取的数据,填充进去的对象都是List类型(即每个字段存储的都是List类型)
- =>
input_processor&output_processor数据预处理(填充到Item的Field前的处理)- 优先使用Item对象的Field字段配置的
input/output_processor,未配置则使用ItemLoader中的default_input/output_processor - Item Loader中的
default_input/output_processor默认都是Identity,即维持原样,不处理
- 优先使用Item对象的Field字段配置的
- =>
load_item()填充到Item对象
Middleware
MiddlewareManager:- 方法:
- from_settings(cls, settings, crawler=None)
- from_crawler(cls, crawler)
- open_spider(self, spider)
- close_spider(self, spider)
- 子类:
ItemPipelineManager: item pipeline- process_item(self, item, spider)
SpiderMiddlewareManager: spider middleware- scrape_response(self, scrape_func, response, request, spider)
- process_spider_input(response)
- process_spider_exception(_failure)
- process_spider_output(result)
- process_start_requests(self, start_requests, spider)
- scrape_response(self, scrape_func, response, request, spider)
DownloaderMiddlewareManager: downloader middleware- download(self, download_func, request, spider)
- process_request(request)
- process_response(response)
- process_exception(_failure)
- Note: @defer.inlineCallbacks
- download(self, download_func, request, spider)
ExtensionManager: extension
- 方法:
Project Middleware:
- ItemPipeline:
pipelines.pyopen_spider(self, spider)process_item(self, item, spider)close_spider(self, spider)
- SpiderMiddleware:
middleware.pyspider_opened(self, spider)process_start_requests(self, start_requests, spider)- yied Request (no items)
process_spider_input(self, response, spider)- return None
- or raise Exception
process_spider_output(self, response, result, spider)- yield Request/Item
process_spider_exception(self, response, exception, spider)
- DownloaderMiddleware:
middleware.py- spider_opened(self, spider)
- process_request(self, request, spider):
- return None(continue processing)/Response/Request
- or raise IgnoreRequest => call downloader middleware
process_exception()
- process_response(self, request, response, spider)
- return Response/Request
- or raise IgnoreRequest
- process_exception(self, request, exception, spider)
- return None/Response/Request
- Note: return None will continue processing this exception, return Response/Request stops process_exception() chain
- ItemPipeline:
scrapy/settings/default_settings.py:ITEM_PIPELINES_BASE = {} SPIDER_MIDDLEWARES_BASE = { # Engine side 'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50, 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500, 'scrapy.spidermiddlewares.referer.RefererMiddleware': 700, 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800, 'scrapy.spidermiddlewares.depth.DepthMiddleware': 900, # Spider side } DOWNLOADER_MIDDLEWARES_BASE = { # Engine side 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300, 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350, 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400, 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500, 'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550, 'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560, 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590, 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600, 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700, 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750, 'scrapy.downloadermiddlewares.stats.DownloaderStats': 850, 'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900, # Downloader side } EXTENSIONS_BASE = { 'scrapy.extensions.corestats.CoreStats': 0, 'scrapy.extensions.telnet.TelnetConsole': 0, 'scrapy.extensions.memusage.MemoryUsage': 0, 'scrapy.extensions.memdebug.MemoryDebugger': 0, 'scrapy.extensions.closespider.CloseSpider': 0, 'scrapy.extensions.feedexport.FeedExporter': 0, 'scrapy.extensions.logstats.LogStats': 0, 'scrapy.extensions.spiderstate.SpiderState': 0, 'scrapy.extensions.throttle.AutoThrottle': 0, }project
settings.py:ITEM_PIPELINES = { #'douban.pipelines.DoubanPipeline': 300, } SPIDER_MIDDLEWARES = { #'douban.middlewares.DoubanSpiderMiddleware': 543, } DOWNLOADER_MIDDLEWARES = { #'douban.middlewares.DoubanDownloaderMiddleware': 543, } EXTENSIONS = { #'scrapy.extensions.telnet.TelnetConsole': None, }
Item Pipeline
- project下pipeline.py文件
- 不需要继承特定的基类,只需要实现特定的方法:
open_spider:爬虫运行前执行的操作process_item:爬虫获取到的每项item数据的处理方法close_spider:爬虫运行结束时执行的操作from_crawler:pipeline类方法,是创建item pipeline的回调方法,通常该方法用于读取setting中的配置参数- 注:其中
process_item必须实现
Sample:
Duplicates filter
from scrapy.exceptions import DropItem class DuplicatesPipeline(object): def __init__(self): self.ids_seen = set() def process_item(self, item, spider): if item['id'] in self.ids_seen: raise DropItem("Duplicate item found: %s" % item) else: self.ids_seen.add(item['id']) return itemTake screenshot of item
# 从方法返回Deferred process_item() # Pipeline请求本地运行的Splash实例,获取项目网址的屏幕截图 # 在Deferred回调函数中保存截图,yield Item import scrapy import hashlib from urllib.parse import quote class ScreenshotPipeline(object): """Pipeline that uses Splash to render screenshot of every Scrapy item.""" SPLASH_URL = "http://localhost:8050/render.png?url={}" def process_item(self, item, spider): encoded_item_url = quote(item["url"]) screenshot_url = self.SPLASH_URL.format(encoded_item_url) request = scrapy.Request(screenshot_url) dfd = spider.crawler.engine.download(request, spider) dfd.addBoth(self.return_item, item) return dfd def return_item(self, response, item): if response.status != 200: # Error happened, return item. return item # Save screenshot to file, filename will be hash of url. url = item["url"] url_hash = hashlib.md5(url.encode("utf8")).hexdigest() filename = "{}.png".format(url_hash) with open(filename, "wb") as f: f.write(response.body) # Store filename in item. item["screenshot_filename"] = filename return itemWrite items to file
class ItemFilePipeline(object): def __init__(self): self.filepath=settings['ITEM_STORE'] def open_spider(self,spider): filename=os.path.join(self.filepath,spider.name+'.json') self.file=open(filename,'w',encoding='utf-8') self.file.write('[\n') def process_item(self,item,spider): #print(item) record=json.dumps(dict(item),ensure_ascii=False) #print(record) self.file.write(record+",\n") return item def close_spider(self,spider): self.file.write(']\n') self.file.close()Write items to MongoDB
class MongoPipeline(object): def __init__(self): self.mongo_uri=settings['MONGO_CONN_STR'] self.mongo_db=settings.get('MONGO_DB','scrapy') def process_item(self, item, spider): record=dict(item) record['_id']=record['id'] record.pop('id') result=self.db[spider.name].update_one({'_id':record['_id']},{'$set':record},upsert=True) # print(result.raw_result) return item def open_spider(self,spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] #print(self.client.list_database_names()) #print(self.db.list_collection_names()) def close_spider(self,spider): self.client.close()
Media Pipeline
FilesPipeline(继承自MediaPipeline)
DEFAULT_FILES_URLS_FIELD = 'file_urls'- 默认从Item的
file_urls=[](在Spider中抓取填充该字段)获取文件的URLs,下载文件 - 可在settings配置
FILES_URLS_FIELD另外指定 - 也可在
get_media_requests(...)中动态修改
- 默认从Item的
DEFAULT_FILES_RESULT_FIELD='files'- 默认将下载的文件信息存储到Item的
files={}字段,包括url,path,checksum - 可在settings配置
FILES_RESULT_FIELD另外指定 - 也可在
item_completed(...)中动态修改
- 默认将下载的文件信息存储到Item的
EXPIRES=90- 文件多少天后过期(避免重复下载最近的文件), 默认设置为90天后文件过期
- 可在settings配置
FILES_EXPIRES另外指定
- settings中配置:
FILES_STORE指定文件存储位置文件系统(或者亚马逊S3)- 文件存储:
<FILES_STORE>/file_path(...)
- 文件存储:
- Overridable methods:
get_media_requests(self, item, info)- return Request (get from file_urls field)
file_downloaded(self, response, request, info)- persist_file
- return checksum
item_completed(self, results, item, info)- store the files information which downloaded successfully into Item field
- return item
- eg:
# results=(True, {dict}: [(True, {'checksum': '2b00042f7481c7b056c4b410d28f33cf', 'path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg', 'url': 'http://www.example.com/files/product1.pdf'}), (False, Failure(...))] # store the successful files information to Item files field # item['files']: [{'checksum': '2b00042f7481c7b056c4b410d28f33cf', 'path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg', 'url': 'http://www.example.com/files/product1.pdf'}]
file_path(self, request, response=None, info=None)- return path
'full/%s%s' % (media_guid, media_ext)- eg:
full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg
ImagesPipeline(继承自FilesPipeline)
DEFAULT_IMAGES_URLS_FIELD='image_urls'- 默认从Item的
image_urls=[](在Spider中抓取填充该字段)获取Image的URLs,下载Image - 可在settings配置
IMAGES_URLS_FIELD另外指定
- 默认从Item的
DEFAULT_IMAGES_RESULT_FIELD = 'images'- 默认将下载的文件信息存储到Item的
images={}字段,包括url,path,checksum - 可在settings配置
IMAGES_RESULT_FIELD另外指定
- 默认将下载的文件信息存储到Item的
EXPIRES = 90- 文件多少天后过期(避免重复下载最近的文件), 默认设置为90天后文件过期
- 可在settings配置
IMAGES_EXPIRES另外指定
MIN_WIDTH = 0,MIN_HEIGHT = 0- Filtering out small images 只下载大于某长宽的图片
- settings:
IMAGES_MIN_WIDTH,IMAGES_MIN_HEIGHT
THUMBS = {}- 配置缩略图,默认无
- 可在settings中配置
IMAGES_THUMBS={size_name:(x,y),...}另外指定,eg:IMAGES_THUMBS = { 'small': (50, 50), 'big': (270, 270), } # 则下载的Images存储路径为(checksum相同): # <IMAGES_STORE>/full/63bbfea82b8880ed33cdb762aa11fab722a90a24.jpg # <IMAGES_STORE>/thumbs/small/63bbfea82b8880ed33cdb762aa11fab722a90a24.jpg # <IMAGES_STORE>/thumbs/big/63bbfea82b8880ed33cdb762aa11fab722a90a24.jpg
- settings中配置:
IMAGES_STORE- Image 原图存储:
<IMAGES_STORE>/file_path(...) - Image 缩略图存储:
<IMAGES_STORE>/thumb_path(...)
- Image 原图存储:
- methods:
- convert_image(self, image, size=None)
- 将图片转换成常见格式(JPG)和模式(RGB)
- 修正Image大小(生成缩略图)
- get_images(self, response, request, info)
- 调用convert_image转换image
- yield path, image, buf (若配置了thumbs,也会yield对应转换后的images)
- get_media_requests(self, item, info)
- 同FilesPipeline
- file_downloaded/image_downloaded(self, response, request, info)
- 同FilesPipeline
- item_completed(self, results, item, info)
- 同FilesPipeline
- file_path(self, request, response=None, info=None)
- return path
'full/%s.jpg' % (image_guid)
- thumb_path(self, request, thumb_id, response=None, info=None)
- return
'thumbs/%s/%s.jpg' % (thumb_id, thumb_guid)
- return
- convert_image(self, image, size=None)
Note: 生效需要settings中配置
ITEM_PIPELINES = { ... }
Sample : Douban Top 250 Item and Cover(image) download
- Store items to file
Download item's cover (image)
item.py
class CoverItem(scrapy.Item): name=scrapy.Field() url=scrapy.Field() path=scrapy.Field() #images=scrapy.Field() checksum=scrapy.Field()spider/cover.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from douban_demo.items import CoverItem from scrapy.exceptions import DropItem class CoverSpider(CrawlSpider): name = 'cover' allowed_domains = ['movie.douban.com'] start_urls = ['https://movie.douban.com/top250/'] rules = ( Rule(LinkExtractor(allow=r'\?start=\d+.*',restrict_xpaths='//div[@class="paginator"]'), callback='parse_item', follow=True), ) def parse_item(self, response): print(response.url) records=response.xpath('//ol[@class="grid_view"]//div[@class="item"]/div[@class="pic"]//img') for r in records: item=CoverItem() item['name']=r.xpath('./@alt').get() item['url']=r.xpath('./@src').get() print(item['url']) yield itempipeline.py
import scrapy from scrapy.pipelines.images import ImagesPipeline class CoverImagePipeline(ImagesPipeline): def get_media_requests(self,item,info): ext=item['url'].split('.')[-1] yield scrapy.Request(item['url'],meta={'image_name':item['name']+"."+ext}) def item_completed(self,results, item, info): #item['images']=results r = [(x['path'],x['checksum']) for ok, x in results if ok] if not r: raise DropItem("Item contains no images") item['path'] = r[0][0] item['checksum']=r[0][1] return item def file_path(self,request,response=None,info=None): return 'full/%s' % request.meta['image_name'] class CoverItemPipeline(object): def __init__(self): self.filepath=settings['COVER_FILE'] def open_spider(self,spider): self.file=open(self.filepath,'w',encoding='utf-8') def process_item(self,item,spider): #print(item) record=json.dumps(dict(item),ensure_ascii=False) #print(record) self.file.write(record+"\n") return item def close_spider(self,spider): self.file.close()setting.py
COVER_FILE='D:\Space\python\images\cover.txt' ITEM_PIPELINES = { #'douban_demo.pipelines.DoubanDemoPipeline': 300, 'douban_demo.pipelines.CoverImagePipeline':310, 'douban_demo.pipelines.CoverItemPipeline':320 } IMAGES_STORE='D:\Space\python\images' IMAGES_EXPIRES = 30 IMAGES_THUMBS = { 'small': (50, 50), 'big': (250, 250), }run.py
from scrapy import cmdline cmdline.execute("scrapy crawl cover -s LOG_ENABLED=False".split()) #from scrapy.cmdline import execute #execute(['scrapy', 'crawl', 'cover'])execute
scrapy crawl cover # or execute the run.py: # python runsample item:
{ "_id" : "1900841", "quote" : "别样人生。", "rate" : "9.1", "title" : "窃听风暴", "cover" : { "name" : "窃听风暴", "url" : "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p1808872109.jpg", "path" : "full/窃听风暴.jpg", "checksum" : "c7ac16a9361d57718543ccea182543a9" } }
Item Exporters
数据导出器(Exporter):
scrapy内置了6中数据导出格式:
json,json lines,CSV,xml,pickle,marshalFEED_EXPORTERS = {} FEED_EXPORTERS_BASE = { 'json': 'scrapy.exporters.JsonItemExporter', 'jsonlines': 'scrapy.exporters.JsonLinesItemExporter', 'jl': 'scrapy.exporters.JsonLinesItemExporter', 'csv': 'scrapy.exporters.CsvItemExporter', 'xml': 'scrapy.exporters.XmlItemExporter', 'pickle': 'scrapy.exporters.PickleItemExporter', 'marshal': 'scrapy.exporters.MarshalItemExporter', }其他相关配置
FEED_TEMPDIR = None FEED_URI = None # 导出文件路径,eg: 'export_data\%(name)s.data'(name自动替换成spider的name) FEED_URI_PARAMS = None # a function to extend uri arguments FEED_FORMAT = 'jsonlines' # 导出文件的格式,即默认导出器类型,eg: 'csv' FEED_STORE_EMPTY = False FEED_EXPORT_ENCODING = None # 导出文件的编码格式 FEED_EXPORT_FIELDS = None # 默认导出全部字段,对字段进行排序,eg ['name','author','price'] FEED_STORAGES = {} FEED_STORAGES_BASE = { '': 'scrapy.extensions.feedexport.FileFeedStorage', 'file': 'scrapy.extensions.feedexport.FileFeedStorage', 'stdout': 'scrapy.extensions.feedexport.StdoutFeedStorage', 's3': 'scrapy.extensions.feedexport.S3FeedStorage', 'ftp': 'scrapy.extensions.feedexport.FTPFeedStorage', } FEED_EXPORT_INDENT = 0基类:
BaseItemExporterserialize_field(self, field, name, value)start_exporting(self):导出开始时被调用,用于初始化(类似pipelines的open_spider)export_item(self, item):用于处理每项数据(类似pipelines的process_item),必须实现(默认raise NotImplementedError)finish_exporting(self):导出完成后调用,用于收尾工作(类似pipelines的close_spider)
子类:
- JsonLinesItemExporter
- JsonItemExporter
- XmlItemExporter
- CsvItemExporter
- PickleItemExporter
- MarshalItemExporter
- PprintItemExporter
- PythonItemExporter
- JsonItemExporter Vs. JsonLinesItemExporter
- JsonItemExporter: 每次把数据添加到内存中,最后统一写入到磁盘文件中(耗内存),整个文件(
.json):[{},{},...] - JsonLinesItemExporter:每次调用export_item的时候就把item存储到磁盘中(即一个字典一行,不耗内存),整个文件(
.jl):{},{}...(不是一个满足json格式的文件)
- JsonItemExporter: 每次把数据添加到内存中,最后统一写入到磁盘文件中(耗内存),整个文件(
- 过程:
- 运行爬虫(
scrapy crawl)时指定-o filepath导出到文件,则会使用Exporter - 导出器类型:根据保存文件后缀确定,若指定
-t format,则使用指定的 - 确定导出器类型后,再从settings中查找对应导出器进行导出
- eg:
$ scrapy crawl movie -o text.json $ scrapy crawl movie -t json -o test.json
- 运行爬虫(
应用
基于Excel爬取
# -*- coding: utf-8 -*-
import scrapy
import csv
from scrapy.item import Item, Field
from scrapy.loader import ItemLoader
from scrapy.loader.processors import Identity, Join, MapCompose
import datetime
class MoviecsvSpider(scrapy.Spider):
name = 'movieCsv'
allowed_domains = ['movie.douban.com']
# start_urls = ['http://movie.douban.com/']
def start_requests(self):
with open("movie.csv", 'rU') as f:
reader = csv.DictReader(f)
for line in reader:
print(line)
# OrderedDict([('src_url', 'http://movie.douban.com/'),
# ('src_selector', '#screening li[data-title]'),
# ('title', '::attr(data-title)'),
# ('rate', '::attr(data-rate)'),
# ('url', 'li.poster>a::attr(href)'),
# ('cover', 'li.poster img::attr(src)'),
# ('id', '::attr(data-trailer)')]
yield scrapy.Request(url=line.pop('src_url'), callback=self.parse, meta={'rule': line})
def parse(self, response):
line = response.meta['rule']
src_selector = response.css(line.pop('src_selector'))
for s in src_selector:
item = Item()
loader = ItemLoader(item=item, selector=s)
for name, exp in line.items():
if exp:
item.fields[name] = Field()
loader.add_css(name, exp)
item.fields['crawl_date'] = Field() # Field(output_processor=Identity())
loader.add_value('crawl_date', datetime.datetime.now(), str)
loader.default_output_processor = Join()
yield loader.load_item()
$ cat movie.csv
src_url,src_selector,title,rate,url,cover,id
http://movie.douban.com/,#screening li[data-title],::attr(data-title),::attr(data-rate),li.poster>a::attr(href),li.poster img::attr(src),::attr(data-trailer)
execute scrapy crawl movieCsv -o movie.jl, result sample:
{
"title": "监护风云 Jusqu’à la Garde",
"rate": "7.3",
"url": "https://movie.douban.com/subject/26995532/?from=showing",
"cover": "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2560052923.jpg",
"id": "https://movie.douban.com/subject/26995532/trailer",
"crawl_date": "2019-06-30 16:21:15.310231"
}
Login
- Method1: spider start_requests: post form request to login first
- Method2: login in web page, then copy the cookie to settings
DEFAULT_REQUEST_HEADERS={'Cookie':'xx=xxx...'}
Sample: post form request to login in spider
class LessonSpider(scrapy.Spider):
name = 'lesson'
allowed_domains = ['class.121talk.cn']
start_urls=['https://class.121talk.cn/business/Index']
login_url='https://class.121talk.cn/business/Index/login'
course_url='https://class.121talk.cn/business/Teachers/detail/id/3313'
def __init__(self,username=None,password=None,*args, **kwargs):
super(LessonSpider, self).__init__(*args, **kwargs)
if username is None or password is None:
raise Exception('No username or password to login')
self.username=username
self.password=password
# login - method1:
def start_requests(self):
print('start_request')
yield scrapy.FormRequest(self.login_url
,formdata={'username':self.username,'password':self.password}
,callback=self.after_login)
# login - method2:
# def parse(self, response):
# yield scrapy.FormRequest.from_response(response
# ,url=self.login_url
# ,formdata={'username':self.username,'password':self.password}
# #,meta={'cookiejar':1}
# ,callback=self.after_login)
def after_login(self,response):
print('after_login')
print('login:',response)
print('login headers:',response.headers)
print('login cookie:',response.request.headers.getlist('Cookie'))
print('login Set-Cookie:',response.headers.getlist('Set-Cookie'))
result=json.loads(response.body)
print("login result:",result)
if result.get('status'):
yield scrapy.Request(self.course_url
#,meta={'cookiejar':response.meta['cookiejar']}
,callback=self.parse_course)
run:
$ scrapy crawl lesson -a username=xxxx -a password=xxx
常见问题
ImportError: No module named win32api.
pip install pypiwin32AttributeError: 'TelnetConsole' object has no attribute 'port'
set TELNETCONSOLE_PORT setting to None (instead of default [6023, 6073]). If that doesn't work and if you don't need the telnet console, simply disable the extension altogether with setting `TELNETCONSOLE_ENABLED=False`AttributeError: 'module' object has no attribute 'F_GETFD'
找到python3/Lib 中将fcntl.py改名成fcntl_ex.py再运行403 forbidden : https://www.jianshu.com/p/31c7426c0da8
# setting.py: set 'User-Agent' # method1: Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0' #'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', #'Accept-Language': 'en', } # method2: USER_AGENT='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0'proxy: https://blog.csdn.net/wuchenlhy/article/details/80683829
method1: middlewares.py:
# downloader middleware: class ProxyMiddleware(object): def process_request(self, request, spider): spider.logger.info('Set proxy.....') request.meta['proxy'] = "http://xxxxxxx" # setting.py: DOWNLOADER_MIDDLEWARES = { 'douban_demo.middlewares.ProxyMiddleware':100 # 'douban_demo.middlewares.DoubanDemoDownloaderMiddleware': 543, }- method2: spider/xxxx.py:
def start_requests(self): start_url="http://xxx" return [scrapy.Request(start_url,callback=self.parse,meta={'proxy':'http://xxx'})]
scrapy 爬虫使用FilesPipeline 下载 出现302
[scrapy] WARNING: File (code: 302): Error downloading file from 在settings文件中没有设置MEDIA_ALLOW_REDIRECTS参数的话,默认会将值赋值成False 如果在下载的过程中如果有重定向过程,将不再重定向settings文件中 设置 MEDIA_ALLOW_REDIRECTS =True
Scrapy-Redis
- 单机架构:本机Scheduler调度本机的一个Requests队列
- 分布式架构:各机Scheduler调度一个共享Requests队列
Scrapy-Redis:- 在Scrapy基础上,重新实现了Scrapy的Scheduler,Queue等组建,使用Redis维护共享队列
- 如果Requests队列为空,则会从第一个启动的爬虫的start_urls开始;不为空,则继续从队列中调度出Request进行爬取解析
- Refer Github Scrapy-Redis
- 安装:
pip install scrapy-redis
Sample1: use scrapy Spider
添加Scrapy-redis相关配置(settings.py)
# Start Scrapy-Redis Settings: SCHEDULER = "scrapy_redis.scheduler.Scheduler" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER_PERSIST = True #SCHEDULER_FLUSH_ON_START=False ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 300 } #REDIS_ITEMS_KEY = '%(spider)s:items' #REDIS_ITEMS_SERIALIZER = 'json.dumps' #REDIS_HOST = 'localhost' #REDIS_PORT = 6379 #REDIS_PARAMS = {} REDIS_URL = 'redis://root:123456@localhost:6379' REDIS_ENCODING = 'utf-8' #REDIS_START_URLS_KEY = '%(name)s:start_urls' #REDIS_START_URLS_AS_SET = False # End Srapy-Redis Settings!Spider:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from douban.items import Top250Item class Top250Spider(CrawlSpider): name = 'top250' allowed_domains = ['movie.douban.com'] start_urls = ['https://movie.douban.com/top250'] rules = ( Rule( LinkExtractor(allow=r'\?start=\d+.*', restrict_xpaths='//div[@class="paginator"]') , callback='parse_item', follow=True), ) def parse_item(self, response): print(response.url) records = response.xpath('//ol[@class="grid_view"]//div[@class="item"]') for r in records: infoPath = r.xpath('./div[@class="info"]') picPath = r.xpath('./div[@class="pic"]//img') item = Top250Item() link = infoPath.xpath('./div[@class="hd"]/a/@href').get() item['id'] = link.split('/')[-2] item['title'] = infoPath.xpath('./div[@class="hd"]/a/span[@class="title"]/text()').extract_first() item['rate'] = infoPath.xpath( './div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract_first() item['quote'] = infoPath.xpath('./div[@class="bd"]/p[@class="quote"]/span/text()').extract_first() item['cover'] = { 'name': picPath.xpath('./@alt').get() , 'url': picPath.xpath('./@src').get() } yield item执行
scrapy crawl top250查看Redis:
# 1. Processing redis:6379> keys * 1) "top250:requests" 2) "top250:items" 3) "top250:dupefilter" redis:6379> type top250:requests zset redis:6379> zrange top250:requests 0 -1 withscores 1) "\x80\x04\x95a\x01\x00\x00\x00\x00\x00\x00}\x94(\x8c\x03url\x94\x8c1https://movie.douban.com/top250?start=225&filter=\x94\x8c\bcallback\x94\x8c\x14_response_downloaded\x94\x8c\aerrback\x94N\x8c\x06method\x94\x8c\x03GET\x94\x8c\aheaders\x94}\x94C\aReferer\x94]\x94C\x1fhttps://movie.douban.com/top250\x94as\x8c\x04body\x94C\x00\x94\x8c\acookies\x94}\x94\x8c\x04meta\x94}\x94(\x8c\x04rule\x94K\x00\x8c\tlink_text\x94\x8c\nlxml.etree\x94\x8c\x15_ElementUnicodeResult\x94\x93\x94\x8c\x0210\x94\x85\x94\x81\x94\x8c\x05depth\x94K\x01u\x8c\t_encoding\x94\x8c\x05utf-8\x94\x8c\bpriority\x94K\x00\x8c\x0bdont_filter\x94\x89\x8c\x05flags\x94]\x94u." 2) "0" 3) "\x80\x04\x95u\x01\x00\x00\x00\x00\x00\x00}\x94(\x8c\x03url\x94\x8c/https://movie.douban.com/top250?start=0&filter=\x94\x8c\bcallback\x94\x8c\x14_response_downloaded\x94\x8c\aerrback\x94N\x8c\x06method\x94\x8c\x03GET\x94\x8c\aheaders\x94}\x94C\aReferer\x94]\x94C0https://movie.douban.com/top250?start=25&filter=\x94as\x8c\x04body\x94C\x00\x94\x8c\acookies\x94}\x94\x8c\x04meta\x94}\x94(\x8c\x04rule\x94K\x00\x8c\tlink_text\x94\x8c\nlxml.etree\x94\x8c\x15_ElementUnicodeResult\x94\x93\x94\x8c\a<\xe5\x89\x8d\xe9\xa1\xb5\x94\x85\x94\x81\x94\x8c\x05depth\x94K\x02u\x8c\t_encoding\x94\x8c\x05utf-8\x94\x8c\bpriority\x94K\x00\x8c\x0bdont_filter\x94\x89\x8c\x05flags\x94]\x94u." 4) "0" # 2. Done redis:6379> keys * 1) "top250:items" 2) "top250:dupefilter" # 3. check requests footprinter (if set SCHEDULER_PERSIST=True): redis:6379> type top250:dupefilter set redis:6379> smembers top250:dupefilter 1) "a6d5976e3143b3d8445e1f70a9250e05a2147ba0" 2) "1eaddf9a0730560642a4d1b2eb7e90ec26ea9c0e" 3) "7efe48768f3d586dcef1245e877eda8c9377385b" 4) "368a5242083cc9dab290d77cbe6a81107c882290" 5) "a7db0795dad78984b0e6622ab7699b53358be585" 6) "c4f38f7d4635b51955cc4129dbbba9c33b202242" 7) "5153c8f0e792e26f62c13e110e7a8a522392f817" 8) "41432c2cf211502120954135e7a9eacc24d15a30" 9) "0a8d961c5cf075725ce493439e64ecef9797cea6" 10) "e8f772a1cff43b734c16f4298dff62dc2ba2cfc7" # 4. check items (if set scrapy_redis.pipelines.RedisPipeline): redis:6379> type top250:items list redis:6379> llen top250:items (integer) 250 lindex top250:items 0 "{\"id\": \"1851857\", \"title\": \"\\u8759\\u8760\\u4fa0\\uff1a\\u9ed1\\u6697\\u9a91\\u58eb\", \"rate\": \"9.1\", \"quote\": \"\\u65e0\\u5c3d\\u7684\\u9ed1\\u6697\\u3002\", \"cover\": {\"name\": \"\\u8759\\u8760\\u4fa0\\uff1a\\u9ed1\\u6697\\u9a91\\u58eb\", \"url\": \"https://img3.doubanio.com/view/photo/s_ratio_poster/public/p462657443.jpg\"}}"
Sample2: 动态start_urls
Spider: 使用RedisSpider或者RedisCrawlSpider
from scrapy_redis.spiders import RedisCrawlSpider class Top250Spider(CrawlSpider): name = 'top250' allowed_domains = ['movie.douban.com'] # start_urls -- no need # could get from Redis - set `redis_key='...'` # (default setting:`START_URLS_KEY='%(name)s:start_urls'`) # start_urls = ['https://movie.douban.com/top250'] rules = ( Rule( LinkExtractor(allow=r'\?start=\d+.*', restrict_xpaths='//div[@class="paginator"]') , callback='parse_item', follow=True), ) def parse_item(self, response): #....execute
scrapy crawl top250(it will keep running and waiting for the start_urls)- redis cli:
lpush key value插入start_urlsredis:6379> lpush top:start_urls https://movie.douban.com/top250 (integer) 1 redis:6379> keys * 1) "top:items" 2) "top:dupefilter" 3) "top:requests" redis:6379> keys * 1) "top:items" 2) "top:dupefilter"
Scrapyd (for Deploy)
- Scrapyd Doc
- 安装:
pip install scrapyd,check:scrapyd -h - 启动:
scrapyd,then could visit:http://127.0.0.1:6800/
deploy project
deploy tools: scrapyd-client
- 安装:
pip install scrapyd-client - 编辑项目的
scrapy.cfg文件的[deploy]部分:[deploy] url = http://localhost:6800/ project = douban - 执行打包上传:
scrapyd-deploy,then visithttp://localhost:6800/to check$ scrapyd-deploy Packing version 1562566994 Deploying to project "douban" in http://localhost:6800/addversion.json Server response (200): {"node_name": "cj-Pro.local", "status": "ok", "project": "douban", "version": "1562566994", "spiders": 6}
调用Scrapyd API(直接使用curl)
- status
$ curl http://localhost:6800/daemonstatus.json {"node_name": "cj-Pro.local", "status": "ok", "pending": 0, "running": 0, "finished": 0} list & delete
# 1.1 list projects $ curl http://localhost:6800/listprojects.json {"node_name": "cj-Pro.local", "status": "ok", "projects": ["douban", "default"]} # 1.2 list project versions $ curl http://localhost:6800/listversions.json?project=douban {"node_name": "cj-Pro.local", "status": "ok", "versions": ["1562566994", "1562567575"]} # 1.3 list spiders $ curl http://localhost:6800/listspiders.json?project=douban {"node_name": "cj-Pro.local", "status": "ok", "spiders": ["hotMovie", "movieCsv", "sinaRss", "siteUpdate", "top", "top250"]} # 1.4 list jobs $ curl http://localhost:6800/listjobs.json?project=douban {"node_name": "cj-Pro.local", "status": "ok", "pending": [], "running": [], "finished": []} $ curl http://localhost:6800/listjobs.json?project=douban | python -m json.tool % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 100 106 100 106 0 0 14239 0 --:--:-- --:--:-- --:--:-- 15142 { "finished": [], "node_name": "cj-Pro.local", "pending": [], "running": [], "status": "ok" } # 2.1 delete version $ curl http://localhost:6800/delversion.json -d project=douban -d version=1562567575 {"node_name": "cj-Pro.local", "status": "ok"} $ curl http://localhost:6800/listversions.json?project=douban {"node_name": "cj-Pro.local", "status": "ok", "versions": ["1562566994"]} # 2.2 delte project $ curl http://localhost:6800/delproject.json -d project=douban {"node_name": "cj-Pro.local", "status": "ok"} $ curl http://localhost:6800/listprojects.json {"node_name": "cj-Pro.local", "status": "ok", "projects": ["default"]}schedule & cancel job (run & stop spider)
# 1. schedule $ curl http://localhost:6800/schedule.json -d project=douban -d spider=top {"node_name": "cj-Pro.local", "status": "ok", "jobid": "73b3a61ca14d11e98c68f45c898fde83"} # 2. cancel $ curl http://localhost:6800/cancel.json -d project=douban -d job=73b3a61ca14d11e98c68f45c898fde83 {"node_name": "cj-Pro.local", "status": "ok", "prevstate": "running"} # 3. list $ curl http://localhost:6800/listjobs.json?project=douban | python -m json.tool % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 100 398 100 398 0 0 51883 0 --:--:-- --:--:-- --:--:-- 56857 { "finished": [ { "end_time": "2019-04-08 14:56:05.819583", "id": "73b3a61ca14d11e98c68f45c898fde83", "spider": "top", "start_time": "2019-04-08 14:56:04.831726" } ], "node_name": "cj-Pro.local", "pending": [], "running": [], "status": "ok" } # 4. log $ curl http://127.0.0.1:6800/logs/douban/top/73b3a61ca14d11e98c68f45c898fde83.log ....
调用Scrapyd API(使用python-scrapyd-api包)
- Refer Github
- 安装:
pip install python-scrapyd-api 使用:
>>> from scrapyd_api import ScrapydAPI >>> scrapyd = ScrapydAPI('http://localhost:6800') >>> scrapyd.endpoints {'add_version': '/addversion.json', 'cancel': '/cancel.json', 'delete_project': '/delproject.json', 'delete_version': '/delversion.json', 'list_jobs':'/listjobs.json', 'list_projects': '/listprojects.json', 'list_spiders': '/listspiders.json', 'list_versions': '/listversions.json', 'schedule': '/schedule.json'} # 1. list & delete >>> scrapyd.list_projects() # scrapyd.delete_project('project_name') -- return True/False ['douban', 'default'] >>> scrapyd.list_versions('douban') # scrapyd.delete_version('project_name') -- return True/False ['1562569685'] >>> scrapyd.list_spiders('douban') ['hotMovie', 'movieCsv', 'sinaRss', 'siteUpdate', 'top', 'top250'] >>> scrapyd.list_jobs('douban') { 'node_name': 'cj-Pro.local', 'pending': [], 'running': [], 'finished': [ {'id': 'db52e176a14c11e98c68f45c898fde83', 'spider': 'top', 'start_time': '2019-04-08 14:51:49.828399', 'end_time': '2019-04-08 14:51:50.803166'}, {'id': '73b3a61ca14d11e98c68f45c898fde83', 'spider': 'top', 'start_time': '2019-04-08 14:56:04.831726', 'end_time': '2019-04-08 14:56:05.819583'}, {'id': '33402590a14f11e98c68f45c898fde83', 'spider': 'top', 'start_time': '2019-04-08 15:08:34.827750', 'end_time': '2019-04-08 15:13:33.890973'} ] } # schedule & cancel >>> settings = {'DOWNLOAD_DELAY': 2} >>> scrapyd.schedule('douban', 'top', settings=settings) '3df6469ca15211e98c68f45c898fde83' >>> scrapyd.job_status('douban','3df6469ca15211e98c68f45c898fde83') 'running' >>> scrapyd.cancel('douban','3df6469ca15211e98c68f45c898fde83') 'running' >>> scrapyd.job_status('douban','3df6469ca15211e98c68f45c898fde83') 'finished'